Sample, Don't Search: Rethinking Test-Time Alignment for Language Models
作者: Gonçalo Faria, Noah A. Smith
分类: cs.CL, cs.LG, stat.ML
发布日期: 2025-04-04 (更新: 2025-12-18)
💡 一句话要点
提出QAlign,通过采样而非搜索优化语言模型在测试时的对齐问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型对齐 测试时优化 马尔可夫链蒙特卡洛 奖励模型 文本生成
📋 核心要点
- 现有测试时搜索方法依赖奖励模型,但过度优化不完善的奖励代理导致性能随计算规模扩大而下降。
- QAlign通过采样逼近最优对齐分布,利用MCMC文本生成,无需修改模型或访问logits即可提升对齐效果。
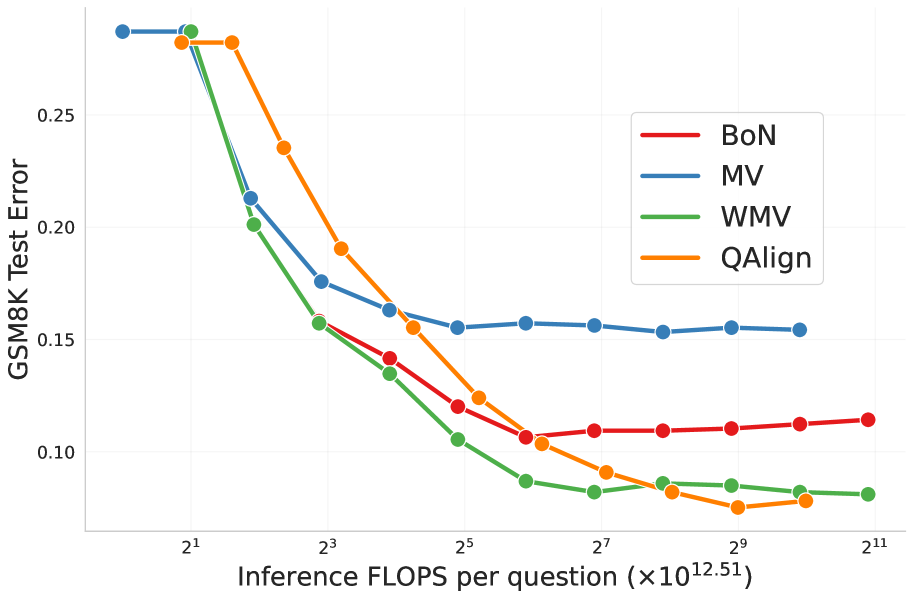
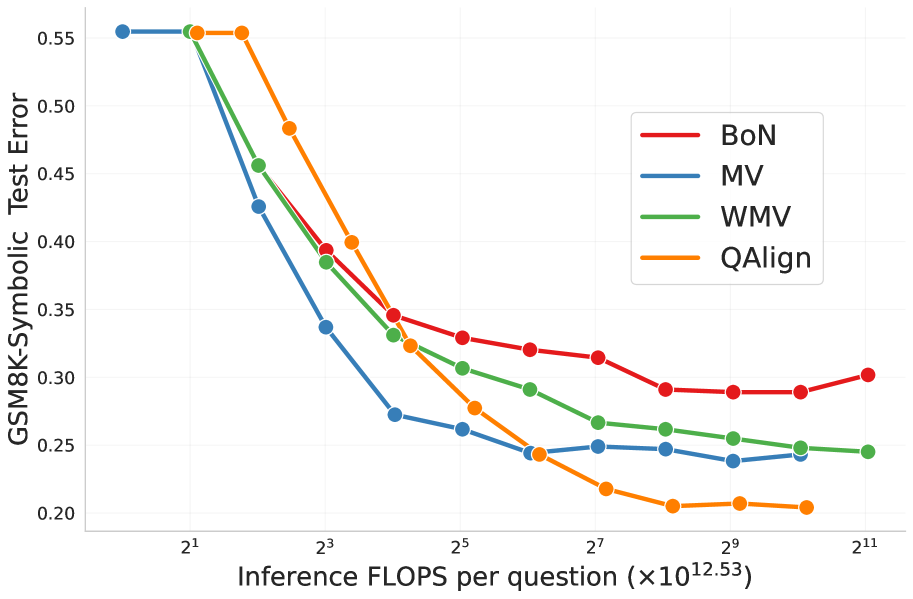
- 实验表明,QAlign在数学推理和通用数据集上,使用不同奖励模型均优于现有测试时计算方法。
📝 摘要(中文)
本文提出了一种新的测试时对齐方法QAlign,旨在提升语言模型在测试阶段的性能,尤其是在由于计算限制或模型权重私有性而无法进行微调的情况下。现有基于奖励模型(RM)的测试时搜索方法,随着计算规模的扩大,由于过度优化不完善的奖励代理而导致质量下降。QAlign通过增加测试时计算,收敛到每个prompt的最佳对齐分布的采样。该方法利用了文本生成的马尔可夫链蒙特卡洛(MCMC)的最新进展,无需修改底层模型或访问logits即可实现更好的对齐输出。在数学推理基准测试(GSM8K和GSM-Symbolic)上,使用特定于任务的RM,QAlign优于现有的测试时计算方法,如best-of-n和多数投票。此外,当应用于基于Tulu 3偏好数据集训练的更真实的RM时,QAlign在多个数据集(GSM8K、MATH500、IFEval、MMLU-Redux和TruthfulQA)上优于直接偏好优化(DPO)、best-of-n、多数投票和加权多数投票。QAlign为在测试时使用额外计算对齐语言模型提供了一种实用的解决方案,扩展了无需进一步训练即可从现成语言模型获得的能力。
🔬 方法详解
问题定义:论文旨在解决语言模型在测试时对齐的问题。现有方法,如best-of-n和多数投票,依赖于奖励模型进行搜索,但随着计算资源的增加,这些方法容易过度拟合奖励模型本身,导致生成质量下降。此外,这些方法通常需要访问模型的logits,限制了其在模型权重私有场景下的应用。
核心思路:QAlign的核心思路是避免直接搜索,而是通过采样的方式逼近最优的对齐分布。具体来说,QAlign利用马尔可夫链蒙特卡洛(MCMC)方法,从一个初始文本出发,逐步迭代生成新的文本,并根据奖励模型给出的奖励值来决定是否接受新的文本。通过多次迭代,最终生成的文本将更符合奖励模型的偏好,从而实现对齐。
技术框架:QAlign的整体框架可以分为以下几个步骤:1) 使用语言模型生成一个初始文本;2) 使用MCMC方法,基于当前文本生成一个新的候选文本;3) 使用奖励模型评估候选文本的质量;4) 根据奖励值,决定是否接受新的文本;5) 重复步骤2-4,直到达到预定的迭代次数。
关键创新:QAlign的关键创新在于将MCMC方法应用于语言模型的测试时对齐。与传统的搜索方法相比,QAlign避免了直接优化奖励模型,而是通过采样的方式逼近最优分布,从而降低了过度拟合的风险。此外,QAlign不需要访问模型的logits,使其可以应用于模型权重私有的场景。
关键设计:QAlign的关键设计包括:1) 使用合适的MCMC采样算法,例如Metropolis-Hastings算法;2) 设计合适的奖励函数,以准确评估文本的质量;3) 设置合适的迭代次数,以保证采样的收敛性。论文中具体使用的MCMC算法和奖励函数以及迭代次数等细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,QAlign在数学推理基准测试(GSM8K和GSM-Symbolic)上,使用特定于任务的RM,优于现有的测试时计算方法,如best-of-n和多数投票。更重要的是,当应用于基于Tulu 3偏好数据集训练的更真实的RM时,QAlign在多个数据集(GSM8K、MATH500、IFEval、MMLU-Redux和TruthfulQA)上优于直接偏好优化(DPO)、best-of-n、多数投票和加权多数投票,证明了其在通用场景下的有效性。
