AIR: A Systematic Analysis of Annotations, Instructions, and Response Pairs in Preference Dataset
作者: Bingxiang He, Wenbin Zhang, Jiaxi Song, Cheng Qian, Zixuan Fu, Bowen Sun, Ning Ding, Haiwen Hong, Longtao Huang, Hui Xue, Ganqu Cui, Wanxiang Che, Zhiyuan Liu, Maosong Sun
分类: cs.CL
发布日期: 2025-04-04 (更新: 2025-08-31)
备注: Accept at the Conference On Language Modeling (COLM) 2025
💡 一句话要点
AIR框架:通过解耦偏好数据集的注释、指令和响应对,实现高效对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好学习 大型语言模型 数据集构建 对齐 组件分析
📋 核心要点
- 现有偏好学习方法将注释、指令和响应对混淆,无法有效优化数据集。
- AIR框架通过解耦并分别优化偏好数据集的三个核心组件来提升对齐效果。
- 实验表明,结合AIR框架揭示的原则,即使少量数据也能显著提升模型性能。
📝 摘要(中文)
偏好学习对于将大型语言模型(LLMs)与人类价值观对齐至关重要,但其成功依赖于高质量的数据集,该数据集包含三个核心组成部分:偏好Annotations(注释)、Instructions(指令)和Response Pairs(响应对)。目前的方法将这些组件混为一谈,掩盖了它们各自的影响,阻碍了系统优化。本文提出了AIR,一个组件式分析框架,系统地隔离和优化每个组件,同时评估它们的协同效应。通过严格的实验,AIR揭示了可操作的原则:注释的简单性(逐点生成评分)、指令推理的稳定性(基于LLM间方差的过滤)和响应对的质量(适度的边际+高的绝对分数)。当结合这些原则时,即使只有14k高质量的pair,也能比基线方法平均提高+5.3。这项工作将偏好数据集设计从临时扩展转变为组件感知的优化,为高效、可复现的对齐提供了一个蓝图。
🔬 方法详解
问题定义:现有偏好学习数据集构建方法通常将注释、指令和响应对三个关键组成部分混合在一起,无法有效分析每个组件对最终模型性能的影响。这种缺乏针对性的优化阻碍了模型与人类价值观的有效对齐,并且难以复现和改进。
核心思路:AIR框架的核心在于将偏好数据集的构建过程分解为三个独立的组件:注释、指令和响应对。通过分别分析和优化每个组件,并研究它们之间的协同效应,从而更有效地提升偏好学习的效果。这种组件化的方法使得优化过程更加透明和可控。
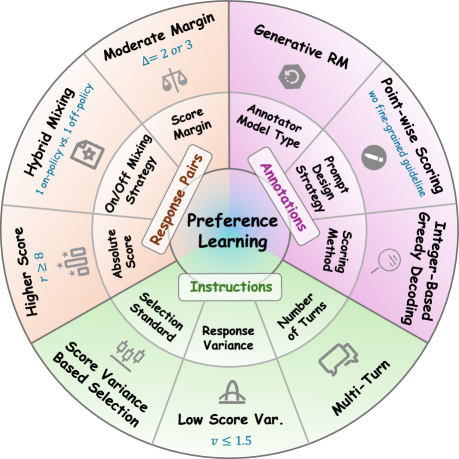
技术框架:AIR框架包含以下几个主要阶段: 1. 数据收集:收集包含指令、多个响应以及人类对这些响应的偏好注释的数据。 2. 组件分离:将数据分解为独立的注释、指令和响应对。 3. 组件分析与优化:针对每个组件,设计相应的评估指标和优化策略。例如,对于注释,研究不同的评分方法;对于指令,评估其在不同LLM上的稳定性;对于响应对,分析边际和绝对分数的影响。 4. 协同效应评估:研究不同组件之间的相互作用,找到最佳的组件组合。 5. 模型训练与评估:使用优化后的数据集训练LLM,并评估其对齐效果。
关键创新:AIR框架最重要的创新在于其组件化的分析方法。通过将偏好数据集分解为独立的组件,可以更精确地识别影响模型性能的关键因素,并针对性地进行优化。与现有方法相比,AIR框架提供了一种更系统、更可控的偏好学习数据集构建方法。
