Improving Multilingual Retrieval-Augmented Language Models through Dialectic Reasoning Argumentations
作者: Leonardo Ranaldi, Federico Ranaldi, Fabio Massimo Zanzotto, Barry Haddow, Alexandra Birch
分类: cs.CL
发布日期: 2025-04-07
💡 一句话要点
提出Dialectic-RAG,通过辩证推理增强多语言检索增强语言模型,提升知识利用和鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 多语言处理 辩证推理 论证性解释 知识冲突解决
📋 核心要点
- 现有RAG方法在多语言环境下,由于检索知识的异质性,LLM面临潜在的冲突知识处理难题。
- Dialectic-RAG通过论证性解释指导,系统评估检索信息,比较、对比和解决冲突观点,提升RAG的分析能力。
- 实验结果表明,DRAG显著提升了RAG方法,同时保持较低的计算成本,并增强了对知识扰动的鲁棒性。
📝 摘要(中文)
检索增强生成(RAG)是增强大型语言模型(LLM)的关键,它使LLM能够系统地访问更丰富的实况知识。然而,使用RAG带来内在的挑战,因为LLM必须处理潜在的冲突知识,尤其是在多语言检索中,检索到的知识异质性可能传递不同的观点。为了使RAG更具分析性、批判性和依据性,我们引入了Dialectic-RAG(DRAG),这是一种模块化方法,由论证性解释指导,即通过比较、对比和解决冲突观点来系统地评估检索到的信息的结构化推理过程。给定一个查询和一组多语言相关文档,DRAG选择并例证相关知识,以提供辩证解释,通过批判性地权衡对立的论点和过滤无关内容,清楚地确定最终响应。通过一系列深入的实验,我们展示了我们的框架作为一种上下文学习策略和构建演示来指导较小模型的影响。最终结果表明,DRAG显著改进了RAG方法,只需要低影响的计算工作,并提供对知识扰动的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决多语言检索增强生成(RAG)中,大型语言模型(LLM)面临的知识冲突问题。在多语言环境下,检索到的文档可能包含相互矛盾的信息,导致LLM难以做出准确、可靠的判断。现有RAG方法缺乏有效的机制来识别和解决这些冲突,影响了生成结果的质量和可信度。
核心思路:论文的核心思路是引入辩证推理(Dialectic Reasoning)来增强RAG过程。通过构建论证性解释(Argumentative Explanations),DRAG能够系统地评估检索到的信息,比较、对比和解决冲突的观点。这种方法模拟了人类辩论的过程,使LLM能够更全面、深入地理解问题,并做出更合理的决策。
技术框架:Dialectic-RAG (DRAG) 包含以下主要模块:1) 多语言文档检索:从多语言文档库中检索与查询相关的文档。2) 论证性解释生成:针对每个检索到的文档,生成相应的论证性解释,包括支持和反对查询的论点。3) 辩证推理:比较、对比不同文档的论证性解释,识别和解决冲突的观点。4) 响应生成:基于辩证推理的结果,生成最终的响应。整个流程旨在模拟人类辩论的过程,使LLM能够更全面、深入地理解问题,并做出更合理的决策。
关键创新:DRAG 的最重要创新在于将辩证推理引入到 RAG 框架中。与传统的 RAG 方法相比,DRAG 不仅仅是简单地将检索到的文档输入到 LLM 中,而是通过论证性解释和辩证推理,使 LLM 能够更深入地理解和评估检索到的信息。这种方法能够有效地解决多语言环境下知识冲突的问题,提高生成结果的质量和可信度。
关键设计:DRAG 的关键设计包括:1) 论证性解释的结构:论证性解释包含支持和反对查询的论点,以及相应的证据。2) 辩证推理的算法:辩证推理算法用于比较、对比不同文档的论证性解释,识别和解决冲突的观点。3) 响应生成的策略:响应生成策略用于基于辩证推理的结果,生成最终的响应。论文中可能还涉及一些超参数的调整,例如论证性解释的长度、辩证推理的迭代次数等,但具体细节未知。
