Online Difficulty Filtering for Reasoning Oriented Reinforcement Learning
作者: Sanghwan Bae, Jiwoo Hong, Min Young Lee, Hanbyul Kim, JeongYeon Nam, Donghyun Kwak
分类: cs.CL, cs.AI
发布日期: 2025-04-04
💡 一句话要点
提出平衡在线难度过滤方法,提升面向推理的强化学习训练效率与性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 推理能力 课程学习 难度过滤 大型语言模型
📋 核心要点
- RORL训练受奖励稀疏性影响,需要选择合适难度的题目,传统方法依赖静态策略或缺乏理论指导。
- 论文提出平衡在线难度过滤,动态选择模型达到中间精度的题目,最大化训练效率。
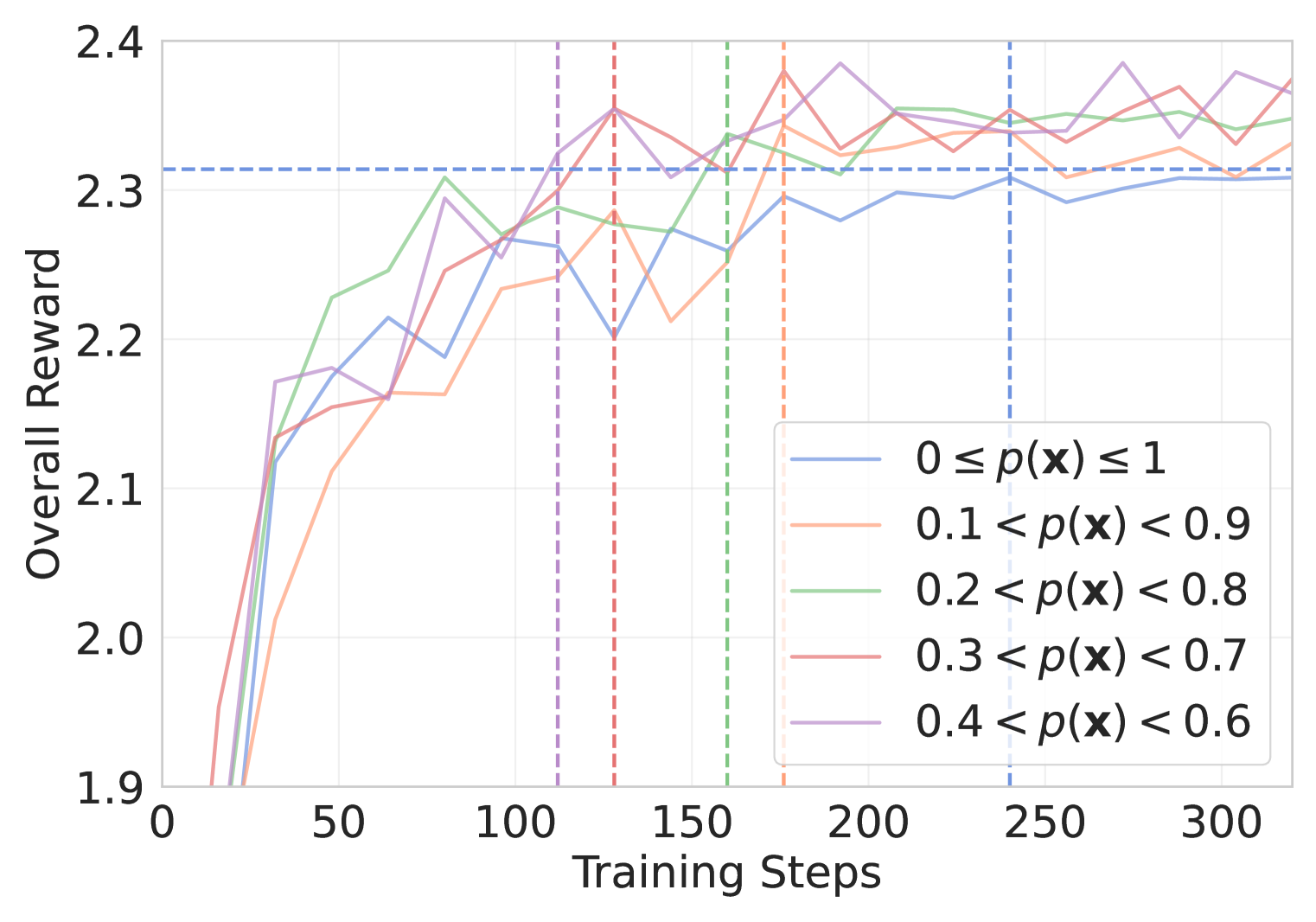
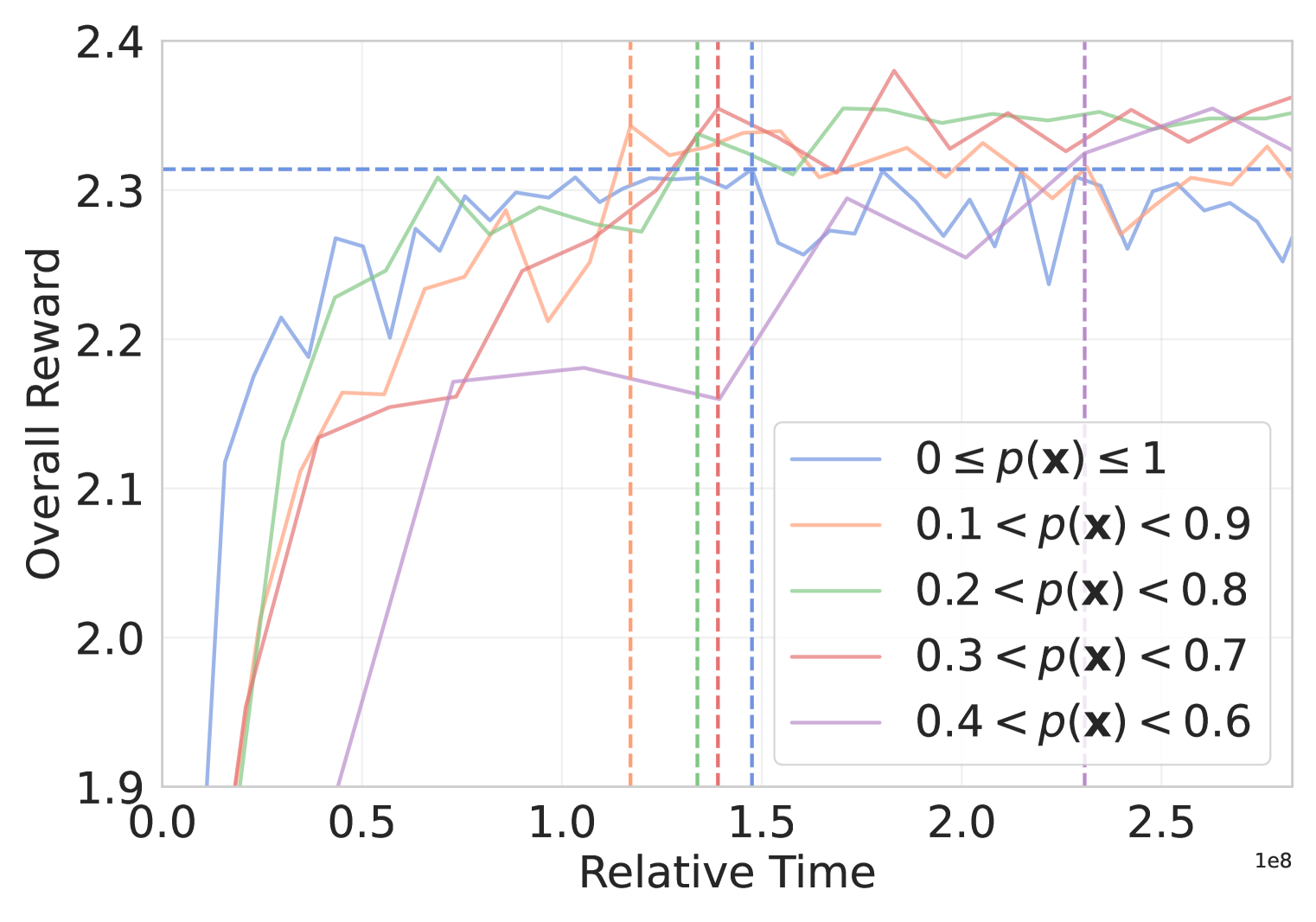
- 实验表明,该方法在数学推理基准测试中显著提升了性能,并在样本效率和训练时间上优于现有方法。
📝 摘要(中文)
面向推理的强化学习(RORL)旨在增强大型语言模型(LLM)的推理能力。然而,由于RORL中的奖励稀疏性,有效的训练高度依赖于选择适当难度的题目。课程学习试图通过调整难度来解决这个问题,但通常依赖于静态策略,即使是最新的在线过滤方法也缺乏理论基础和对其有效性的系统理解。本文从理论和实验上证明,动态地筛选训练模型达到中间精度的题目可以最大化RORL训练的有效性,即平衡在线难度过滤。我们首先推导出初始策略和最优策略之间的KL散度的下界可以用采样精度的方差来表示。基于这些见解,我们表明平衡过滤可以最大化下界,从而获得更好的性能。在五个具有挑战性的数学推理基准测试中,实验结果表明,平衡在线过滤在AIME上产生了额外的10%的提升,平均提升了4%。此外,进一步的分析表明,在样本效率和训练时间效率方面都有所提高,在60%的训练时间和训练集大小内超过了普通GRPO的最大奖励。
