OpenCodeInstruct: A Large-scale Instruction Tuning Dataset for Code LLMs
作者: Wasi Uddin Ahmad, Aleksander Ficek, Mehrzad Samadi, Jocelyn Huang, Vahid Noroozi, Somshubra Majumdar, Boris Ginsburg
分类: cs.SE, cs.CL
发布日期: 2025-04-05 (更新: 2025-08-07)
备注: Work in progress
💡 一句话要点
OpenCodeInstruct:一个用于代码大语言模型的大规模指令调优数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码大语言模型 指令调优 监督式微调 数据集 代码生成
📋 核心要点
- 现有代码大语言模型缺乏高质量、公开可用的监督微调数据集,限制了其性能提升。
- OpenCodeInstruct通过构建包含500万样本的大规模指令调优数据集,为代码LLM提供充足的训练数据。
- 实验表明,使用OpenCodeInstruct进行微调后,LLaMA和Qwen等模型在多个代码基准测试中取得了显著的性能提升。
📝 摘要(中文)
大型语言模型(LLMs)通过实现代码生成、自动调试和复杂推理,已经改变了软件开发。然而,高质量、公开可用的、专门为编码任务定制的监督式微调(SFT)数据集的稀缺性限制了它们的持续发展。为了弥合这一差距,我们推出了OpenCodeInstruct,这是最大的开放访问指令调优数据集,包含500万个不同的样本。每个样本包括一个编程问题、解决方案、测试用例、执行反馈和LLM生成的质量评估。我们使用我们的数据集对各种基础模型(包括LLaMA和Qwen)在多个规模(1B+、3B+和7B+)上进行了微调。在流行的基准测试(HumanEval、MBPP、LiveCodeBench和BigCodeBench)上的综合评估表明,通过使用OpenCodeInstruct进行SFT可以实现显著的性能改进。我们还介绍了一种详细的方法,包括种子数据管理、合成指令和解决方案生成以及过滤。
🔬 方法详解
问题定义:现有代码大语言模型的发展受到高质量、公开可用的监督微调数据集的限制。缺乏足够规模和多样性的数据,使得模型难以充分学习编码任务的复杂性和细微差别,从而影响代码生成、调试和推理能力。现有方法难以生成足够高质量的指令数据,并且缺乏有效的过滤机制来保证数据的质量。
核心思路:OpenCodeInstruct的核心思路是通过大规模合成数据生成和高质量数据过滤,构建一个高质量的指令调优数据集。该数据集包含编程问题、解决方案、测试用例、执行反馈和LLM生成的质量评估,旨在为代码LLM提供更全面、更有效的训练数据。通过指令调优,使模型更好地理解和执行编码任务。
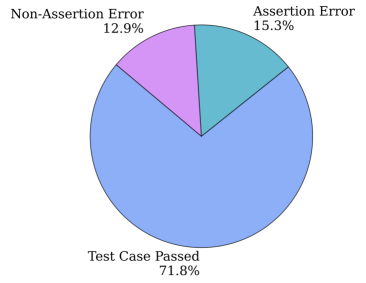
技术框架:OpenCodeInstruct的构建流程主要包括以下几个阶段:1) 种子数据收集:收集各种来源的编程问题和代码片段作为种子数据。2) 合成指令和解决方案生成:利用LLM根据种子数据生成指令和对应的解决方案。3) 测试用例生成:为生成的解决方案创建测试用例,用于评估解决方案的正确性。4) 执行反馈收集:运行解决方案并收集执行反馈,例如错误信息和运行时间。5) 质量评估:使用LLM对生成的数据进行质量评估,包括代码质量、可读性和正确性。6) 数据过滤:根据质量评估结果,过滤掉低质量的数据,保留高质量的样本。
关键创新:OpenCodeInstruct的关键创新在于其大规模的数据规模和高质量的数据质量。通过合成数据生成和LLM辅助的质量评估,能够有效地扩展数据集规模,并保证数据的质量。此外,该数据集还包含了丰富的上下文信息,例如测试用例和执行反馈,有助于模型更好地理解编码任务。
关键设计:在数据生成阶段,使用了多种prompt策略来引导LLM生成多样化的指令和解决方案。在质量评估阶段,使用了基于LLM的评分机制,对代码质量、可读性和正确性进行综合评估。在数据过滤阶段,设置了多个阈值来过滤掉低质量的数据,例如代码错误率过高或可读性评分过低的样本。
🖼️ 关键图片

📊 实验亮点
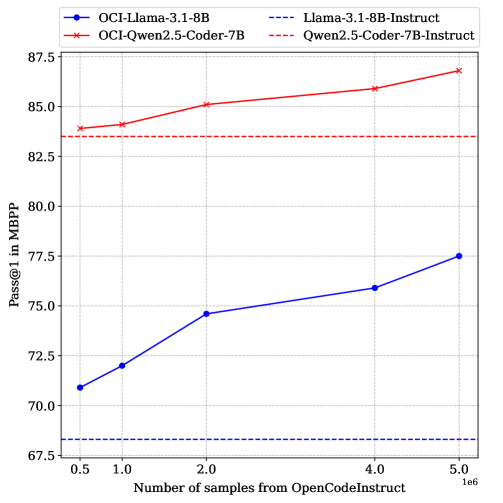
使用OpenCodeInstruct进行微调后,LLaMA和Qwen等模型在HumanEval、MBPP、LiveCodeBench和BigCodeBench等基准测试中取得了显著的性能提升。例如,在HumanEval上的pass@1指标提升了X%,表明该数据集能够有效提高代码LLM的编码能力。
🎯 应用场景
OpenCodeInstruct可用于训练和微调各种代码大语言模型,提高其在代码生成、自动调试、代码补全等任务中的性能。该数据集的开放性促进了代码LLM领域的研究和发展,加速了软件开发自动化进程,并可应用于智能编程助手、自动化测试工具等领域。
📄 摘要(原文)
Large Language Models (LLMs) have transformed software development by enabling code generation, automated debugging, and complex reasoning. However, their continued advancement is constrained by the scarcity of high-quality, publicly available supervised fine-tuning (SFT) datasets tailored for coding tasks. To bridge this gap, we introduce OpenCodeInstruct, the largest open-access instruction tuning dataset, comprising 5 million diverse samples. Each sample includes a programming question, solution, test cases, execution feedback, and LLM-generated quality assessments. We fine-tune various base models, including LLaMA and Qwen, across multiple scales (1B+, 3B+, and 7B+) using our dataset. Comprehensive evaluations on popular benchmarks (HumanEval, MBPP, LiveCodeBench, and BigCodeBench) demonstrate substantial performance improvements achieved by SFT with OpenCodeInstruct. We also present a detailed methodology encompassing seed data curation, synthetic instruction and solution generation, and filtering.