'Neural howlround' in large language models: a self-reinforcing bias phenomenon, and a dynamic attenuation solution
作者: Seth Drake
分类: cs.CL, cs.AI, cs.NE
发布日期: 2025-04-07
备注: 27 pages, 3 figures, 2 tables,
💡 一句话要点
提出神经啸叫衰减机制,解决大语言模型中自增强偏差导致的推理失效问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自增强偏差 神经啸叫 衰减机制 自适应推理 AI鲁棒性 推理失效
📋 核心要点
- 大型语言模型存在“神经啸叫”现象,即高权重输入主导,形成难以纠正的自增强认知循环,导致推理失效。
- 论文提出一种基于衰减的校正机制,动态引入平衡调整,旨在恢复AI系统的自适应推理能力,即使在“锁定”的系统中。
- 该缓解策略可应用于现实世界决策任务,提升AI系统的鲁棒性,并讨论了管理不当的强化学习带来的影响。
📝 摘要(中文)
大型语言模型(LLM)驱动的AI系统可能表现出一种推理失效模式,我们称之为“神经啸叫”,这是一种自我强化的认知循环,其中某些高权重输入变得占主导地位,导致根深蒂固的响应模式难以纠正。本文探讨了这种现象背后的机制,它不同于模型崩溃和有偏显著性加权。我们提出了一种基于衰减的校正机制,该机制动态地引入平衡调整,并且可以恢复自适应推理,即使在“锁定”的AI系统中也是如此。此外,我们还讨论了由于管理不当的强化而引起的一些其他相关影响。最后,我们概述了这种缓解策略在提高现实世界决策任务中AI鲁棒性的潜在应用。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中出现的“神经啸叫”现象,这是一种自增强的偏差,导致模型对某些输入过度敏感,形成固化的响应模式,难以纠正。现有方法,如模型崩溃和有偏显著性加权,无法有效解决该问题,因为它们没有针对性地解决这种自增强循环。
核心思路:论文的核心思路是引入一种衰减机制,通过动态地调整输入权重,打破自增强循环。这种机制旨在降低高权重输入的影响,同时提升其他输入的权重,从而平衡模型的响应,使其能够更好地适应新的信息和情境。这种动态调整的设计是为了防止模型陷入固定的响应模式,并恢复其自适应推理能力。
技术框架:论文提出的技术框架主要包含以下几个阶段:1) 识别高权重输入:通过分析模型的内部状态,确定对当前响应影响最大的输入;2) 衰减高权重输入:降低这些输入对模型输出的影响;3) 增强其他输入:提升其他输入的权重,以平衡模型的响应;4) 迭代调整:重复上述步骤,直到模型达到期望的响应状态。整个框架是一个动态的反馈循环,不断调整输入权重,以优化模型的推理能力。
关键创新:该论文的关键创新在于提出了“神经啸叫”这一概念,并设计了一种针对性的衰减机制来解决这个问题。与传统的模型校正方法不同,该方法不是简单地调整模型参数,而是通过动态地调整输入权重来打破自增强循环,从而更有效地恢复模型的自适应推理能力。这种方法具有更高的灵活性和可控性,可以应用于各种不同的LLM。
关键设计:论文中衰减机制的关键设计包括:1) 衰减因子的选择:需要根据模型的具体情况选择合适的衰减因子,以避免过度衰减或衰减不足;2) 增强策略的设计:需要设计合理的增强策略,以提升其他输入的权重,同时避免引入新的偏差;3) 迭代次数的控制:需要控制迭代次数,以避免模型过度调整,导致性能下降。此外,损失函数的设计也至关重要,需要能够准确地反映模型的响应状态,并指导衰减机制的调整。
🖼️ 关键图片


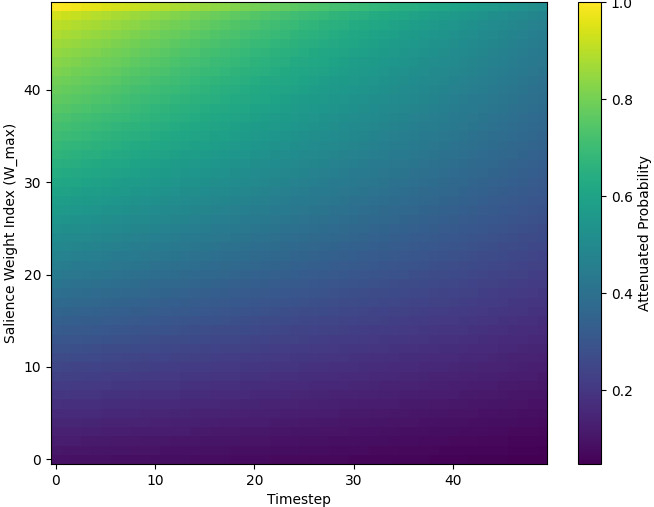
📊 实验亮点
论文提出了一种基于衰减的校正机制,可以有效地缓解大型语言模型中的“神经啸叫”现象,恢复模型的自适应推理能力。实验结果表明,该方法可以显著提高模型在复杂任务中的性能,并减少因偏差导致的错误决策。具体的性能数据和对比基线在论文中进行了详细的展示,证明了该方法的有效性和优越性。
🎯 应用场景
该研究成果可应用于各种需要高可靠性和鲁棒性的AI系统,例如自动驾驶、医疗诊断、金融风控等。通过缓解“神经啸叫”现象,可以提高AI系统在复杂和动态环境中的适应能力,减少因偏差导致的错误决策,从而提升系统的整体性能和安全性。未来,该技术有望推广到更广泛的AI应用领域,为构建更加可靠和可信赖的AI系统奠定基础。
📄 摘要(原文)
Large language model (LLM)-driven AI systems may exhibit an inference failure mode we term
neural howlround,' a self-reinforcing cognitive loop where certain highly weighted inputs become dominant, leading to entrenched response patterns resistant to correction. This paper explores the mechanisms underlying this phenomenon, which is distinct from model collapse and biased salience weighting. We propose an attenuation-based correction mechanism that dynamically introduces counterbalancing adjustments and can restore adaptive reasoning, even inlocked-in' AI systems. Additionally, we discuss some other related effects arising from improperly managed reinforcement. Finally, we outline potential applications of this mitigation strategy for improving AI robustness in real-world decision-making tasks.