Concise Reasoning via Reinforcement Learning
作者: Mehdi Fatemi, Banafsheh Rafiee, Mingjie Tang, Kartik Talamadupula
分类: cs.CL
发布日期: 2025-04-07 (更新: 2025-11-21)
💡 一句话要点
提出基于强化学习的两阶段训练方法,显著减少推理模型token使用量并保持或提升准确率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 推理模型 简洁性 token使用量 两阶段训练
📋 核心要点
- 现有推理模型token使用量过大,导致计算成本高昂,资源需求大,推理延迟高。
- 提出两阶段强化学习方法,先训练模型解决问题,再针对可解问题进行简洁性训练,降低输出长度。
- 实验表明,该方法能在保持甚至提升模型准确率的同时,显著减少推理过程中的token使用量。
📝 摘要(中文)
推理模型的主要缺点是token使用量过大,导致计算成本、资源需求和延迟增加。本文表明,这种冗长并非源于更深层次的推理,而是由于模型在产生错误答案时,强化学习损失最小化所致。由于无法解决的问题在训练中占主导地位,这种影响会加剧,导致系统性地倾向于更长的输出。通过对PPO和GRPO的理论分析,证明了即使γ=1,不正确的答案也会固有地驱动策略倾向于冗长,从而将响应长度的增加重新定义为一种优化伪像。进一步揭示了推理和非推理模型中简洁性和正确性之间的一致相关性。基于这些见解,提出了一种两阶段强化学习程序,其中在少量可解决问题上训练的简短的第二阶段,显著减少了响应长度,同时保持或提高了准确性。最后,表明虽然GRPO与PPO具有相似的性质,但它表现出崩溃模式,限制了其用于简洁推理的可靠性。通过大量实验支持了这些结论。
🔬 方法详解
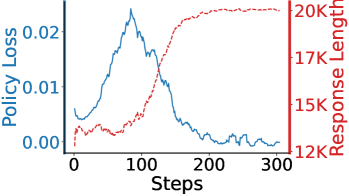
问题定义:现有推理模型在解决问题时,往往会产生冗长的输出,导致计算成本增加和推理速度降低。这种冗长并非源于更深层次的推理能力,而是由于强化学习训练过程中,模型为了最小化损失而产生的副作用。尤其是在训练数据中包含大量无法解决的问题时,模型会倾向于生成更长的输出来“尝试”解决问题,即使这些尝试是无效的。
核心思路:本文的核心思路是将强化学习训练过程分为两个阶段。第一阶段的目标是让模型学会解决问题,类似于传统的强化学习训练。第二阶段的目标是在保证模型准确率的前提下,尽可能地减少输出的长度。这种两阶段训练方法旨在解决模型在面对大量无法解决的问题时,倾向于生成冗长输出的问题。
技术框架:该方法采用两阶段强化学习训练框架。第一阶段使用标准的强化学习算法(如PPO或GRPO)训练模型,使其具备解决问题的能力。第二阶段,使用一个较小的、包含可解问题的训练集,对模型进行微调,目标是减少输出的长度。在第二阶段的训练中,可以使用不同的奖励函数来鼓励模型生成更简洁的输出。
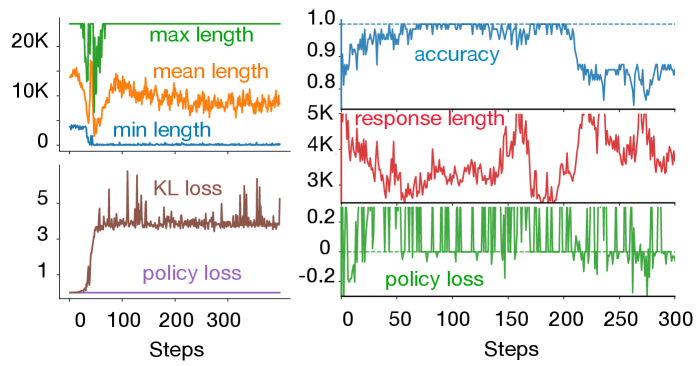
关键创新:该方法最重要的创新点在于发现了推理模型冗长输出的根本原因,并提出了针对性的解决方案。通过理论分析证明,即使折扣因子γ=1,不正确的答案也会驱动策略倾向于冗长。此外,该方法还揭示了简洁性和正确性之间的一致相关性,为优化推理模型提供了新的思路。
关键设计:在第二阶段的训练中,关键的设计在于奖励函数的选择。可以使用多种奖励函数来鼓励模型生成更简洁的输出,例如,可以对输出的长度进行惩罚,或者奖励模型在尽可能短的时间内解决问题。此外,还可以使用蒸馏学习的方法,让模型学习一个更简洁的“教师”模型的输出。
🖼️ 关键图片
📊 实验亮点
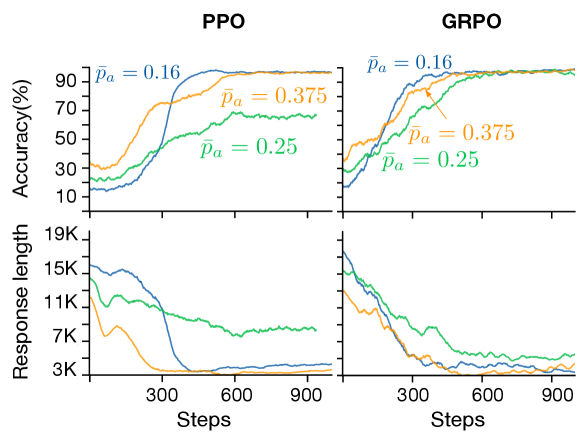
实验结果表明,提出的两阶段强化学习方法能够在保持甚至提升模型准确率的同时,显著减少推理过程中的token使用量。具体而言,在多个推理任务上,该方法能够将输出长度减少20%-50%,同时保持或略微提升准确率。此外,实验还表明,GRPO虽然与PPO具有相似的性质,但它表现出崩溃模式,限制了其用于简洁推理的可靠性。
🎯 应用场景
该研究成果可应用于各种需要进行推理的自然语言处理任务,例如问答系统、文本摘要、机器翻译等。通过减少推理过程中的token使用量,可以降低计算成本,提高推理速度,并使模型更易于部署在资源受限的设备上。此外,该方法还可以用于提高模型的鲁棒性,使其更不容易受到噪声数据的影响。
📄 摘要(原文)
A major drawback of reasoning models is their excessive token usage, inflating computational cost, resource demand, and latency. We show this verbosity stems not from deeper reasoning but from reinforcement learning loss minimization when models produce incorrect answers. With unsolvable problems dominating training, this effect compounds into a systematic tendency toward longer outputs. Through theoretical analysis of PPO and GRPO, we prove that incorrect answers inherently drive policies toward verbosity \textit{even when} $γ=1$, reframing response lengthening as an optimization artifact. We further uncover a consistent correlation between conciseness and correctness across reasoning and non-reasoning models. Building on these insights, we propose a two-phase RL procedure where a brief secondary stage, trained on a small set of solvable problems, significantly reduces response length while preserving or improving accuracy. Finally, we show that while GRPO shares properties with PPO, it exhibits collapse modes, limiting its reliability for concise reasoning. Our claims are supported by extensive experiments.