S'MoRE: Structural Mixture of Residual Experts for Parameter-Efficient LLM Fine-tuning
作者: Hanqing Zeng, Yinglong Xia, Zhuokai Zhao, Chuan Jiang, Qiang Zhang, Jiayi Liu, Qunshu Zhang, Lizhu Zhang, Xiangjun Fan, Benyu Zhang
分类: cs.CL, cs.LG
发布日期: 2025-04-08 (更新: 2025-10-29)
备注: NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出S'MoRE以解决大语言模型微调的参数效率与模型能力平衡问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 微调 专家混合模型 低秩适配 图神经网络 参数效率 模型能力 残差结构
📋 核心要点
- 现有的微调方法在参数效率与模型能力之间存在权衡,LoRA缺乏灵活性,而MoE则导致参数的浪费。
- S'MoRE通过层次低秩分解专家权重,结合残差结构和图神经网络,提升了模型的灵活性与效率。
- 实验结果显示,S'MoRE在微调性能上优于传统方法,提供了更高的适应性与效率。
📝 摘要(中文)
微调预训练的大语言模型(LLMs)面临着参数效率与模型能力之间的双重挑战。现有方法如低秩适配(LoRA)虽然高效,但缺乏灵活性;而专家混合模型(MoE)则在提升模型能力的同时,导致参数的过度使用和未充分利用。为了解决这些局限性,本文提出了一种新颖的框架——结构化残差专家混合模型(S'MoRE),它将LoRA的效率与MoE的灵活性无缝结合。S'MoRE通过专家权重的层次低秩分解,生成不同阶数的残差,并在多层结构中相互连接。通过将输入令牌路由到残差的子树中,S'MoRE通过实例化和组合少量低秩矩阵来模拟众多专家的能力。理论分析和实证结果表明,S'MoRE在相似参数预算下显著提升了传统MoE的结构灵活性,提供了一种高效的LLM适应新方法。
🔬 方法详解
问题定义:本文旨在解决大语言模型微调中参数效率与模型能力之间的平衡问题。现有方法如LoRA虽然高效,但灵活性不足;而MoE则在提升能力的同时,导致参数的过度使用和未充分利用。
