Are You Getting What You Pay For? Auditing Model Substitution in LLM APIs
作者: Will Cai, Tianneng Shi, Xuandong Zhao, Dawn Song
分类: cs.CL, cs.CR, cs.LG
发布日期: 2025-04-07 (更新: 2025-09-29)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于TEE的LLM API模型替换检测方案,保障用户权益。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型替换 可信执行环境 API安全 硬件安全
📋 核心要点
- 现有软件方法难以可靠检测LLM API中的模型替换,易受对抗攻击和推理不确定性影响。
- 利用可信执行环境(TEE)提供硬件级别的安全保障,实现对模型完整性的密码学验证。
- 实验表明,基于TEE的方案能有效检测模型替换,且性能开销可接受,具有实际应用价值。
📝 摘要(中文)
商业大型语言模型(LLM)API 产生了一个根本的信任问题:用户为特定模型付费,但无法保证提供商忠实地交付这些模型。提供商可能会秘密地替换更便宜的替代品(例如,量化版本、较小的模型),以降低成本,同时保持广告价格。我们形式化了这种模型替换问题,并系统地评估了在现实对抗条件下检测方法。我们的经验分析表明,纯软件方法从根本上是不可靠的:对文本输出的统计测试需要大量的查询,并且在面对细微的替换时会失败,而使用对数概率的方法会被生产环境中固有的推理不确定性所击败。我们认为,这种验证差距可以通过硬件级别的安全性更有效地弥合。我们提出并评估了使用可信执行环境(TEE)作为一种实用且稳健的解决方案。我们的研究结果表明,TEE 可以提供可证明的密码学模型完整性保证,且性能开销适中,从而为确保用户获得他们所支付的服务提供了一条清晰且可操作的途径。
🔬 方法详解
问题定义:论文旨在解决LLM API服务中,服务提供商可能使用低成本模型替换用户付费模型的问题。现有软件检测方法,如基于文本输出统计特征的检测和基于对数概率的检测,容易受到对抗攻击和推理过程中的不确定性影响,无法提供可靠的保证。
核心思路:论文的核心思路是利用可信执行环境(TEE)提供的硬件安全特性,在TEE内部运行LLM,并对模型进行完整性校验。由于TEE的隔离性,可以防止服务提供商篡改模型,从而为用户提供可信的模型保证。
技术框架:整体框架包括以下几个主要模块:1) 用户端:发起API请求,并验证返回结果的完整性证明。2) TEE内部:运行LLM模型,并生成模型输出和完整性证明。3) 服务提供商:部署TEE环境,并提供API服务。用户通过API请求,服务提供商在TEE内部运行LLM,并将结果和完整性证明返回给用户。用户端验证完整性证明,确保模型未被篡改。
关键创新:最重要的技术创新点在于利用TEE提供硬件级别的模型完整性保证。与传统的软件方法相比,TEE可以防止服务提供商在软件层面进行模型替换,从而提供更强的安全性。此外,该方案在保证安全性的同时,尽量降低了性能开销,使其具有实际应用价值。
关键设计:论文的关键设计包括:1) 选择合适的TEE硬件平台,如Intel SGX或AMD SEV。2) 设计高效的模型加载和推理流程,以降低TEE内部的性能开销。3) 实现安全的密钥管理机制,确保TEE内部密钥的安全。4) 设计轻量级的完整性证明生成和验证方法,以降低用户端的计算开销。
🖼️ 关键图片
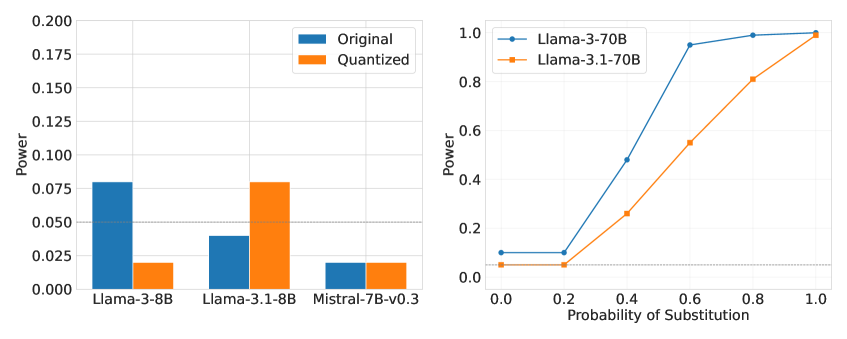
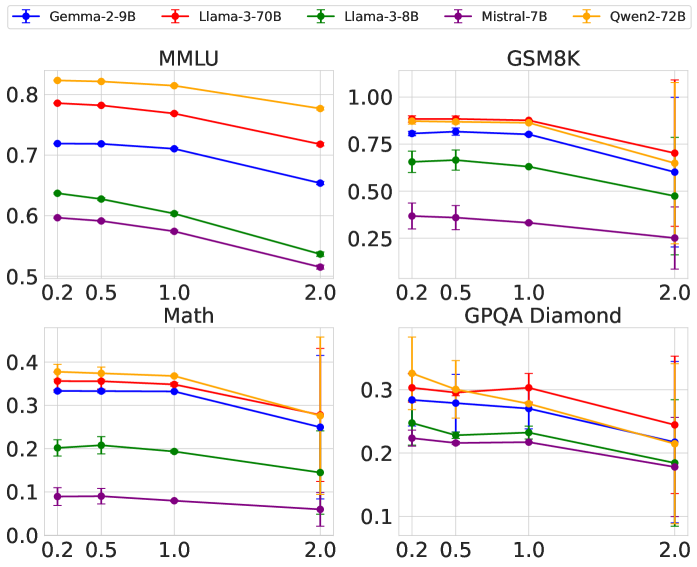
