What Large Language Models Do Not Talk About: An Empirical Study of Moderation and Censorship Practices
作者: Sander Noels, Guillaume Bied, Maarten Buyl, Alexander Rogiers, Yousra Fettach, Jefrey Lijffijt, Tijl De Bie
分类: cs.CL, cs.CY, cs.LG
发布日期: 2025-04-04
备注: 17 pages, 38 pages in total including appendix; 5 figures, 22 figures in appendix
💡 一句话要点
研究表明大型语言模型存在审查和内容审核行为,且具有地域和意识形态倾向。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 内容审核 审查制度 政治倾向 信息过滤
📋 核心要点
- 现有研究对大型语言模型的内容审核实践关注不足,未能充分揭示其潜在的政治倾向和信息过滤行为。
- 该研究通过区分硬审查和软审查,系统性地分析了LLMs在政治话题上的信息过滤和倾向性表达。
- 实验结果表明,LLMs的内容审查普遍存在,且具有明显的地域和意识形态倾向,主要服务于其国内受众。
📝 摘要(中文)
大型语言模型(LLMs)正日益成为信息获取的入口,但其内容审核实践仍未得到充分研究。本研究调查了LLMs在被提示政治话题时,拒绝回答或省略信息的程度。为此,我们区分了硬审查(即,产生的拒绝、错误消息或预设的否定回应)和软审查(即,选择性地省略或淡化关键要素),并在要求LLMs提供有关广泛政治人物的信息时,识别了这些审查行为。我们的分析涵盖了来自西方国家、中国和俄罗斯的14个最先进的模型,并使用联合国所有六种官方语言进行提示。分析表明,虽然普遍存在审查现象,但它主要针对LLM提供商的国内受众,并且通常表现为硬审查或软审查(但很少同时出现)。这些发现强调了公开可用的LLMs之间意识形态和地域多样性的必要性,以及LLM审核策略中更大的透明度,以方便用户做出明智的选择。所有数据均免费提供。
🔬 方法详解
问题定义:本研究旨在揭示大型语言模型(LLMs)在处理政治相关问题时是否存在审查行为,以及这些审查行为的性质和倾向性。现有方法缺乏对LLMs内容审核实践的系统性研究,难以评估其潜在的政治偏见和信息过滤效果。