🔬 方法详解
问题定义:RORL旨在提升LLM的推理能力,但其奖励稀疏性使得训练非常依赖于所选择问题的难度。现有的课程学习方法,包括静态策略和一些在线过滤方法,要么缺乏理论基础,要么无法有效地选择合适的训练样本,导致训练效率低下和性能提升有限。
核心思路:论文的核心思路是,选择模型能够达到中间精度的题目进行训练,可以最大化训练的有效性。这种“平衡”的难度过滤能够提供更有效的学习信号,避免模型在过于简单或过于困难的题目上浪费计算资源。论文通过理论推导证明,这种平衡过滤可以最大化初始策略和最优策略之间的KL散度的下界,从而引导模型更快地收敛到最优策略。
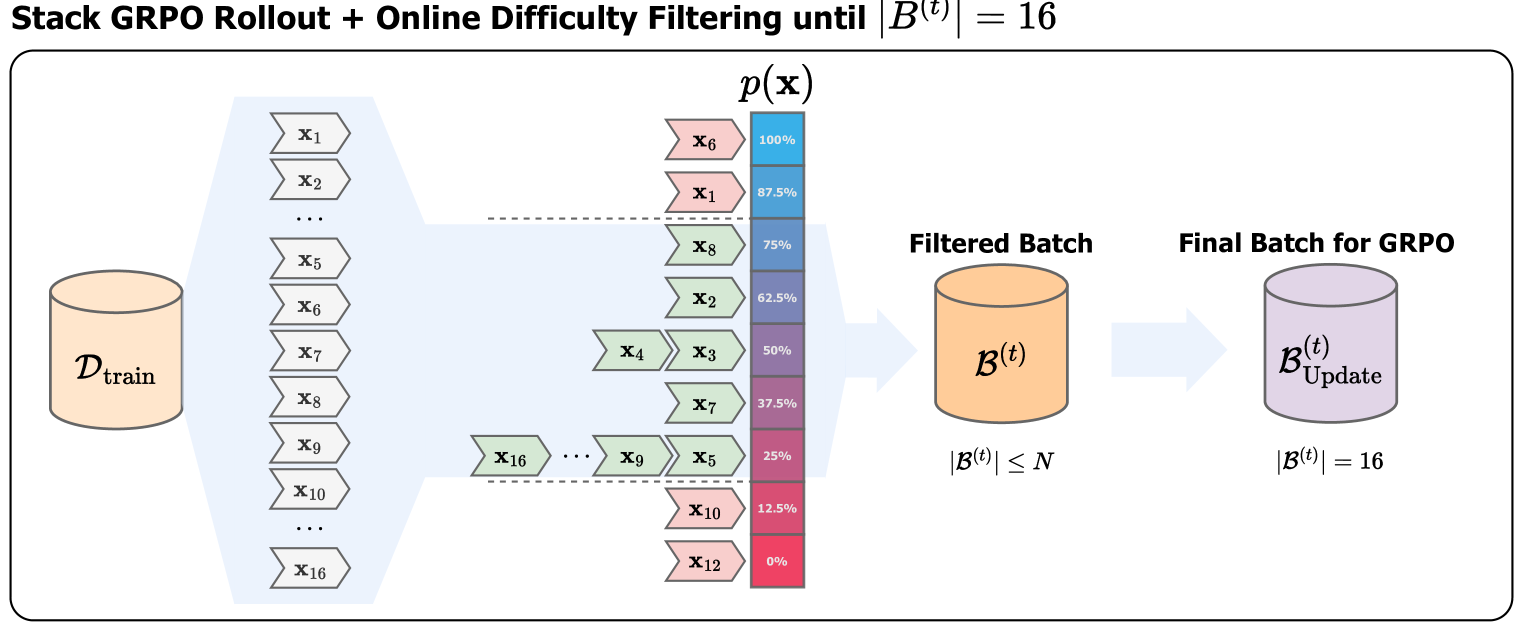
技术框架:该方法的核心在于在线难度评估和过滤。在每个训练迭代中,模型首先在一批题目上进行推理,然后根据模型的推理精度对题目进行排序。接着,根据预定义的平衡策略,选择精度处于中间范围的题目子集用于训练。这个过程是动态的,难度过滤策略会随着模型的学习进度而自适应地调整。
关键创新:该方法最重要的创新点在于其理论基础和平衡过滤的思想。论文通过数学推导,将训练目标与采样精度的方差联系起来,并证明了平衡过滤能够最大化KL散度的下界。这种理论支撑使得该方法具有更强的鲁棒性和泛化能力,避免了传统方法中依赖经验或启发式规则的问题。
关键设计:关键设计包括:1) 精度评估方法:使用模型的预测结果与正确答案进行比较,计算每个题目的精度。2) 平衡策略:定义一个精度范围,例如选择精度在30%-70%之间的题目。3) 难度调整策略:根据模型的整体学习进度,动态调整精度范围,以保持训练题目的难度始终处于平衡状态。4) 损失函数:使用标准的强化学习损失函数,例如策略梯度损失,但只在选定的题目子集上计算。
