Can LLMs Simulate Personas with Reversed Performance? A Benchmark for Counterfactual Instruction Following
作者: Sai Adith Senthil Kumar, Hao Yan, Saipavan Perepa, Murong Yue, Ziyu Yao
分类: cs.CL
发布日期: 2025-04-08 (更新: 2025-09-05)
💡 一句话要点
提出Counterfactual Instruction Following基准,评估LLM在逆向性能角色模拟中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 角色模拟 反事实指令遵循 基准数据集 数学推理
📋 核心要点
- 现有LLM在模拟角色时,难以模拟具有逆向性能的角色,限制了虚拟环境的应用。
- 论文提出Counterfactual Instruction Following基准,用于评估LLM在逆向性能角色模拟中的能力。
- 实验表明,包括OpenAI o1在内的LLM在反事实指令遵循方面表现不佳,交叉模拟会加剧问题。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用于模拟虚拟环境中的角色,这得益于它们强大的指令遵循能力。然而,我们发现即使是最先进的LLMs也无法模拟具有逆向性能的角色(例如,在教育环境中能力较低的学生角色),这损害了模拟的多样性并限制了模拟环境的实际应用。在这项工作中,我们以数学推理作为代表性场景,提出了第一个用于评估LLMs模拟逆向性能角色的基准数据集,我们将这种能力称为“Counterfactual Instruction Following”。我们评估了开源和闭源LLMs在这个任务上的表现,发现包括OpenAI o1推理模型在内的LLMs都难以遵循反事实指令来模拟逆向表现的角色。对角色的表现水平和种族人口进行交叉模拟会进一步加剧这种影响。这些结果突出了反事实指令遵循的挑战,以及进一步研究的必要性。
🔬 方法详解
问题定义:论文旨在解决LLM在模拟具有逆向性能(reversed performance)的角色时表现不佳的问题。现有方法,即直接使用指令让LLM扮演特定角色,在模拟能力较弱或表现不佳的角色时效果不理想。这限制了LLM在教育、心理学等领域的应用,因为这些领域需要模拟各种类型的个体。
核心思路:论文的核心思路是构建一个专门的基准数据集,用于评估LLM在“反事实指令遵循”(Counterfactual Instruction Following)方面的能力。通过设计特定的指令,要求LLM模拟与常识或其固有能力相反的角色,从而测试其是否能够真正理解并执行指令,而不是简单地基于其预训练知识进行回答。例如,要求LLM模拟一个数学能力很差的学生来解决数学问题。
技术框架:论文构建了一个名为Counterfactual Instruction Following的基准数据集,该数据集以数学推理为代表性场景。该数据集包含一系列数学问题,并针对每个问题设计了多个反事实指令,要求LLM模拟不同能力水平和种族背景的角色。评估过程包括:1)向LLM输入问题和反事实指令;2)记录LLM的回答;3)使用预定义的指标评估回答的质量和符合指令的程度。论文评估了多个开源和闭源LLM在该基准上的表现。
关键创新:论文最重要的创新点在于提出了“反事实指令遵循”这一概念,并构建了相应的基准数据集。这使得研究人员能够系统地评估LLM在模拟具有非典型特征或行为的角色时的能力。与以往的研究主要关注LLM的指令遵循能力不同,该论文关注的是LLM是否能够遵循与自身知识或能力相悖的指令。
关键设计:该基准数据集的关键设计在于反事实指令的设计。这些指令明确要求LLM模拟具有特定弱点或不足的角色,例如“假设你是一个数学很差的学生,请解决这个问题”。此外,该数据集还考虑了种族因素,通过交叉模拟不同种族和能力水平的角色,来评估LLM是否存在偏见或刻板印象。评估指标包括回答的正确率、与指令的符合程度以及回答的多样性。
🖼️ 关键图片

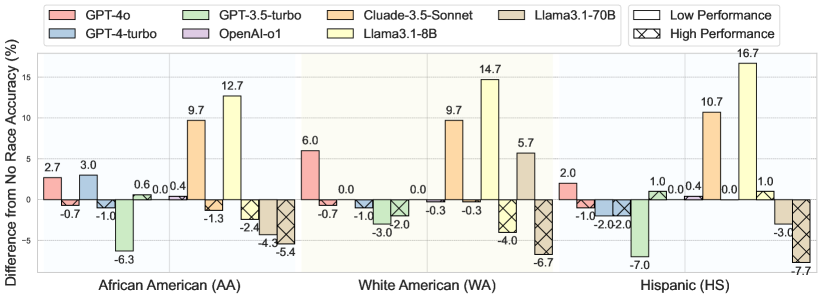
📊 实验亮点
实验结果表明,包括OpenAI o1在内的LLM在Counterfactual Instruction Following基准上的表现均不佳,无法有效模拟具有逆向性能的角色。交叉模拟种族和能力水平会进一步降低LLM的性能,表明LLM可能存在偏见或刻板印象。这些结果强调了LLM在反事实指令遵循方面的局限性,以及进一步研究的必要性。具体性能数据未知。
🎯 应用场景
该研究成果可应用于教育领域,例如创建个性化学习环境,模拟不同学习能力的学生,从而为教师提供更有效的教学策略。此外,还可应用于心理学研究,模拟不同性格特征的个体,用于研究人类行为和社会互动。在游戏和娱乐领域,可以创建更真实、更具挑战性的角色,提升用户体验。该研究有助于提高LLM在角色模拟方面的能力,使其在更广泛的领域得到应用。
📄 摘要(原文)
Large Language Models (LLMs) are now increasingly widely used to simulate personas in virtual environments, leveraging their instruction-following capability. However, we discovered that even state-of-the-art LLMs cannot simulate personas with reversed performance (e.g., student personas with low proficiency in educational settings), which impairs the simulation diversity and limits the practical applications of the simulated environments. In this work, using mathematical reasoning as a representative scenario, we propose the first benchmark dataset for evaluating LLMs on simulating personas with reversed performance, a capability that we dub "counterfactual instruction following". We evaluate both open-weight and closed-source LLMs on this task and find that LLMs, including the OpenAI o1 reasoning model, all struggle to follow counterfactual instructions for simulating reversedly performing personas. Intersectionally simulating both the performance level and the race population of a persona worsens the effect even further. These results highlight the challenges of counterfactual instruction following and the need for further research.