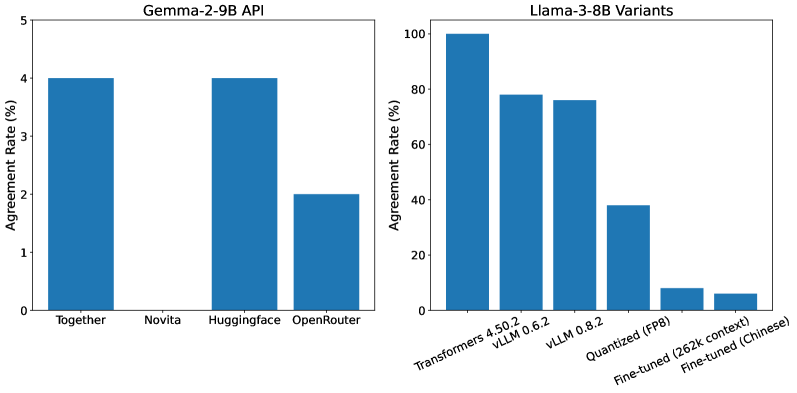
📊 实验亮点
论文通过实验验证了基于TEE的LLM API模型替换检测方案的有效性。实验结果表明,该方案可以有效地检测各种模型替换攻击,并且性能开销适中。与传统的软件方法相比,该方案具有更高的安全性,可以为用户提供更可靠的模型保证。具体而言,TEE方案引入的额外延迟在可接受范围内,证明了其在实际生产环境中的可行性。
🎯 应用场景
该研究成果可应用于各种LLM API服务,例如文本生成、机器翻译、代码生成等。通过使用TEE技术,可以确保用户获得他们所支付的LLM服务,提高用户对LLM API服务的信任度,促进LLM技术的广泛应用。未来,该技术还可以扩展到其他AI模型服务,例如图像识别、语音识别等。
📄 摘要(原文)
Commercial Large Language Model (LLM) APIs create a fundamental trust problem: users pay for specific models but have no guarantee that providers deliver them faithfully. Providers may covertly substitute cheaper alternatives (e.g., quantized versions, smaller models) to reduce costs while maintaining advertised pricing. We formalize this model substitution problem and systematically evaluate detection methods under realistic adversarial conditions. Our empirical analysis reveals that software-only methods are fundamentally unreliable: statistical tests on text outputs are query-intensive and fail against subtle substitutions, while methods using log probabilities are defeated by inherent inference nondeterminism in production environments. We argue that this verification gap can be more effectively closed with hardware-level security. We propose and evaluate the use of Trusted Execution Environments (TEEs) as one practical and robust solution. Our findings demonstrate that TEEs can provide provable cryptographic guarantees of model integrity with only a modest performance overhead, offering a clear and actionable path to ensure users get what they pay for. Code is available at https://github.com/sunblaze-ucb/llm-api-audit