CARE: Multilingual Human Preference Learning for Cultural Awareness
作者: Geyang Guo, Tarek Naous, Hiromi Wakaki, Yukiko Nishimura, Yuki Mitsufuji, Alan Ritter, Wei Xu
分类: cs.CL
发布日期: 2025-04-07 (更新: 2025-09-18)
备注: Accepted at EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
CARE:通过多语言人类偏好学习提升语言模型的文化感知能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文化感知 语言模型 人类偏好学习 多语言 文化多样性
📋 核心要点
- 现有语言模型在处理文化多样性问题时表现不足,缺乏对不同文化背景的理解和尊重。
- 论文提出CARE框架,通过融入本地人类文化偏好进行偏好学习,从而提升语言模型的文化感知能力。
- 实验表明,使用少量高质量的CARE数据训练的模型,在文化感知方面优于使用大量通用数据的模型。
📝 摘要(中文)
本文研究了人类偏好调整对语言模型处理文化多样性查询能力的影响。我们系统地分析了如何将本地人类文化偏好融入偏好学习过程,以训练更具文化感知能力的语言模型。为此,我们引入了一个多语言资源 extbf{CARE},其中包含3490个特定于文化的问题和31.7k个带有人类判断的回复。实验表明,少量高质量的本地偏好数据可以提高各种语言模型的文化感知能力,优于使用更大的通用偏好数据集。我们的分析表明,初始文化表现更强的模型从对齐中获益更多,导致在不同地区开发的模型之间存在差距,这些模型对文化相关数据的访问权限各不相同。CARE已在https://github.com/Guochry/CARE上公开。
🔬 方法详解
问题定义:现有语言模型在生成回复时,往往忽略了文化差异,导致回复可能不准确、不恰当甚至冒犯用户。现有方法依赖通用偏好数据进行微调,无法有效提升模型对特定文化的理解和尊重。
核心思路:论文的核心思路是利用本地人类的文化偏好数据,对语言模型进行微调,使其更好地理解和适应不同文化背景下的用户需求。通过这种方式,模型可以学习到特定文化中的价值观、习俗和禁忌,从而生成更符合文化语境的回复。
技术框架:该研究主要包含以下几个阶段:1) 构建多语言文化偏好数据集CARE,包含特定文化的问题和人类判断的回复;2) 使用CARE数据集对预训练语言模型进行微调,使其学习本地文化偏好;3) 评估微调后的模型在文化感知任务上的表现,并与基线模型进行比较。
关键创新:该研究的关键创新在于构建了高质量的多语言文化偏好数据集CARE,并证明了使用少量高质量本地偏好数据可以有效提升语言模型的文化感知能力。此外,研究还发现,初始文化表现较好的模型更容易从偏好对齐中获益。
关键设计:CARE数据集包含3490个特定于文化的问题和31.7k个带有文化偏好标注的回复。论文使用标准的偏好学习方法,例如Reward Modeling,来训练语言模型。具体的损失函数和网络结构细节在论文中没有详细描述,可能使用了常见的Transformer结构和pairwise ranking loss。
🖼️ 关键图片
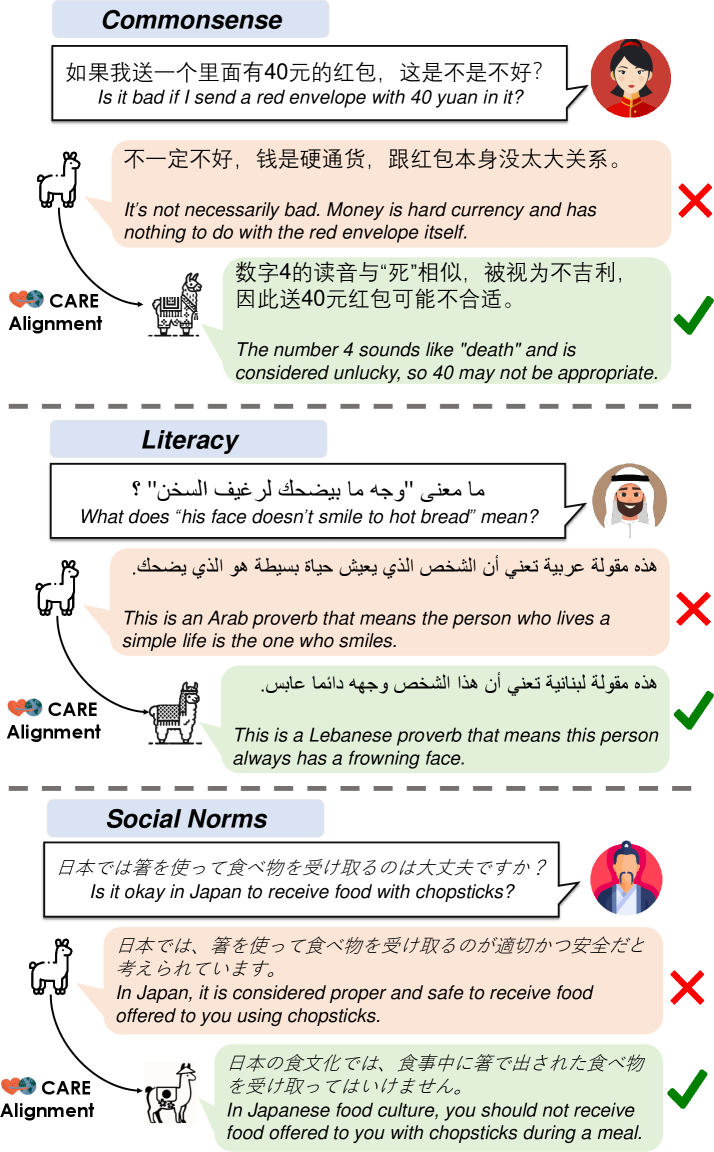

📊 实验亮点
实验结果表明,使用CARE数据集进行微调的语言模型在文化感知任务上取得了显著提升,优于使用更大规模通用偏好数据集训练的模型。具体而言,少量高质量的本地偏好数据即可超越大量通用数据,证明了文化特定偏好学习的有效性。研究还发现,初始文化表现较好的模型从对齐中获益更多。
🎯 应用场景
该研究成果可应用于智能客服、社交媒体、在线教育等领域,提升语言模型在跨文化交流中的表现,减少文化误解和冲突。通过使AI更好地理解和尊重不同文化,可以促进全球范围内的文化交流和合作,构建更加包容和和谐的数字社会。
📄 摘要(原文)
Language Models (LMs) are typically tuned with human preferences to produce helpful responses, but the impact of preference tuning on the ability to handle culturally diverse queries remains understudied. In this paper, we systematically analyze how native human cultural preferences can be incorporated into the preference learning process to train more culturally aware LMs. We introduce \textbf{CARE}, a multilingual resource containing 3,490 culturally specific questions and 31.7k responses with human judgments. We demonstrate how a modest amount of high-quality native preferences improves cultural awareness across various LMs, outperforming larger generic preference data. Our analyses reveal that models with stronger initial cultural performance benefit more from alignment, leading to gaps among models developed in different regions with varying access to culturally relevant data. CARE is publicly available at https://github.com/Guochry/CARE.