Align to Structure: Aligning Large Language Models with Structural Information
作者: Zae Myung Kim, Anand Ramachandran, Farideh Tavazoee, Joo-Kyung Kim, Oleg Rokhlenko, Dongyeop Kang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-04-04
🔗 代码/项目: GITHUB
💡 一句话要点
提出结构对齐方法,提升大型语言模型在长文本生成中的连贯性和结构性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本生成 结构对齐 强化学习 语言模型 话语结构 近端策略优化 奖励模型
📋 核心要点
- 大型语言模型在长文本生成中缺乏层级规划和结构化组织,导致连贯性不足。
- 提出“结构对齐”方法,通过强化学习将语言学话语框架融入LLM,引导模型生成结构化文本。
- 实验表明,该方法在论文生成和长文档摘要任务中,优于标准模型和RLHF增强模型。
📝 摘要(中文)
大型语言模型(LLMs)在生成长篇连贯文本方面仍面临挑战,因为它们缺乏层级规划和结构化组织。本文提出了一种名为“结构对齐”的新方法,旨在将LLMs与类人话语结构对齐,从而增强长文本生成能力。通过将语言学基础的话语框架集成到强化学习中,该方法引导模型生成连贯且组织良好的输出。在近端策略优化框架内,采用密集奖励机制,根据话语相对于人类写作的独特性,分配细粒度的token级别奖励。评估了两种互补的奖励模型:第一种通过对表面文本特征进行评分来提高可读性,从而提供显式结构;第二种通过分析分层话语模式中的全局话语模式来加强更深层次的连贯性和修辞复杂性。