🎯 应用场景
QAlign具有广泛的应用前景,可以应用于各种需要语言模型对齐的场景,例如对话生成、文本摘要、机器翻译等。尤其是在模型权重私有或计算资源有限的情况下,QAlign提供了一种有效的测试时对齐方法,可以提升语言模型的性能和安全性。该方法可以帮助企业更好地利用现有的语言模型,而无需进行昂贵的微调。
📄 摘要(原文)
Increasing test-time computation has emerged as a promising direction for improving language model performance, particularly in scenarios where model finetuning is impractical or impossible due to computational constraints or private model weights. However, existing test-time search methods using a reward model (RM) often degrade in quality as compute scales, due to the over-optimization of what are inherently imperfect reward proxies. We introduce QAlign, a new test-time alignment approach. As we scale test-time compute, QAlign converges to sampling from the optimal aligned distribution for each individual prompt. By adopting recent advances in Markov chain Monte Carlo for text generation, our method enables better-aligned outputs without modifying the underlying model or even requiring logit access. We demonstrate the effectiveness of QAlign on mathematical reasoning benchmarks (GSM8K and GSM-Symbolic) using a task-specific RM, showing consistent improvements over existing test-time compute methods like best-of-n and majority voting. Furthermore, when applied with more realistic RMs trained on the Tulu 3 preference dataset, QAlign outperforms direct preference optimization (DPO), best-of-n, majority voting, and weighted majority voting on a diverse range of datasets (GSM8K, MATH500, IFEval, MMLU-Redux, and TruthfulQA). A practical solution to aligning language models at test time using additional computation without degradation, our approach expands the limits of the capability that can be obtained from off-the-shelf language models without further training.