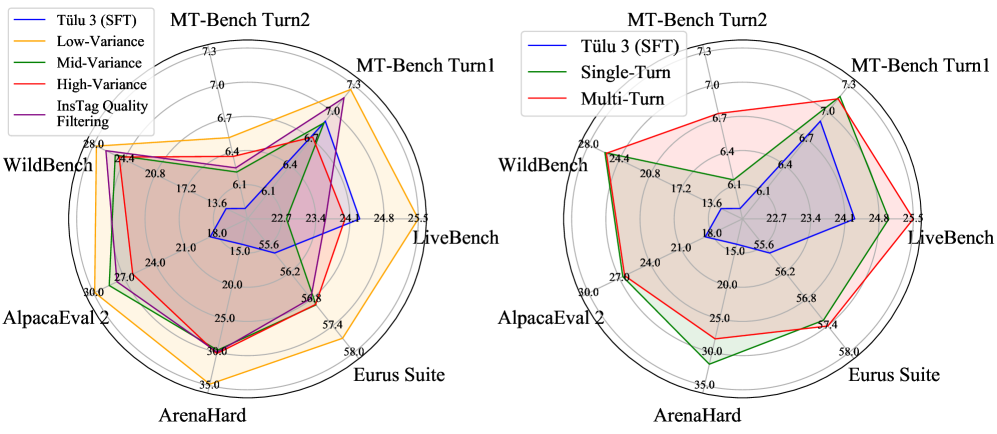
关键设计:AIR框架的关键设计包括: * 注释的简单性:采用逐点生成评分,简化注释过程。 * 指令推理稳定性:使用基于LLM间方差的过滤方法,选择更稳定的指令。 * 响应对质量:关注适度的边际和高的绝对分数,提升响应对的质量。
🖼️ 关键图片
📊 实验亮点
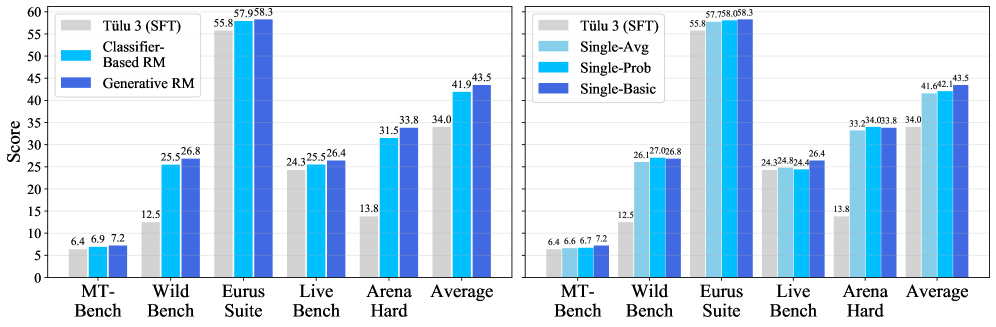
实验结果表明,结合AIR框架揭示的原则,即使只使用14k高质量的pair,也能比基线方法平均提高+5.3。这表明AIR框架能够显著提升偏好学习的效率,减少对大规模数据集的依赖。该结果验证了组件化分析和优化的有效性,为偏好数据集的设计提供了新的思路。
🎯 应用场景
该研究成果可应用于各种需要将大型语言模型与人类价值观对齐的场景,例如对话系统、内容生成、智能助手等。通过AIR框架,可以更高效地构建高质量的偏好数据集,从而提升模型的安全性、可靠性和实用性。未来,该方法可以推广到其他类型的数据集和模型对齐任务中。
📄 摘要(原文)
Preference learning is critical for aligning large language models (LLMs) with human values, yet its success hinges on high-quality datasets comprising three core components: Preference \textbf{A}nnotations, \textbf{I}nstructions, and \textbf{R}esponse Pairs. Current approaches conflate these components, obscuring their individual impacts and hindering systematic optimization. In this work, we propose \textbf{AIR}, a component-wise analysis framework that systematically isolates and optimizes each component while evaluating their synergistic effects. Through rigorous experimentation, AIR reveals actionable principles: annotation simplicity (point-wise generative scoring), instruction inference stability (variance-based filtering across LLMs), and response pair quality (moderate margins + high absolute scores). When combined, these principles yield +5.3 average gains over baseline method, even with only 14k high-quality pairs. Our work shifts preference dataset design from ad hoc scaling to component-aware optimization, offering a blueprint for efficient, reproducible alignment.