在论文生成和长文档摘要等任务中,该方法优于标准模型和经过RLHF增强的模型。所有训练数据和代码将在https://github.com/minnesotanlp/struct_align公开。
🔬 方法详解
问题定义:大型语言模型在生成长文本时,难以保持连贯性和结构性,缺乏类似人类写作的层级规划能力。现有方法难以有效地将语言学知识融入到模型训练中,导致生成文本的质量不高。
核心思路:核心思想是将语言学中的话语结构框架引入到大型语言模型的训练过程中,通过强化学习的方式,让模型学习人类写作的结构化特征。通过奖励模型来引导模型生成更符合人类写作习惯的文本结构,从而提高生成文本的连贯性和可读性。
技术框架:整体框架基于近端策略优化(PPO)算法。首先,使用大型语言模型生成文本。然后,通过两个奖励模型对生成的文本进行评估,一个奖励模型关注表面文本特征,提高可读性;另一个奖励模型关注全局话语模式,提高连贯性和修辞复杂性。最后,使用PPO算法根据奖励信号更新模型参数,使其能够生成更符合人类写作习惯的文本。
关键创新:关键创新在于将语言学知识融入到强化学习框架中,设计了两个互补的奖励模型,分别从表面结构和深层语义两个层面来引导模型学习。这种方法能够有效地提高生成文本的连贯性和结构性,使其更接近人类写作的水平。
关键设计:采用了密集奖励机制,对每个token都进行奖励,奖励值基于话语相对于人类写作的独特性。使用了两个奖励模型:一个是基于表面文本特征的奖励模型,例如句子长度、段落结构等;另一个是基于分层话语模式的奖励模型,例如论证结构、因果关系等。这些奖励模型的设计是基于语言学理论的,能够有效地引导模型学习人类写作的结构化特征。
🖼️ 关键图片
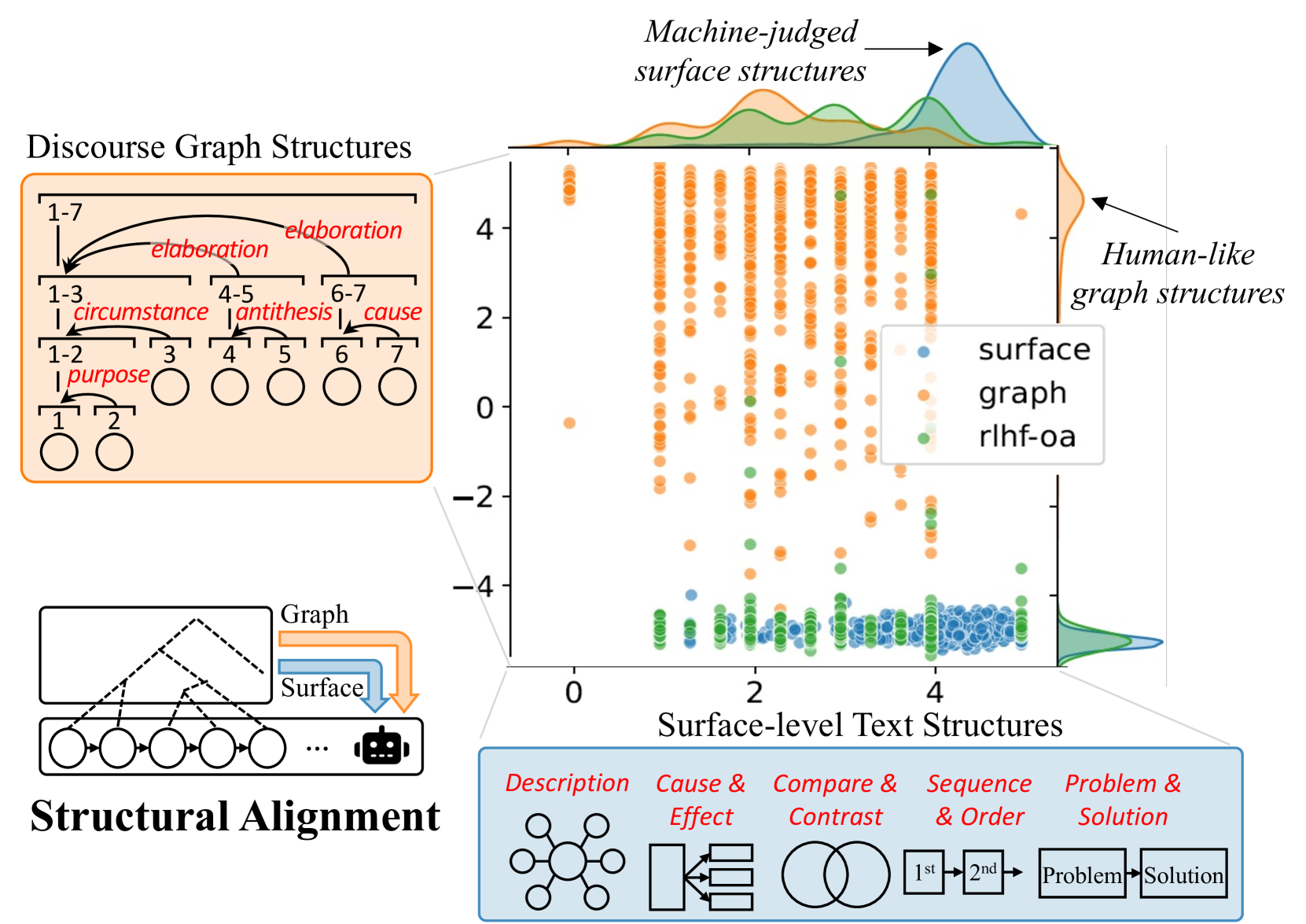
