Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
作者: NVIDIA, :, Aaron Blakeman, Aarti Basant, Abhinav Khattar, Adithya Renduchintala, Akhiad Bercovich, Aleksander Ficek, Alexis Bjorlin, Ali Taghibakhshi, Amala Sanjay Deshmukh, Ameya Sunil Mahabaleshwarkar, Andrew Tao, Anna Shors, Ashwath Aithal, Ashwin Poojary, Ayush Dattagupta, Balaram Buddharaju, Bobby Chen, Boris Ginsburg, Boxin Wang, Brandon Norick, Brian Butterfield, Bryan Catanzaro, Carlo del Mundo, Chengyu Dong, Christine Harvey, Christopher Parisien, Dan Su, Daniel Korzekwa, Danny Yin, Daria Gitman, David Mosallanezhad, Deepak Narayanan, Denys Fridman, Dima Rekesh, Ding Ma, Dmytro Pykhtar, Dong Ahn, Duncan Riach, Dusan Stosic, Eileen Long, Elad Segal, Ellie Evans, Eric Chung, Erick Galinkin, Evelina Bakhturina, Ewa Dobrowolska, Fei Jia, Fuxiao Liu, Gargi Prasad, Gerald Shen, Guilin Liu, Guo Chen, Haifeng Qian, Helen Ngo, Hongbin Liu, Hui Li, Igor Gitman, Ilia Karmanov, Ivan Moshkov, Izik Golan, Jan Kautz, Jane Polak Scowcroft, Jared Casper, Jarno Seppanen, Jason Lu, Jason Sewall, Jiaqi Zeng, Jiaxuan You, Jimmy Zhang, Jing Zhang, Jining Huang, Jinze Xue, Jocelyn Huang, Joey Conway, John Kamalu, Jon Barker, Jonathan Cohen, Joseph Jennings, Jupinder Parmar, Karan Sapra, Kari Briski, Kateryna Chumachenko, Katherine Luna, Keshav Santhanam, Kezhi Kong, Kirthi Sivamani, Krzysztof Pawelec, Kumar Anik, Kunlun Li, Lawrence McAfee, Leon Derczynski, Lindsey Pavao, Luis Vega, Lukas Voegtle, Maciej Bala, Maer Rodrigues de Melo, Makesh Narsimhan Sreedhar, Marcin Chochowski, Markus Kliegl, Marta Stepniewska-Dziubinska, Matthieu Le, Matvei Novikov, Mehrzad Samadi, Michael Andersch, Michael Evans, Miguel Martinez, Mike Chrzanowski, Mike Ranzinger, Mikolaj Blaz, Misha Smelyanskiy, Mohamed Fawzy, Mohammad Shoeybi, Mostofa Patwary, Nayeon Lee, Nima Tajbakhsh, Ning Xu, Oleg Rybakov, Oleksii Kuchaiev, Olivier Delalleau, Osvald Nitski, Parth Chadha, Pasha Shamis, Paulius Micikevicius, Pavlo Molchanov, Peter Dykas, Philipp Fischer, Pierre-Yves Aquilanti, Piotr Bialecki, Prasoon Varshney, Pritam Gundecha, Przemek Tredak, Rabeeh Karimi, Rahul Kandu, Ran El-Yaniv, Raviraj Joshi, Roger Waleffe, Ruoxi Zhang, Sabrina Kavanaugh, Sahil Jain, Samuel Kriman, Sangkug Lym, Sanjeev Satheesh, Saurav Muralidharan, Sean Narenthiran, Selvaraj Anandaraj, Seonmyeong Bak, Sergey Kashirsky, Seungju Han, Shantanu Acharya, Shaona Ghosh, Sharath Turuvekere Sreenivas, Sharon Clay, Shelby Thomas, Shrimai Prabhumoye, Shubham Pachori, Shubham Toshniwal, Shyamala Prayaga, Siddhartha Jain, Sirshak Das, Slawek Kierat, Somshubra Majumdar, Song Han, Soumye Singhal, Sriharsha Niverty, Stefania Alborghetti, Suseella Panguluri, Swetha Bhendigeri, Syeda Nahida Akter, Szymon Migacz, Tal Shiri, Terry Kong, Timo Roman, Tomer Ronen, Trisha Saar, Tugrul Konuk, Tuomas Rintamaki, Tyler Poon, Ushnish De, Vahid Noroozi, Varun Singh, Vijay Korthikanti, Vitaly Kurin, Wasi Uddin Ahmad, Wei Du, Wei Ping, Wenliang Dai, Wonmin Byeon, Xiaowei Ren, Yao Xu, Yejin Choi, Yian Zhang, Ying Lin, Yoshi Suhara, Zhiding Yu, Zhiqi Li, Zhiyu Li, Zhongbo Zhu, Zhuolin Yang, Zijia Chen
