Do Large Language Models Truly Grasp Addition? A Rule-Focused Diagnostic Using Two-Integer Arithmetic
作者: Yang Yan, Yu Lu, Renjun Xu, Zhenzhong Lan
分类: cs.CL
发布日期: 2025-04-07 (更新: 2025-09-17)
备注: Accepted by EMNLP'25 Main
🔗 代码/项目: GITHUB
💡 一句话要点
通过规则诊断,揭示大语言模型在二整数加法中依赖模式匹配而非真正理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 算术推理 规则理解 模式匹配 诊断测试
📋 核心要点
- 现有大语言模型在算术任务中表现不稳定,无法确定其是否真正理解算术规则。
- 论文通过设计针对交换律、表示不变性和精度缩放的诊断测试,评估模型对加法规则的理解。
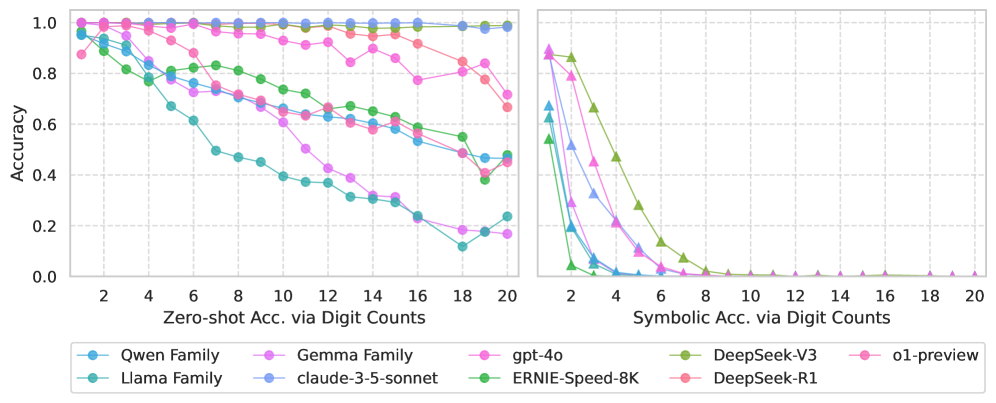
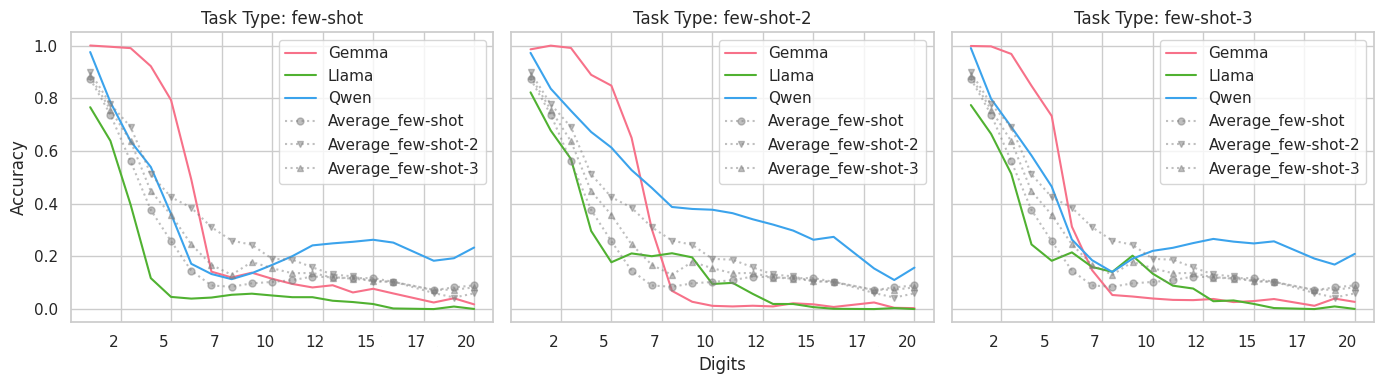
- 实验表明,模型在数值计算中表现良好,但在规则诊断中失败,揭示其依赖模式匹配而非规则归纳。
📝 摘要(中文)
大型语言模型(LLMs)在高级数学基准测试中表现出色,但在基本算术任务中却时有失败,这引发了一个问题:它们是否真正掌握了基本的算术规则,还是仅仅依赖于模式匹配?为了解开这个问题,我们通过测试三个关键属性:交换律(A+B=B+A),通过符号重映射的表示不变性(例如,7→Y),以及运算数长度的一致精度缩放,系统地探究了LLMs对二整数加法(0到2^64)的理解。对12个领先LLMs的评估揭示了一个明显的脱节:虽然模型实现了很高的数值精度(73.8-99.8%),但它们系统性地未能通过这些诊断。具体而言,使用符号输入时,精度骤降至≤7.5%,高达20%的情况下违反了交换律,并且精度缩放是非单调的。干预进一步暴露了这种对模式匹配的依赖:明确提供规则会使性能降低29.49%,而在回答之前提示解释仅能维持基线精度。这些发现表明,当前的LLMs通过模式匹配来解决基本加法问题,而不是通过鲁棒的规则归纳,这促使人们开发新的诊断基准以及模型架构和训练方面的创新,以培养真正的数学推理能力。我们的数据集和生成代码可在https://github.com/kuri-leo/llm-arithmetic-diagnostic获得。
🔬 方法详解
问题定义:论文旨在探究大型语言模型(LLMs)是否真正理解了基本的加法规则,还是仅仅通过模式匹配来完成加法任务。现有方法难以区分模型是基于规则理解还是模式匹配进行计算,导致对LLMs算术能力的评估不准确。
核心思路:论文的核心思路是通过设计一系列诊断测试,考察LLMs在加法运算中是否满足交换律、表示不变性和精度缩放等关键属性。如果LLMs真正理解了加法规则,那么它们应该能够通过这些测试,否则就表明它们依赖于模式匹配。
技术框架:论文的技术框架主要包括以下几个部分:1) 设计诊断测试,包括交换律测试、表示不变性测试和精度缩放测试;2) 选择12个具有代表性的LLMs进行评估;3) 分析实验结果,判断LLMs是否通过了诊断测试;4) 进行干预实验,例如提供规则或提示解释,以进一步验证LLMs的推理方式。
关键创新:论文最重要的技术创新点在于提出了基于规则的诊断方法,用于评估LLMs对加法规则的理解。与传统的数值精度评估不同,该方法关注LLMs是否满足加法运算的关键属性,从而更准确地判断其是否真正理解了加法规则。
