Less but Better: Parameter-Efficient Fine-Tuning of Large Language Models for Personality Detection
作者: Lingzhi Shen, Yunfei Long, Xiaohao Cai, Guanming Chen, Imran Razzak, Shoaib Jameel
分类: cs.CL, cs.LG
发布日期: 2025-04-07
💡 一句话要点
PersLLM:面向人格检测,高效微调大语言模型的参数
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人格检测 参数高效微调 大语言模型 动态记忆层 可替换输出网络
📋 核心要点
- 现有方法在大语言模型人格检测中面临计算成本高昂和微调复杂性增加的挑战。
- PersLLM通过动态记忆层存储LLM提取的特征,并采用可替换的轻量级输出网络进行下游任务。
- 实验表明,PersLLM在降低计算成本的同时,保持了竞争性的性能和良好的适应性。
📝 摘要(中文)
人格检测旨在从社交媒体文本等数据源自动识别个体的性格。然而,随着语言模型参数规模的持续增长,计算成本变得越来越难以管理,微调也变得更加复杂,使得投入产出比难以评估。为了应对这些挑战,我们提出了一种新颖的参数高效微调框架PersLLM。在PersLLM中,大型语言模型(LLM)从原始数据中提取高维表示,并将它们存储在动态记忆层中。然后,PersLLM使用可替换的输出网络更新下游层,从而灵活地适应各种人格检测场景。通过将特征存储在记忆层中,我们消除了LLM重复复杂计算的需求。同时,轻量级输出网络充当评估框架整体有效性的代理,提高了结果的可预测性。在Kaggle和Pandora等关键基准数据集上的实验结果表明,PersLLM在保持竞争性能和强大适应性的同时,显著降低了计算成本。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在人格检测任务中微调时面临的计算成本高和微调复杂性问题。现有方法,特别是全参数微调,随着模型规模的增大,需要大量的计算资源和时间,并且难以预测微调效果。
核心思路:论文的核心思路是利用一个动态记忆层来存储大型语言模型提取的特征,从而避免重复计算。同时,使用一个轻量级的可替换输出网络来适应不同的下游任务,并作为评估框架有效性的代理,提高结果的可预测性。
