TathyaNyaya and FactLegalLlama: Advancing Factual Judgment Prediction and Explanation in the Indian Legal Context
作者: Shubham Kumar Nigam, Balaramamahanthi Deepak Patnaik, Shivam Mishra, Noel Shallum, Kripabandhu Ghosh, Arnab Bhattacharya
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2025-04-07 (更新: 2025-11-15)
备注: Paper accepted in the AACL-IJCNLP 2025 conference
💡 一句话要点
提出TathyaNyaya数据集和FactLegalLlama模型,用于印度法律背景下的事实性判决预测与解释。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实性判决预测 可解释AI 印度法律 大型语言模型 指令调优 法律数据集 司法决策
📋 核心要点
- 现有基于事实的判决预测与解释方法依赖完整法律文本,忽略了司法过程中事实数据驱动结果的特性。
- 论文构建了TathyaNyaya数据集,并提出了FactLegalLlama模型,专注于事实陈述,生成高质量的判决解释。
- 实验表明,TathyaNyaya数据集规模和多样性超越现有数据集,为可解释法律AI系统建立新基准。
📝 摘要(中文)
本文介绍了TathyaNyaya,这是针对印度法律背景下基于事实的判决预测与解释(FJPE)的最大规模的标注数据集,涵盖了印度最高法院和各高等法院的判决。TathyaNyaya数据集侧重于事实陈述而非完整的法律文本,反映了现实世界中事实数据驱动结果的司法过程。此外,本文还提出了FactLegalLlama,这是LLaMa-3-8B大型语言模型的指令调优变体,针对生成高质量的FJPE解释进行了优化。FactLegalLlama在TathyaNyaya的事实数据上进行微调,集成了预测准确性与连贯、上下文相关的解释,满足了AI辅助法律系统中对透明性和可解释性的关键需求。该方法结合了用于二元判决预测的Transformer和用于解释生成的FactLegalLlama,为推进印度法律领域的FJPE创建了一个强大的框架。TathyaNyaya不仅在规模和多样性上超越了现有数据集,还为构建法律分析中可解释的AI系统建立了基准。研究结果强调了事实精确性和领域特定调整在提高预测性能和可解释性方面的重要性,使TathyaNyaya和FactLegalLlama成为AI辅助法律决策的基础资源。
🔬 方法详解
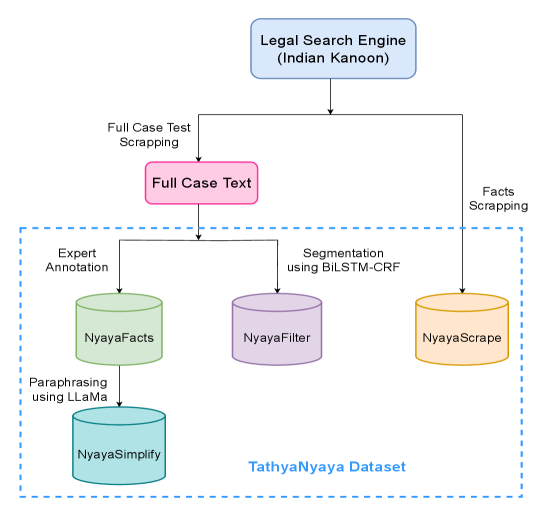
问题定义:论文旨在解决印度法律领域中,基于事实的判决预测与解释(FJPE)问题。现有方法主要依赖于完整的法律文本,而忽略了在实际司法过程中,法官往往是基于关键的事实陈述做出判决的。因此,现有方法无法很好地模拟真实的司法决策过程,并且缺乏针对事实的解释能力。