🖼️ 关键图片
📊 实验亮点
实验结果表明,平衡在线过滤方法在五个数学推理基准测试中显著提升了性能。在AIME测试中,该方法获得了额外的10%的提升,平均提升了4%。此外,该方法在样本效率和训练时间效率方面也表现出色,在60%的训练时间和训练集大小内超过了普通GRPO的最大奖励。
🎯 应用场景
该研究成果可广泛应用于需要复杂推理能力的AI系统中,例如数学问题求解、代码生成、知识图谱推理等。通过提升LLM的推理能力,可以提高这些系统在实际应用中的性能和可靠性,例如在教育领域可以辅助学生学习数学,在软件开发领域可以提高代码生成的质量。
📄 摘要(原文)
Reasoning-Oriented Reinforcement Learning (RORL) enhances the reasoning ability of Large Language Models (LLMs). However, due to the sparsity of rewards in RORL, effective training is highly dependent on the selection of problems of appropriate difficulty. Although curriculum learning attempts to address this by adjusting difficulty, it often relies on static schedules, and even recent online filtering methods lack theoretical grounding and a systematic understanding of their effectiveness. In this work, we theoretically and empirically show that curating the batch with the problems that the training model achieves intermediate accuracy on the fly can maximize the effectiveness of RORL training, namely balanced online difficulty filtering. We first derive that the lower bound of the KL divergence between the initial and the optimal policy can be expressed with the variance of the sampled accuracy. Building on those insights, we show that balanced filtering can maximize the lower bound, leading to better performance. Experimental results across five challenging math reasoning benchmarks show that balanced online filtering yields an additional 10% in AIME and 4% improvements in average over plain GRPO. Moreover, further analysis shows the gains in sample efficiency and training time efficiency, exceeding the maximum reward of plain GRPO within 60% training time and the volume of the training set.