LLM-based Automated Grading with Human-in-the-Loop
作者: Yucheng Chu, Hang Li, Kaiqi Yang, Yasemin Copur-Gencturk, Jiliang Tang
分类: cs.CL
发布日期: 2025-04-07 (更新: 2025-12-01)
备注: Accepted to IEEE TALE 2025
💡 一句话要点
提出GradeHITL框架,利用人机协同提升LLM自动评分的准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自动评分 人机协同 教育应用 短答案评分
📋 核心要点
- 现有LLM自动评分方法在基于评分标准的评估中,难以达到人类水平,依赖全自动流程是主要瓶颈。
- GradeHITL框架利用LLM的生成能力,主动向人类专家提问,并将专家知识融入评分标准的动态优化中。
- 实验结果表明,GradeHITL显著提升了评分准确性,超越现有方法,更接近人类专家水平。
📝 摘要(中文)
人工智能技术,特别是大型语言模型(LLMs)的兴起,为教育领域带来了显著的进步。在众多应用中,自动短答案评分(ASAG)专注于评估开放式文本回复,随着LLMs的引入,取得了显著进展。与传统的ASAG方法相比,这些模型不仅提高了评分性能,而且超越了与预定义“标准”答案的简单比较,实现了更复杂的评分场景,例如基于评分标准的评估。然而,由于依赖于完全自动化的方法,现有的基于LLM的方法在基于评分标准的评估中,在达到人类水平的评分性能方面仍然面临挑战。在这项工作中,我们通过利用LLMs通过人机协同(HITL)方法的交互能力,探索了LLMs在ASAG任务中的潜力。我们提出的框架GradeHITL,利用LLMs的生成特性向人类专家提出问题,整合他们的见解以动态地改进评分标准。这种自适应过程显著提高了评分准确性,优于现有方法,并使ASAG更接近人类水平的评估。
🔬 方法详解
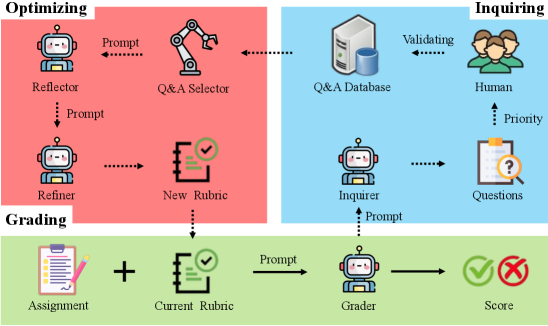
问题定义:论文旨在解决大型语言模型(LLM)在自动短答案评分(ASAG)中,尤其是在基于评分标准的评估中,难以达到人类专家水平的问题。现有方法主要依赖于全自动化的流程,缺乏与人类专家的有效互动,导致评分结果不够准确和可靠。
核心思路:论文的核心思路是引入人机协同(HITL)机制,利用LLM的生成能力,主动向人类专家提问,并将专家知识融入评分标准的动态优化过程中。通过迭代式的专家反馈和LLM的自适应学习,逐步提升评分的准确性和可靠性。这种方法旨在弥合LLM自动评分与人类专家评分之间的差距。
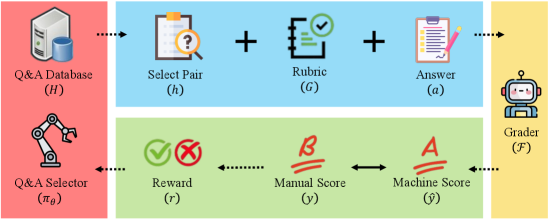
技术框架:GradeHITL框架包含以下主要模块:1) LLM问题生成模块:根据待评分的答案和当前的评分标准,生成针对人类专家的提问;2) 人类专家反馈模块:专家根据LLM提出的问题,提供反馈意见,例如修改评分标准或提供更详细的解释;3) 评分标准更新模块:根据专家反馈,动态更新评分标准,并将其反馈给LLM;4) LLM评分模块:使用更新后的评分标准,对答案进行评分。整个流程是一个迭代的过程,通过多轮的人机交互,不断优化评分标准和评分结果。
关键创新:该论文最重要的创新点在于将人机协同(HITL)引入到LLM自动评分流程中。与传统的全自动化方法相比,GradeHITL能够有效地利用人类专家的知识和经验,动态地改进评分标准,从而显著提升评分的准确性和可靠性。这种方法突破了LLM自动评分的瓶颈,使其更接近人类专家水平。
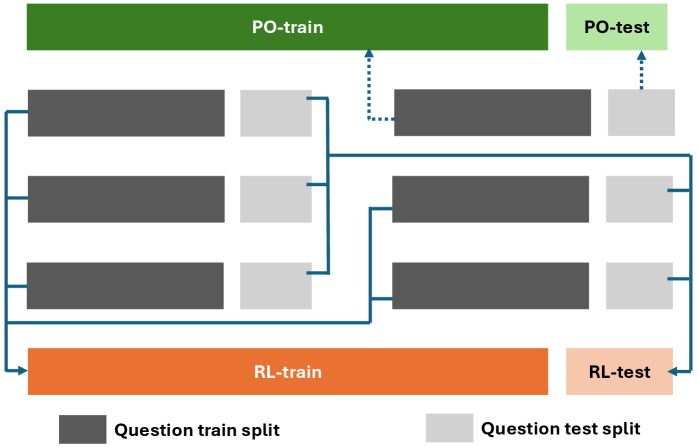
关键设计:GradeHITL的关键设计包括:1) LLM问题生成策略:如何设计有效的问题,引导专家提供有价值的反馈;2) 评分标准更新策略:如何将专家反馈有效地融入到评分标准的更新中;3) 迭代停止条件:何时停止人机交互,达到最佳的评分效果。论文中可能涉及一些超参数的设置,例如LLM生成问题的数量、专家反馈的权重等,但具体细节未知。
🖼️ 关键图片
📊 实验亮点
GradeHITL框架通过人机协同,显著提升了LLM自动评分的准确性,优于现有的全自动化方法。具体性能数据未知,但论文强调其评分结果更接近人类专家水平。实验结果表明,通过迭代式的专家反馈和LLM的自适应学习,可以有效地优化评分标准,提高评分的可靠性。
🎯 应用场景
该研究成果可广泛应用于在线教育、大规模考试评分、作业自动批改等领域。通过人机协同,可以显著提高评分效率和准确性,减轻教师的负担,并为学生提供更及时和个性化的反馈。未来,该技术还可以扩展到其他需要主观判断的评估任务中,例如论文评审、项目评估等。
📄 摘要(原文)
The rise of artificial intelligence (AI) technologies, particularly large language models (LLMs), has brought significant advancements to the field of education. Among various applications, automatic short answer grading (ASAG), which focuses on evaluating open-ended textual responses, has seen remarkable progress with the introduction of LLMs. These models not only enhance grading performance compared to traditional ASAG approaches but also move beyond simple comparisons with predefined "golden" answers, enabling more sophisticated grading scenarios, such as rubric-based evaluation. However, existing LLM-powered methods still face challenges in achieving human-level grading performance in rubric-based assessments due to their reliance on fully automated approaches. In this work, we explore the potential of LLMs in ASAG tasks by leveraging their interactive capabilities through a human-in-the-loop (HITL) approach. Our proposed framework, GradeHITL, utilizes the generative properties of LLMs to pose questions to human experts, incorporating their insights to refine grading rubrics dynamically. This adaptive process significantly improves grading accuracy, outperforming existing methods and bringing ASAG closer to human-level evaluation.