核心思路:论文的核心思路是构建一个大规模的、专注于事实陈述的法律数据集(TathyaNyaya),并在此基础上微调一个大型语言模型(FactLegalLlama),使其能够根据给定的事实陈述,预测判决结果,并生成高质量的解释。这种设计更贴近真实的司法决策过程,并且能够提供更具针对性和可解释性的结果。
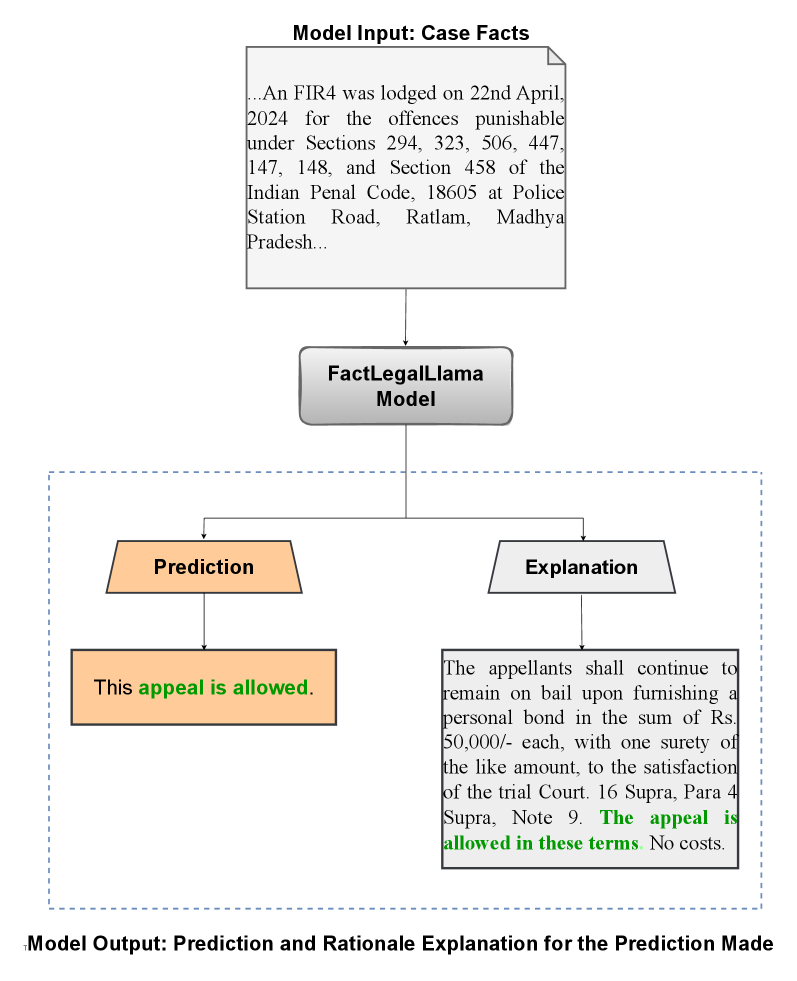
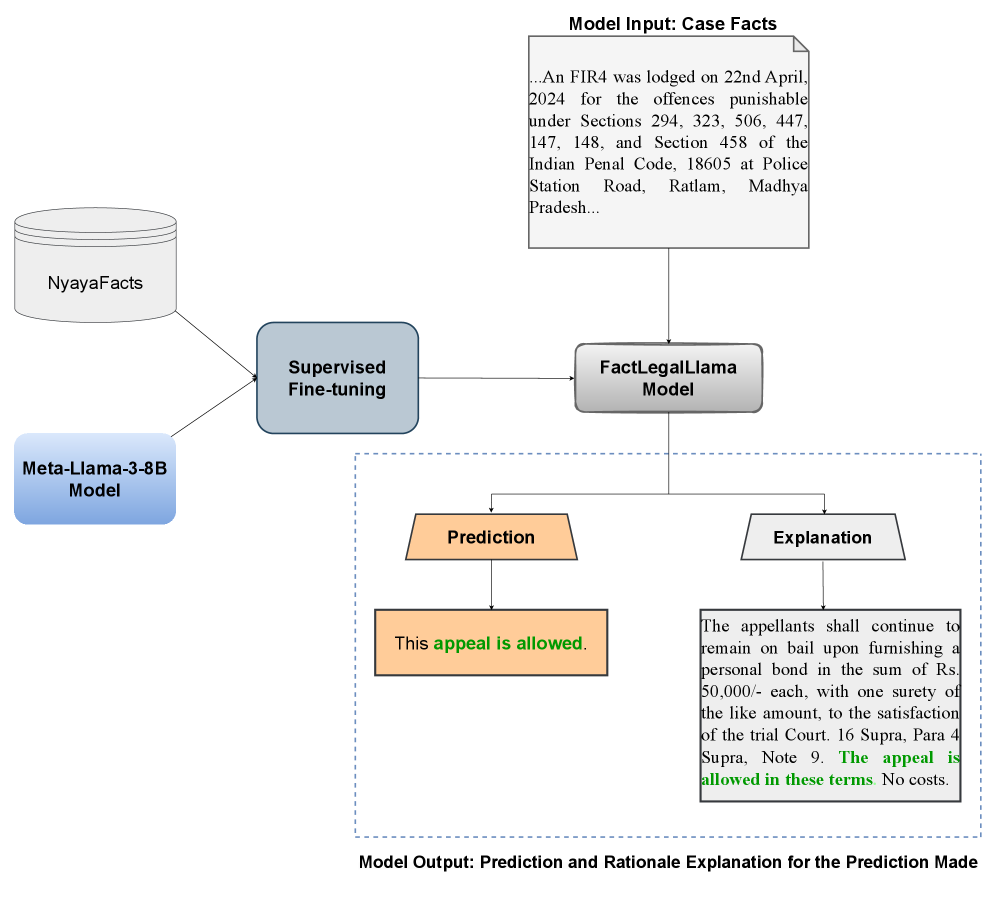
技术框架:整体框架包含两个主要部分:1) 使用Transformer模型进行二元判决预测;2) 使用FactLegalLlama模型生成判决解释。首先,将TathyaNyaya数据集中的事实陈述输入到Transformer模型中,预测判决结果(例如,胜诉或败诉)。然后,将相同的事实陈述输入到FactLegalLlama模型中,生成对判决结果的解释。这两个部分共同构成了一个完整的FJPE系统。
关键创新:论文的关键创新在于:1) 构建了TathyaNyaya数据集,这是目前印度法律领域中规模最大的、专注于事实陈述的FJPE数据集;2) 提出了FactLegalLlama模型,这是一个针对FJPE任务进行指令调优的LLaMa-3-8B变体,能够生成高质量的判决解释。与现有方法相比,该方法更注重事实本身,并且能够提供更具针对性和可解释性的结果。
关键设计:TathyaNyaya数据集的设计关键在于对事实陈述的标注,确保标注的准确性和一致性。FactLegalLlama模型的关键设计在于指令调优策略,通过精心设计的指令,引导模型生成高质量的判决解释。具体的损失函数和网络结构细节在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片
📊 实验亮点
TathyaNyaya数据集在规模和多样性上超越了现有的印度法律数据集,为构建可解释的法律AI系统奠定了基础。FactLegalLlama模型通过在TathyaNyaya数据集上进行微调,显著提高了判决解释的质量,具体性能数据和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可应用于AI辅助法律决策系统,帮助律师和法官快速理解案情、预测判决结果,并生成判决解释。此外,该研究还可以促进法律领域的透明化和可解释性,提高公众对司法系统的信任度。未来,该技术有望应用于法律教育、法律咨询等领域,为法律从业者和普通民众提供更便捷、高效的法律服务。
📄 摘要(原文)
In the landscape of Fact-based Judgment Prediction and Explanation (FJPE), reliance on factual data is essential for developing robust and realistic AI-driven decision-making tools. This paper introduces TathyaNyaya, the largest annotated dataset for FJPE tailored to the Indian legal context, encompassing judgments from the Supreme Court of India and various High Courts. Derived from the Hindi terms "Tathya" (fact) and "Nyaya" (justice), the TathyaNyaya dataset is uniquely designed to focus on factual statements rather than complete legal texts, reflecting real-world judicial processes where factual data drives outcomes. Complementing this dataset, we present FactLegalLlama, an instruction-tuned variant of the LLaMa-3-8B Large Language Model (LLM), optimized for generating high-quality explanations in FJPE tasks. Finetuned on the factual data in TathyaNyaya, FactLegalLlama integrates predictive accuracy with coherent, contextually relevant explanations, addressing the critical need for transparency and interpretability in AI-assisted legal systems. Our methodology combines transformers for binary judgment prediction with FactLegalLlama for explanation generation, creating a robust framework for advancing FJPE in the Indian legal domain. TathyaNyaya not only surpasses existing datasets in scale and diversity but also establishes a benchmark for building explainable AI systems in legal analysis. The findings underscore the importance of factual precision and domain-specific tuning in enhancing predictive performance and interpretability, positioning TathyaNyaya and FactLegalLlama as foundational resources for AI-assisted legal decision-making.