Leveraging Robust Optimization for LLM Alignment under Distribution Shifts
作者: Mingye Zhu, Yi Liu, Zheren Fu, Yongdong Zhang, Zhendong Mao
分类: cs.CL
发布日期: 2025-04-08 (更新: 2025-10-20)
备注: NeurIPS 2025
💡 一句话要点
提出基于鲁棒优化的LLM对齐框架,提升分布偏移下的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型对齐 分布偏移 鲁棒优化 偏好学习 合成数据 人类价值观 校准 最坏情况损失
📋 核心要点
- 现有LLM对齐方法依赖合成数据,易引入分布偏移,损害对人类偏好的准确建模。
- 论文提出分布感知的鲁棒优化框架,通过校准值和最坏情况损失最小化,缓解分布偏移。
- 该方法通过关注目标分布优化,提升了LLM生成符合人类价值观响应的能力。
📝 摘要(中文)
偏好对齐方法对于引导大型语言模型(LLM)生成符合人类价值观的输出至关重要。然而,为了可扩展性和成本效益,现有方法通常依赖于LLM生成的合成数据,这可能引入分布偏移,从而损害对人类偏好的细致表示,进而影响生成期望的输出。本文提出了一种新颖的分布感知优化框架,旨在改善此类偏移下的偏好对齐。该方法首先利用训练良好的分类器为每个训练样本分配一个校准值,量化其与目标人类偏好分布的对齐程度。然后,将这些值纳入鲁棒优化目标中,该目标旨在最小化与人类偏好最相关的数据空间区域中的最坏情况损失。通过显式地将优化重点放在目标分布上,该方法减轻了分布不匹配的影响,并改善了对预期价值观的响应生成。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)对齐方法,为了提高效率和降低成本,通常使用LLM自身生成的合成数据进行训练。然而,这种做法会导致训练数据与真实人类偏好数据之间存在分布偏移。这种分布偏移会使得LLM难以准确捕捉人类偏好的细微差别,从而影响生成符合人类价值观的输出。因此,如何减轻分布偏移对LLM对齐的影响是一个关键问题。
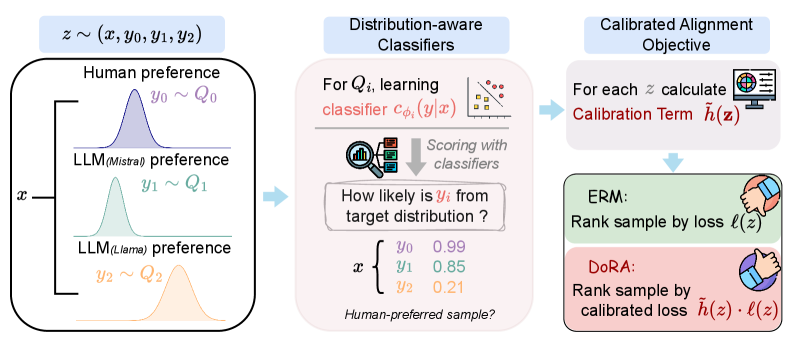
核心思路:论文的核心思路是采用鲁棒优化方法,显式地考虑训练数据中的分布偏移。具体来说,首先评估每个训练样本与目标人类偏好分布的对齐程度,并赋予其一个校准值。然后,在优化过程中,更加关注那些与人类偏好分布对齐程度较高的样本,同时最小化在这些样本上的最坏情况损失。通过这种方式,可以使LLM更加关注真实的人类偏好,从而减轻分布偏移带来的负面影响。
技术框架:该框架主要包含两个阶段:校准阶段和鲁棒优化阶段。在校准阶段,使用预先训练好的分类器来评估每个训练样本与目标人类偏好分布的对齐程度,并赋予其一个校准值。这个校准值反映了该样本代表真实人类偏好的可信度。在鲁棒优化阶段,将校准值纳入到优化目标中,构建一个鲁棒优化问题。该优化问题旨在最小化与人类偏好最相关的数据空间区域中的最坏情况损失。通过求解该鲁棒优化问题,可以得到一个对分布偏移具有鲁棒性的LLM。
关键创新:该论文的关键创新在于提出了一个分布感知的鲁棒优化框架,用于解决LLM对齐中的分布偏移问题。与现有方法不同,该方法显式地考虑了训练数据中的分布偏移,并通过校准值和鲁棒优化来减轻其影响。这种方法能够使LLM更加关注真实的人类偏好,从而提高生成符合人类价值观的输出的质量。
关键设计:校准值的计算依赖于预训练的分类器,该分类器需要能够准确区分合成数据和真实的人类偏好数据。鲁棒优化目标函数的设计需要仔细考虑如何平衡对齐程度较高的样本和最坏情况损失之间的关系。具体来说,可以使用一个加权损失函数,其中校准值作为权重,用于调整不同样本对损失函数的贡献。此外,还需要选择合适的优化算法来求解鲁棒优化问题。
🖼️ 关键图片

📊 实验亮点
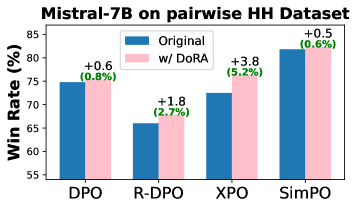
论文通过实验验证了所提出的鲁棒优化框架在分布偏移下的有效性。实验结果表明,与现有方法相比,该方法能够显著提高LLM生成符合人类价值观输出的质量。具体的性能提升数据和对比基线在论文中进行了详细描述,证明了该方法的优越性。
🎯 应用场景
该研究成果可应用于各种需要LLM生成符合人类价值观输出的场景,例如对话系统、内容生成、智能助手等。通过提高LLM对齐的鲁棒性,可以减少LLM生成有害、不准确或不符合伦理道德的输出的风险,从而提升用户体验和社会效益。未来,该方法可以进一步扩展到其他类型的分布偏移问题,并与其他对齐技术相结合,以实现更安全、可靠和负责任的LLM应用。
📄 摘要(原文)
Preference alignment methods are increasingly critical for steering large language models (LLMs) to generate outputs consistent with human values. While recent approaches often rely on synthetic data generated by LLMs for scalability and cost-efficiency reasons, this reliance can introduce distribution shifts that undermine the nuanced representation of human preferences needed for desirable outputs. In this paper, we propose a novel distribution-aware optimization framework that improves preference alignment despite such shifts. Our approach first leverages well-learned classifiers to assign a calibration value to each training sample, quantifying its alignment with the target human-preferred distribution. These values are then incorporated into a robust optimization objective that minimizes the worst-case loss over regions of the data space most relevant to human preferences. By explicitly focusing optimization on the target distribution, our approach mitigates the impact of distributional mismatch and improves the generation of responses that better reflect intended values.