核心思路:S'MoRE的核心思路是通过层次低秩分解专家权重,生成不同阶数的残差,并在多层结构中相互连接,从而在保持参数效率的同时提升模型的灵活性。
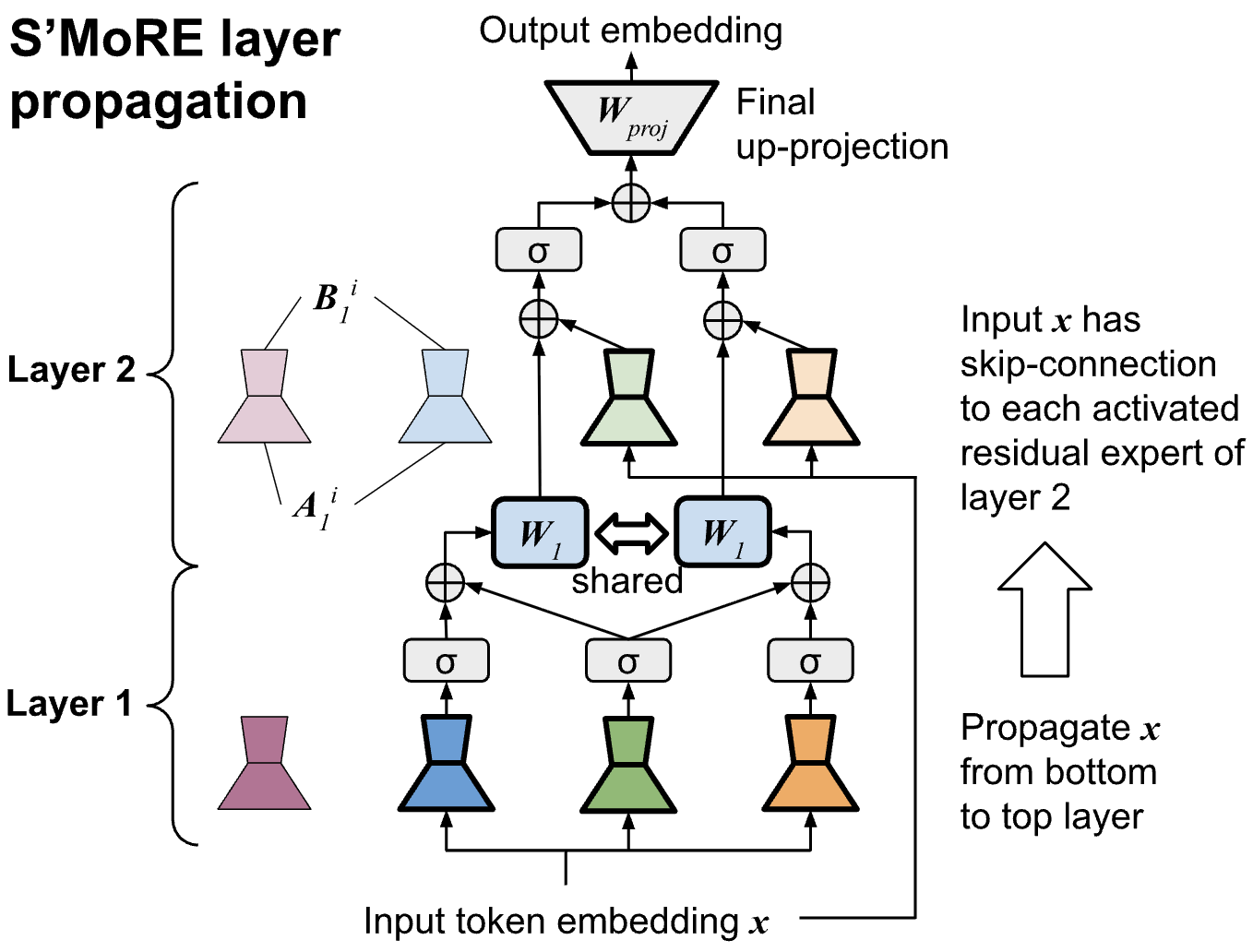
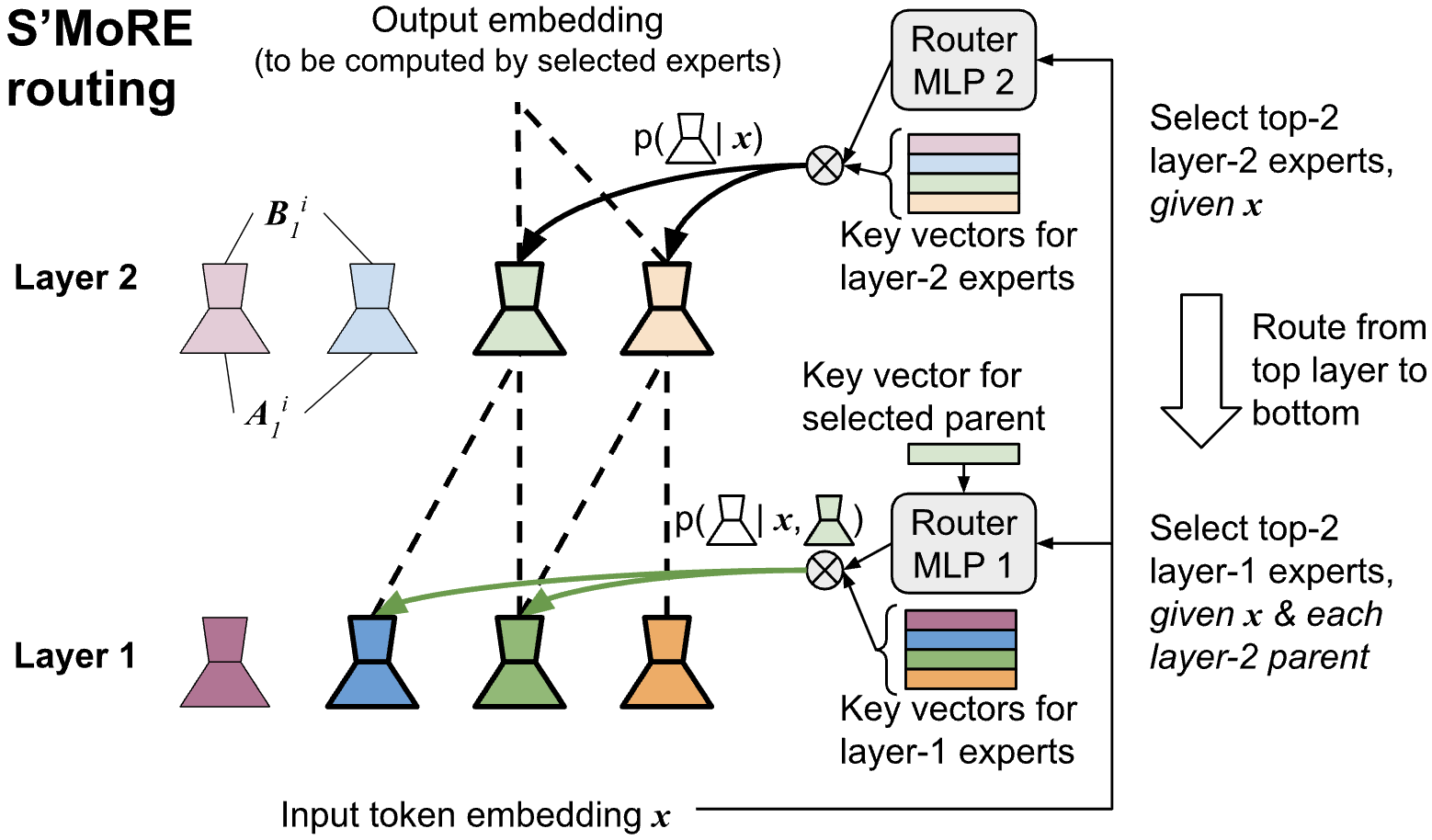
技术框架:S'MoRE的整体架构包括多个模块,首先进行专家权重的低秩分解,然后通过图神经网络(GNN)实现残差的跨层传播,最后通过路由机制将输入令牌分配到不同的残差子树中。
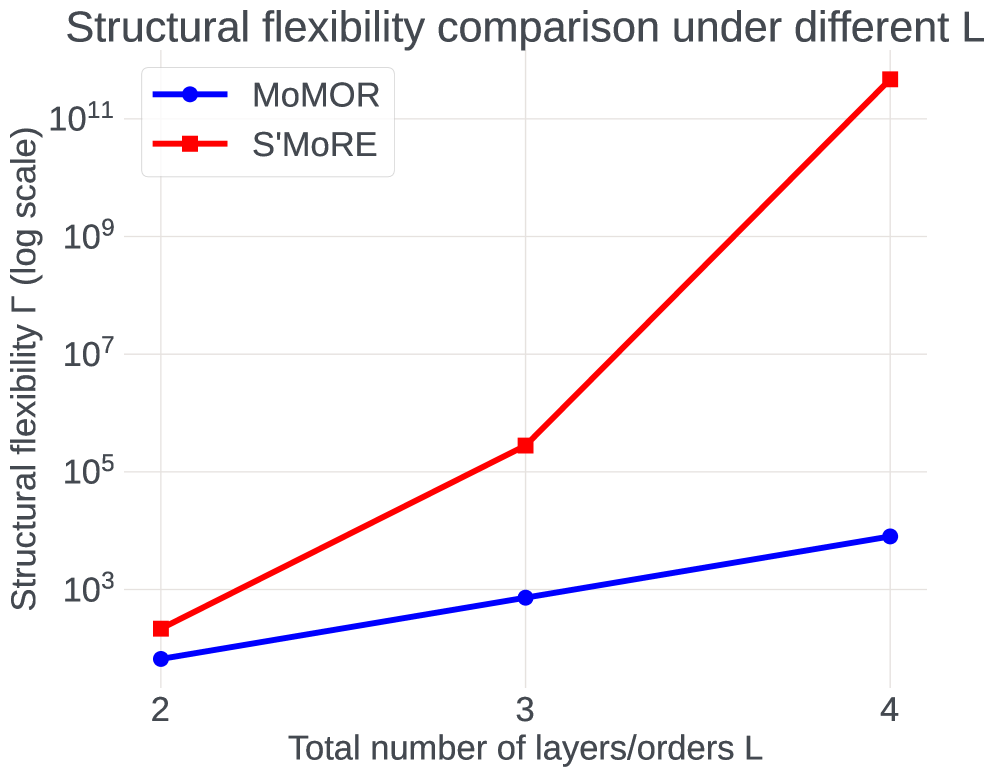
关键创新:S'MoRE的主要创新在于将残差专家的层次结构与图神经网络相结合,显著提升了传统MoE的结构灵活性,且在相似参数预算下实现了更优的性能。
关键设计:在设计中,S'MoRE采用了特定的低秩矩阵组合策略,损失函数的选择也经过精心设计,以确保模型在微调过程中的高效性与稳定性。具体的参数设置和网络结构细节在实验部分进行了详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,S'MoRE在相同参数预算下,相较于传统的MoE和LoRA方法,微调性能提升了显著的百分比,具体数据在论文中详细列出,展示了其在多个基准任务上的优越性。
🎯 应用场景
S'MoRE的研究成果在自然语言处理、对话系统和文本生成等领域具有广泛的应用潜力。通过提升大语言模型的微调效率,该方法能够加速模型在特定任务上的适应,降低计算资源的消耗,推动智能应用的普及与发展。
📄 摘要(原文)
Fine-tuning pre-trained large language models (LLMs) presents a dual challenge of balancing parameter efficiency and model capacity. Existing methods like low-rank adaptations (LoRA) are efficient but lack flexibility, while Mixture-of-Experts (MoE) enhance model capacity at the cost of more & under-utilized parameters. To address these limitations, we propose Structural Mixture of Residual Experts (S'MoRE), a novel framework that seamlessly integrates the efficiency of LoRA with the flexibility of MoE. Conceptually, S'MoRE employs hierarchical low-rank decomposition of expert weights, yielding residuals of varying orders interconnected in a multi-layer structure. By routing input tokens through sub-trees of residuals, S'MoRE emulates the capacity of numerous experts by instantiating and assembling just a few low-rank matrices. We craft the inter-layer propagation of S'MoRE's residuals as a special type of Graph Neural Network (GNN), and prove that under similar parameter budget, S'MoRE improves structural flexibility of traditional MoE (or Mixture-of-LoRA) by exponential order. Comprehensive theoretical analysis and empirical results demonstrate that S'MoRE achieves superior fine-tuning performance, offering a transformative approach for efficient LLM adaptation. Our implementation is available at: https://github.com/ZimpleX/SMoRE-LLM.