关键设计:论文的关键设计包括:1) 交换律测试:随机生成两个整数A和B,测试LLM是否满足A+B=B+A;2) 表示不变性测试:将数字映射为符号,例如7映射为Y,测试LLM是否仍然能够正确计算;3) 精度缩放测试:测试随着运算数长度的增加,LLM的精度是否一致缩放;4) 干预实验:在提示中明确提供加法规则,或者要求LLM在回答之前给出解释,观察其对性能的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,尽管LLMs在数值加法中表现出较高的精度(73.8-99.8%),但在符号加法中精度骤降至≤7.5%。高达20%的案例违反了交换律。明确提供规则反而使性能降低29.49%。这些结果有力地证明了LLMs依赖于模式匹配而非真正的规则理解。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的数学推理能力,并为开发更可靠、更具泛化性的AI系统提供指导。通过揭示LLMs在基本算术任务中的局限性,可以促进模型架构和训练方法的创新,从而提升AI在科学计算、金融分析等领域的应用潜力。
📄 摘要(原文)
Large language models (LLMs) achieve impressive results on advanced mathematics benchmarks but sometimes fail on basic arithmetic tasks, raising the question of whether they have truly grasped fundamental arithmetic rules or are merely relying on pattern matching. To unravel this issue, we systematically probe LLMs' understanding of two-integer addition ($0$ to $2^{64}$) by testing three crucial properties: commutativity ($A+B=B+A$), representation invariance via symbolic remapping (e.g., $7 \mapsto Y$), and consistent accuracy scaling with operand length. Our evaluation of 12 leading LLMs reveals a stark disconnect: while models achieve high numeric accuracy (73.8-99.8%), they systematically fail these diagnostics. Specifically, accuracy plummets to $\le 7.5$% with symbolic inputs, commutativity is violated in up to 20% of cases, and accuracy scaling is non-monotonic. Interventions further expose this pattern-matching reliance: explicitly providing rules degrades performance by 29.49%, while prompting for explanations before answering merely maintains baseline accuracy. These findings demonstrate that current LLMs address elementary addition via pattern matching, not robust rule induction, motivating new diagnostic benchmarks and innovations in model architecture and training to cultivate genuine mathematical reasoning. Our dataset and generating code are available at https://github.com/kuri-leo/llm-arithmetic-diagnostic.