技术框架:PersLLM框架主要包含三个模块:大型语言模型(LLM)、动态记忆层和可替换输出网络。首先,LLM从原始数据中提取高维特征表示。然后,这些特征被存储在动态记忆层中,避免了后续重复计算。最后,使用轻量级的可替换输出网络对记忆层中的特征进行处理,以适应不同的人格检测任务。
关键创新:PersLLM的关键创新在于动态记忆层和可替换输出网络的结合。动态记忆层通过存储LLM提取的特征,显著降低了计算成本。可替换输出网络则允许框架灵活地适应不同的下游任务,并提高了结果的可预测性。这种设计避免了对整个LLM进行微调,从而实现了参数高效的微调。
关键设计:动态记忆层的具体实现方式未知,但其核心功能是存储和检索LLM提取的特征。可替换输出网络的设计需要根据具体的下游任务进行调整,可以选择不同的网络结构和损失函数。论文中可能使用了特定的参数初始化方法或正则化技术来提高模型的泛化能力。具体的损失函数和优化器选择未知。
🖼️ 关键图片

📊 实验亮点
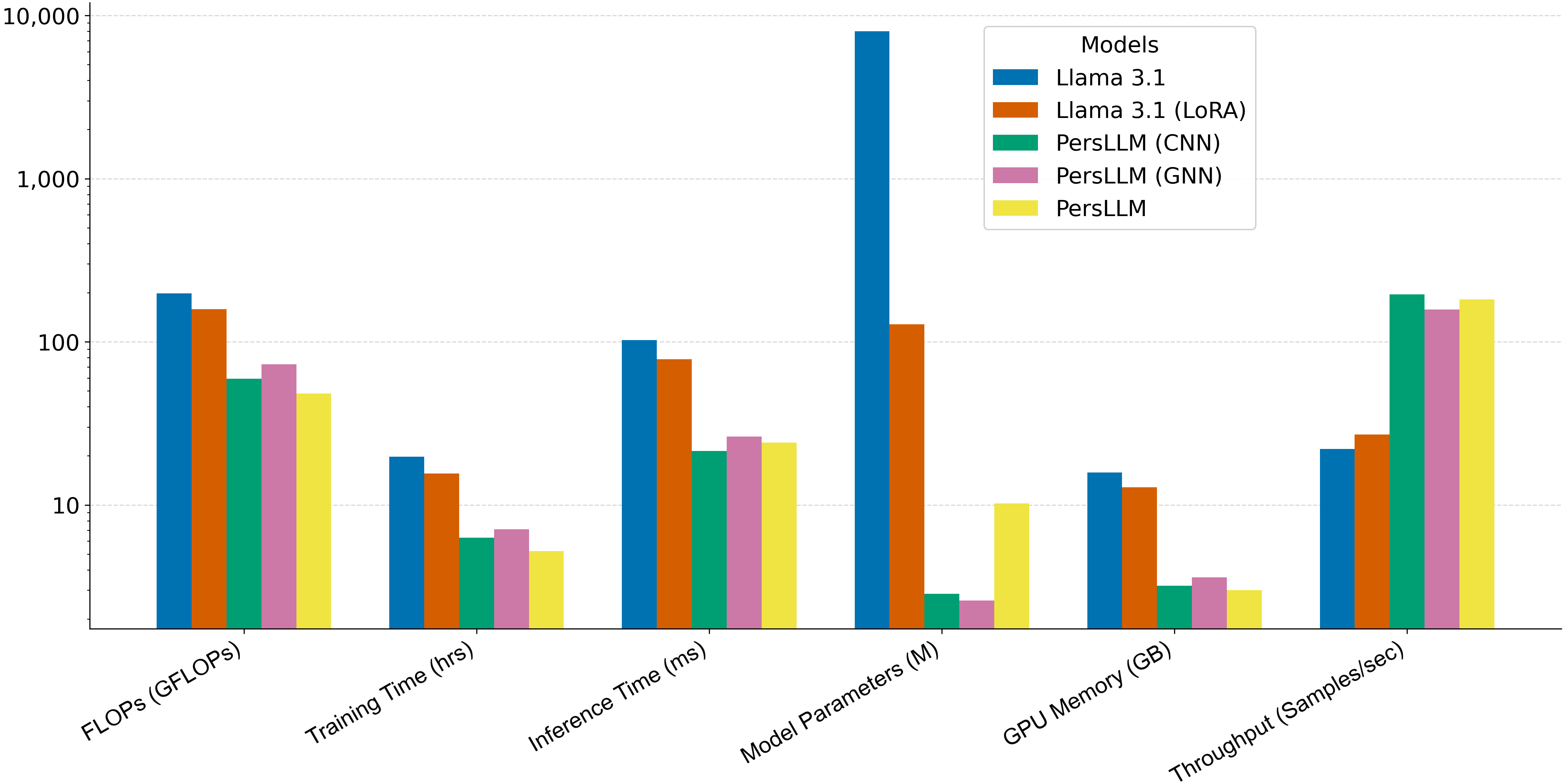
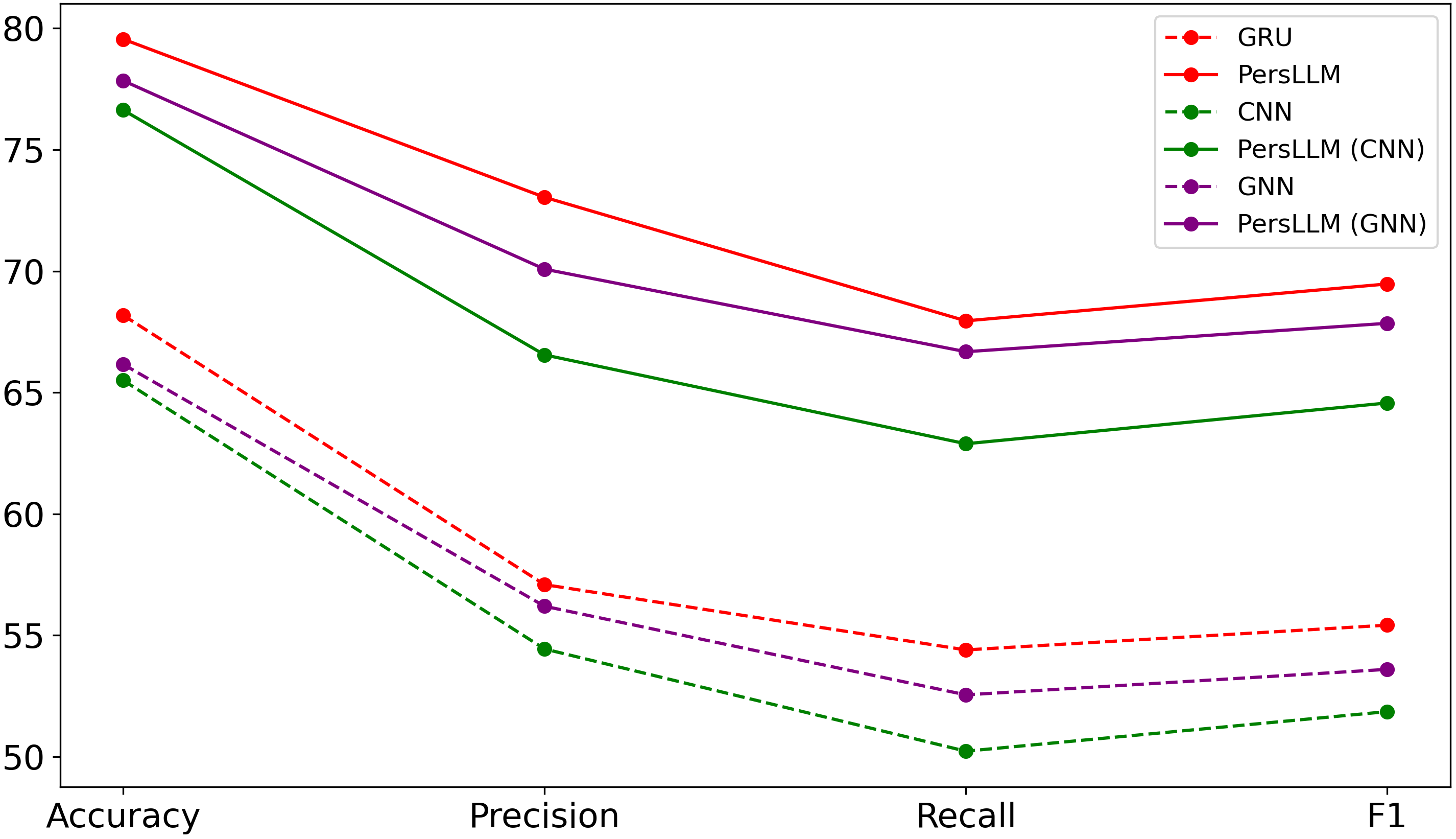
PersLLM在Kaggle和Pandora等基准数据集上进行了实验,结果表明该方法在保持竞争性能的同时,显著降低了计算成本。具体的性能提升数据未知,但论文强调了PersLLM在参数效率和适应性方面的优势。轻量级输出网络也提高了结果的可预测性。
🎯 应用场景
该研究成果可应用于社交媒体分析、用户画像构建、心理健康评估等领域。通过高效地识别人格特征,可以为个性化推荐、情感分析、风险预警等应用提供支持。未来,该方法有望扩展到其他自然语言处理任务,例如情感分类、文本摘要等。
📄 摘要(原文)
Personality detection automatically identifies an individual's personality from various data sources, such as social media texts. However, as the parameter scale of language models continues to grow, the computational cost becomes increasingly difficult to manage. Fine-tuning also grows more complex, making it harder to justify the effort and reliably predict outcomes. We introduce a novel parameter-efficient fine-tuning framework, PersLLM, to address these challenges. In PersLLM, a large language model (LLM) extracts high-dimensional representations from raw data and stores them in a dynamic memory layer. PersLLM then updates the downstream layers with a replaceable output network, enabling flexible adaptation to various personality detection scenarios. By storing the features in the memory layer, we eliminate the need for repeated complex computations by the LLM. Meanwhile, the lightweight output network serves as a proxy for evaluating the overall effectiveness of the framework, improving the predictability of results. Experimental results on key benchmark datasets like Kaggle and Pandora show that PersLLM significantly reduces computational cost while maintaining competitive performance and strong adaptability.