🖼️ 关键图片

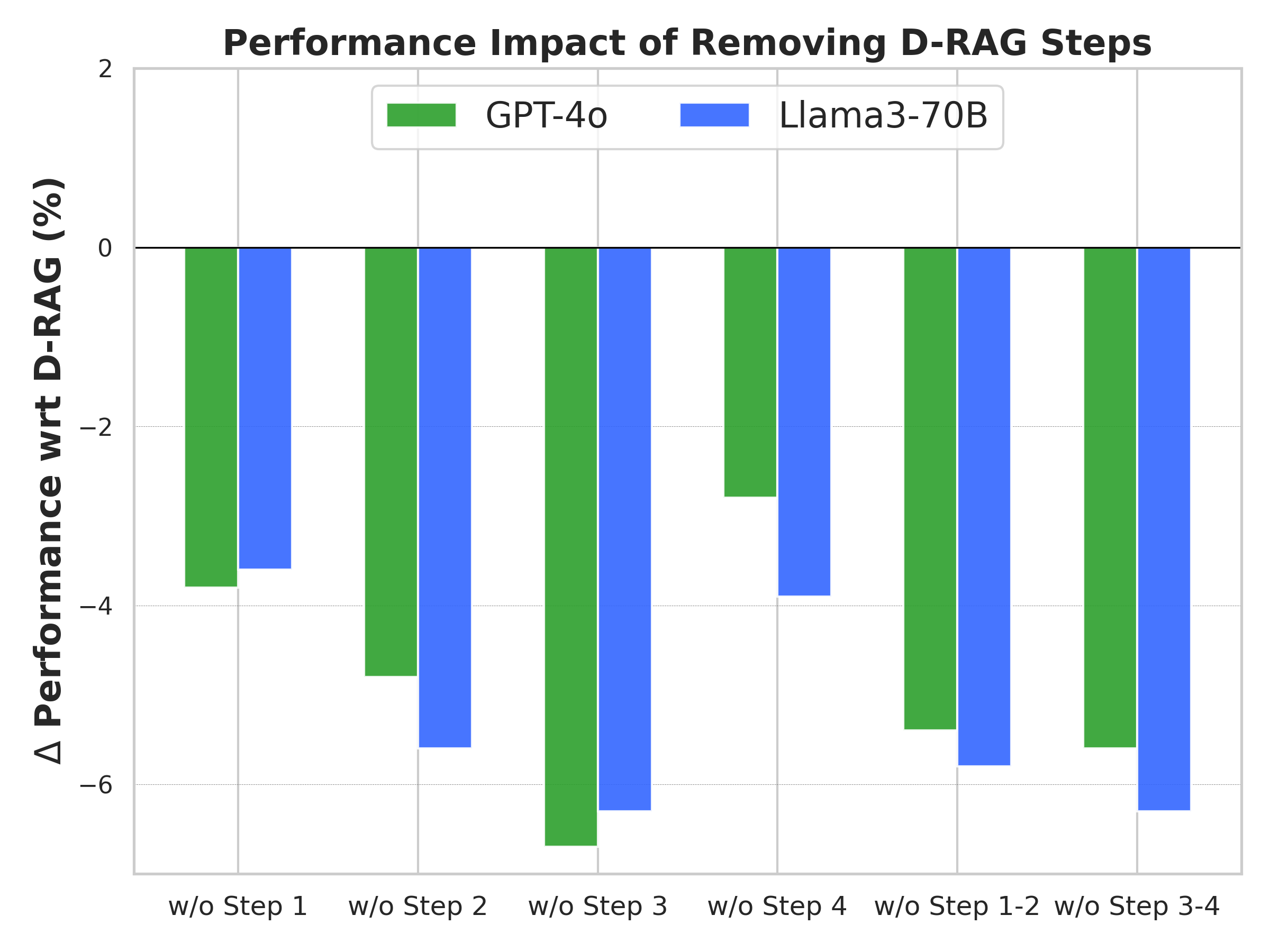

📊 实验亮点
实验结果表明,Dialectic-RAG (DRAG) 显著改进了 RAG 方法,在多个数据集上取得了显著的性能提升。DRAG 不仅提高了生成结果的准确性和可靠性,还增强了模型对知识扰动的鲁棒性。此外,DRAG 只需要低影响的计算工作,使其具有很高的实用价值。具体的性能数据和对比基线未知。
🎯 应用场景
Dialectic-RAG具有广泛的应用前景,例如:多语言问答系统、信息检索、知识图谱构建、智能客服等。该方法可以提高LLM在处理复杂、冲突信息时的准确性和可靠性,尤其是在需要整合多来源、多语言信息的场景下。未来,DRAG有望应用于更广泛的自然语言处理任务,并促进人机交互的智能化发展。
📄 摘要(原文)
Retrieval-augmented generation (RAG) is key to enhancing large language models (LLMs) to systematically access richer factual knowledge. Yet, using RAG brings intrinsic challenges, as LLMs must deal with potentially conflicting knowledge, especially in multilingual retrieval, where the heterogeneity of knowledge retrieved may deliver different outlooks. To make RAG more analytical, critical and grounded, we introduce Dialectic-RAG (DRAG), a modular approach guided by Argumentative Explanations, i.e., structured reasoning process that systematically evaluates retrieved information by comparing, contrasting, and resolving conflicting perspectives. Given a query and a set of multilingual related documents, DRAG selects and exemplifies relevant knowledge for delivering dialectic explanations that, by critically weighing opposing arguments and filtering extraneous content, clearly determine the final response. Through a series of in-depth experiments, we show the impact of our framework both as an in-context learning strategy and for constructing demonstrations to instruct smaller models. The final results demonstrate that DRAG significantly improves RAG approaches, requiring low-impact computational effort and providing robustness to knowledge perturbations.