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-04-04 (更新: 2025-09-05)
💡 一句话要点
提出Nemotron-H混合Mamba-Transformer模型,旨在提升推理效率并保持精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型语言模型 Mamba Transformer 混合架构 推理效率 模型压缩 剪枝 蒸馏
📋 核心要点
- 现有Transformer模型在推理时计算和内存需求随序列长度增加,限制了其在长序列任务中的应用。
- Nemotron-H采用混合架构,用Mamba层替换Transformer中的自注意力层,实现恒定的推理计算和内存开销。
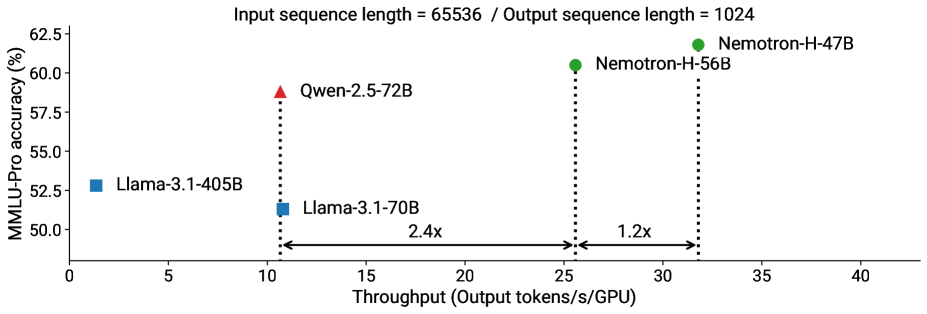
- 实验表明,Nemotron-H在精度上与主流Transformer模型相当,同时推理速度提升显著,最高可达3倍。
📝 摘要(中文)
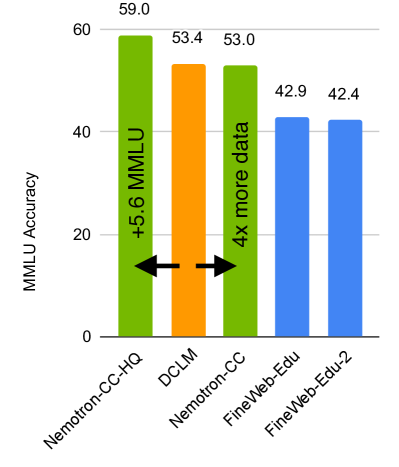
本文介绍Nemotron-H,一个包含8B和56B/47B参数规模的混合Mamba-Transformer模型家族,其设计目标是在保证精度水平的前提下,降低推理成本。通过将传统Transformer模型架构中的大部分自注意力层替换为Mamba层,实现了每个生成token的恒定计算和恒定内存需求。实验表明,Nemotron-H模型在精度上可与其他同等规模的先进开源Transformer模型(如Qwen-2.5-7B/72B和Llama-3.1-8B/70B)相媲美甚至更优,同时推理速度提升高达3倍。为了进一步提高推理速度并减少推理时所需的内存,我们使用一种名为MiniPuzzle的全新剪枝和蒸馏压缩技术,从56B模型创建了Nemotron-H-47B-Base。Nemotron-H-47B-Base实现了与56B模型相似的精度,但推理速度提高了20%。此外,我们还引入了一种基于FP8的训练方案,并表明它可以达到与基于BF16的训练相当的结果。该方案用于训练56B模型。我们正在发布Nemotron-H基础模型检查点,并提供Hugging Face和NeMo的支持。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)依赖于Transformer架构,其自注意力机制在推理阶段面临计算和内存瓶颈,尤其是在处理长序列时。随着模型规模的增大,推理成本也显著增加,限制了其在资源受限环境中的部署。因此,如何在保持模型精度的前提下,降低推理成本,是当前LLM研究的一个重要挑战。
核心思路:Nemotron-H的核心思路是将Transformer架构中的大部分自注意力层替换为Mamba层。Mamba是一种选择性状态空间模型(Selective State Space Model, S6),其计算复杂度与序列长度呈线性关系,而非Transformer的平方关系。通过这种混合架构,Nemotron-H旨在结合Transformer的强大表示能力和Mamba的高效推理特性。
技术框架:Nemotron-H的整体架构是一个混合的Mamba-Transformer模型。该架构包含多个层,其中大部分层是Mamba层,而少部分层保留了Transformer的自注意力机制。具体来说,模型首先通过嵌入层将输入token转换为向量表示,然后经过一系列的Mamba和Transformer层交替处理。最后,通过一个线性层将隐藏状态映射到输出token的概率分布。为了进一步压缩模型,论文还提出了一种名为MiniPuzzle的剪枝和蒸馏技术,用于将56B模型压缩到47B模型。
关键创新:Nemotron-H的关键创新在于其混合架构,它有效地结合了Transformer和Mamba的优势。Mamba层负责处理大部分序列信息,从而降低了推理成本,而Transformer层则保留了模型的表示能力。此外,MiniPuzzle剪枝和蒸馏技术也是一个重要的创新,它能够在不显著降低模型精度的前提下,进一步压缩模型规模,提高推理速度。
关键设计:在Nemotron-H中,Mamba层和Transformer层的比例是一个关键的设计参数。论文通过实验确定了最佳的比例,以在精度和推理速度之间取得平衡。此外,MiniPuzzle剪枝和蒸馏技术也涉及一些关键的设计细节,例如剪枝的比例、蒸馏的温度等。论文还引入了一种基于FP8的训练方案,以进一步降低训练成本。具体来说,该方案使用FP8格式存储模型参数和激活值,从而减少了内存占用和计算量。
🖼️ 关键图片

📊 实验亮点
Nemotron-H模型在精度上与Qwen-2.5-7B/72B和Llama-3.1-8B/70B等同等规模的先进开源Transformer模型相当甚至更优,同时推理速度提升高达3倍。通过MiniPuzzle技术压缩后的Nemotron-H-47B-Base模型,在保持与56B模型相似精度的前提下,推理速度提高了20%。
🎯 应用场景
Nemotron-H适用于各种需要高效推理的大型语言模型应用场景,例如:移动设备上的自然语言处理、低延迟的对话系统、以及资源受限环境下的文本生成和理解。该模型能够降低部署成本,并加速AI在边缘设备上的普及。
📄 摘要(原文)
As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. We are releasing Nemotron-H base model checkpoints with support in Hugging Face and NeMo.