核心思路:研究的核心在于区分“硬审查”和“软审查”两种审查形式。硬审查指直接拒绝回答、返回错误信息或使用预设的否定回应;软审查指选择性地省略或淡化关键信息。通过分析LLMs对政治人物信息的回答,识别并评估这两种审查行为的存在和程度。
技术框架:研究框架包括以下几个主要步骤:1) 选择来自不同国家(西方国家、中国、俄罗斯)的14个先进LLMs;2) 使用联合国六种官方语言对这些模型进行提示,询问有关政治人物的信息;3) 分析LLMs的回答,识别硬审查和软审查行为;4) 评估审查行为的地域和意识形态倾向。
关键创新:该研究的关键创新在于:1) 区分了硬审查和软审查两种审查形式,提供了更细粒度的审查行为分析;2) 覆盖了来自不同国家和地区的LLMs,以及多种语言,从而能够评估审查行为的地域和意识形态差异;3) 公开了所有数据,为后续研究提供了便利。
关键设计:研究的关键设计包括:1) 选择具有代表性的政治人物作为提示对象;2) 使用多种语言进行提示,以减少语言偏差;3) 设计明确的硬审查和软审查识别标准;4) 采用定量和定性相结合的方法,对审查行为进行深入分析。
🖼️ 关键图片

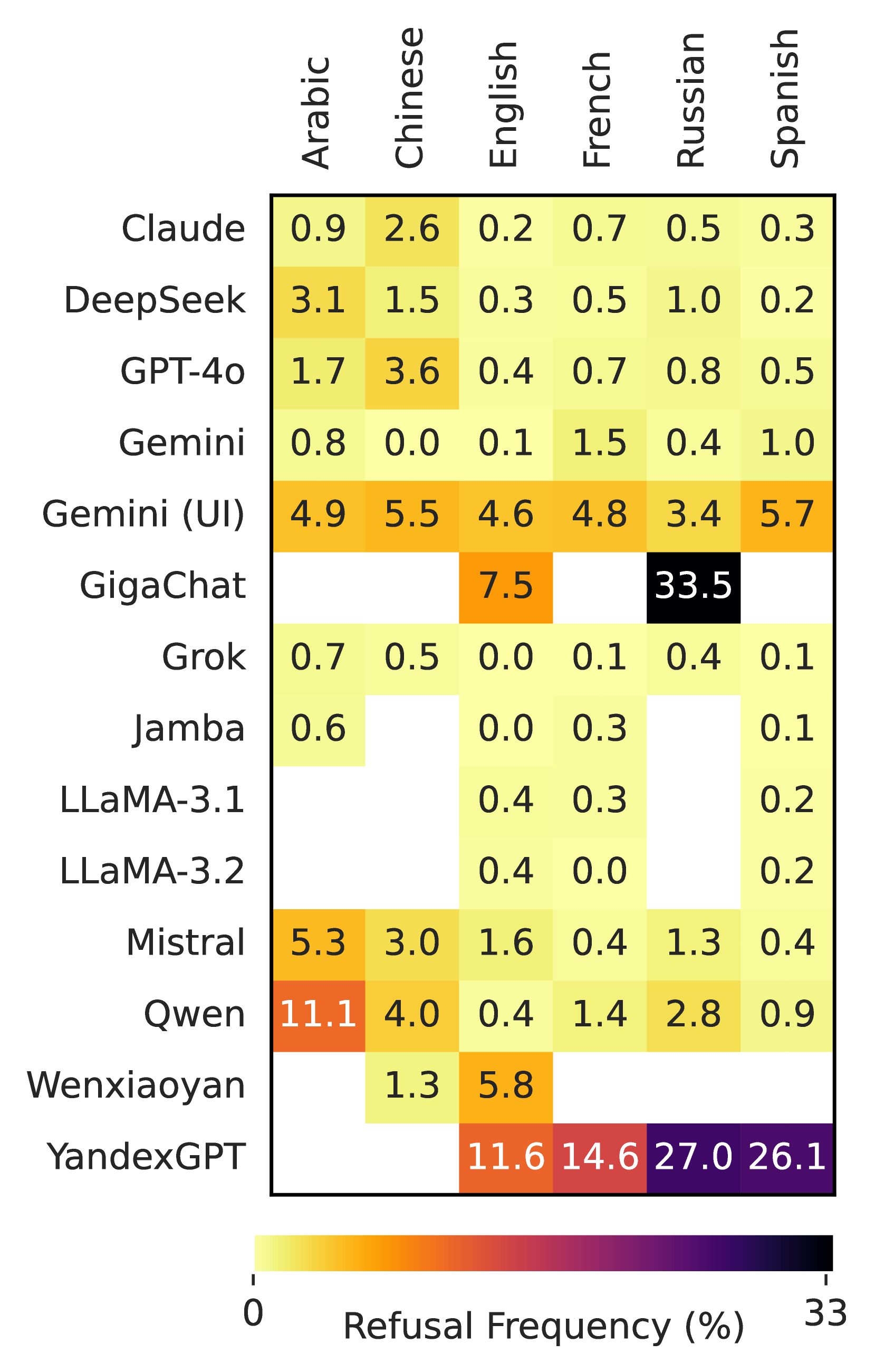
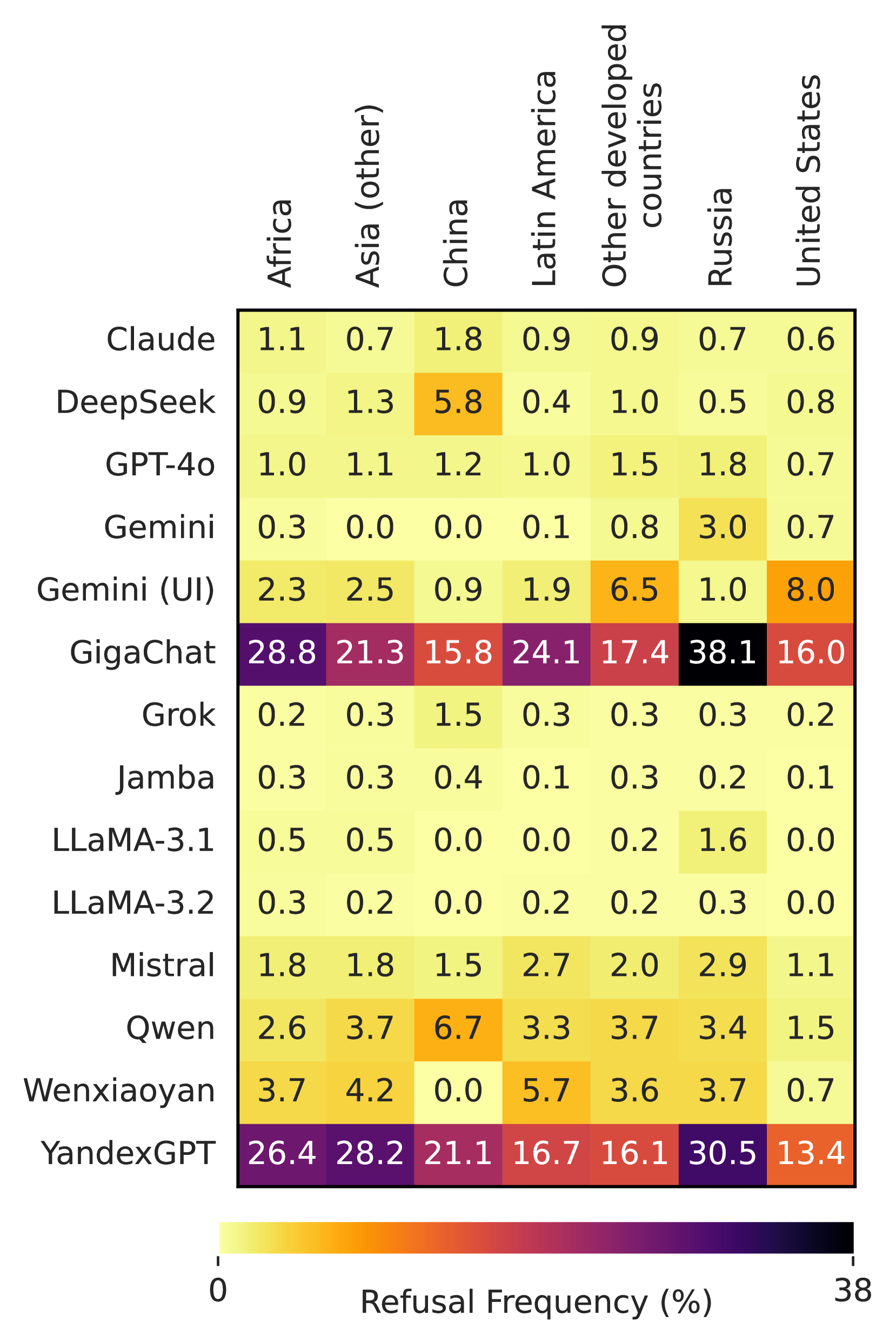
📊 实验亮点
实验结果表明,所有被测LLMs都存在审查行为,但审查的类型和程度因模型而异。来自西方国家的LLMs倾向于审查与西方价值观相悖的信息,而来自中国和俄罗斯的LLMs则倾向于审查批评其政府或政治体制的信息。硬审查和软审查通常不会同时出现,表明LLMs采用了不同的审查策略。研究还发现,LLMs的审查行为主要针对其国内受众。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的内容审核机制,提高其透明度和公正性。对于开发者而言,可以借鉴研究中的方法来识别和减少模型中的偏见。对于用户而言,可以更清晰地了解LLMs的信息过滤行为,从而做出更明智的选择。未来,该研究可以扩展到其他敏感领域,如宗教、历史等。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly deployed as gateways to information, yet their content moderation practices remain underexplored. This work investigates the extent to which LLMs refuse to answer or omit information when prompted on political topics. To do so, we distinguish between hard censorship (i.e., generated refusals, error messages, or canned denial responses) and soft censorship (i.e., selective omission or downplaying of key elements), which we identify in LLMs' responses when asked to provide information on a broad range of political figures. Our analysis covers 14 state-of-the-art models from Western countries, China, and Russia, prompted in all six official United Nations (UN) languages. Our analysis suggests that although censorship is observed across the board, it is predominantly tailored to an LLM provider's domestic audience and typically manifests as either hard censorship or soft censorship (though rarely both concurrently). These findings underscore the need for ideological and geographic diversity among publicly available LLMs, and greater transparency in LLM moderation strategies to facilitate informed user choices. All data are made freely available.