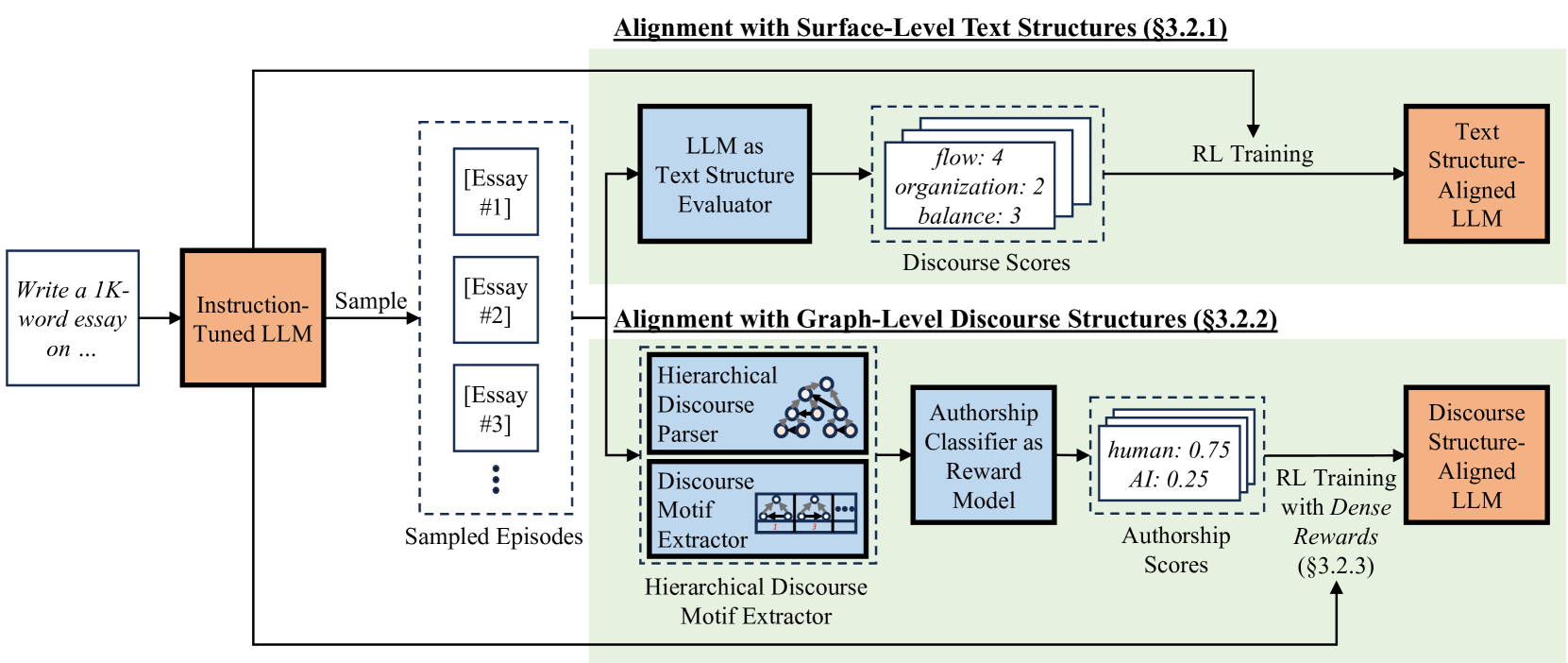
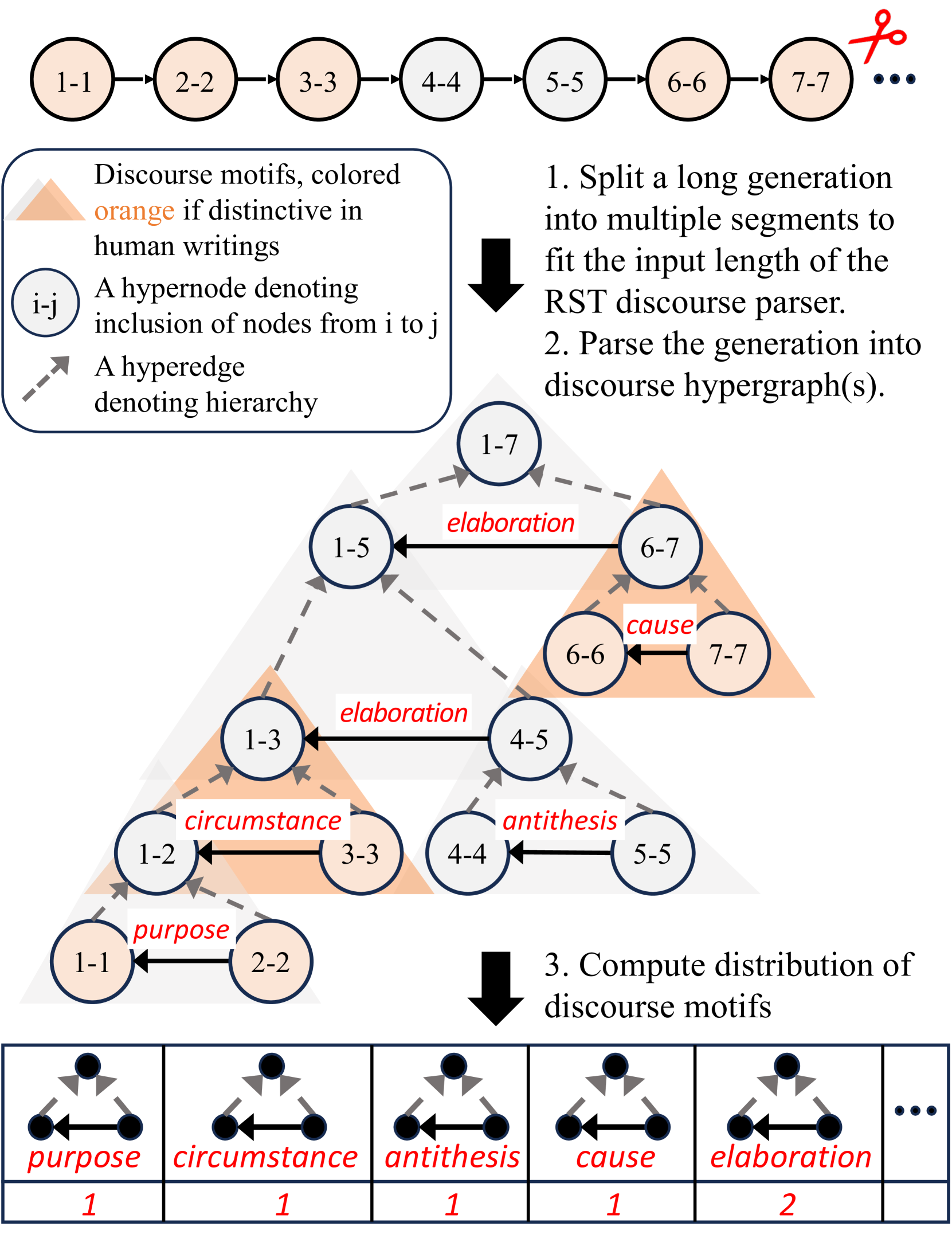
📊 实验亮点
实验结果表明,该方法在论文生成和长文档摘要任务中,显著优于标准模型和经过RLHF增强的模型。具体而言,该方法能够生成更连贯、更结构化的文本,并且在可读性和修辞复杂性方面都有显著提升。实验结果验证了该方法的有效性和优越性。
🎯 应用场景
该研究成果可应用于自动论文写作、长文档摘要、机器翻译等领域。通过提升生成文本的连贯性和结构性,可以提高信息传递的效率和准确性,具有重要的实际应用价值。未来,该方法可以进一步扩展到其他语言和文本类型,并与其他自然语言处理技术相结合,实现更智能化的文本生成。
📄 摘要(原文)
Generating long, coherent text remains a challenge for large language models (LLMs), as they lack hierarchical planning and structured organization in discourse generation. We introduce Structural Alignment, a novel method that aligns LLMs with human-like discourse structures to enhance long-form text generation. By integrating linguistically grounded discourse frameworks into reinforcement learning, our approach guides models to produce coherent and well-organized outputs. We employ a dense reward scheme within a Proximal Policy Optimization framework, assigning fine-grained, token-level rewards based on the discourse distinctiveness relative to human writing. Two complementary reward models are evaluated: the first improves readability by scoring surface-level textual features to provide explicit structuring, while the second reinforces deeper coherence and rhetorical sophistication by analyzing global discourse patterns through hierarchical discourse motifs, outperforming both standard and RLHF-enhanced models in tasks such as essay generation and long-document summarization. All training data and code will be publicly shared at https://github.com/minnesotanlp/struct_align.