Evaluating Compact LLMs for Zero-Shot Iberian Language Tasks on End-User Devices
作者: Luís Couto Seller, Íñigo Sanz Torres, Adrián Vogel-Fernández, Carlos González Carballo, Pedro Miguel Sánchez Sánchez, Adrián Carruana Martín, Enrique de Miguel Ambite
分类: cs.CL, cs.LG
发布日期: 2025-04-04 (更新: 2025-05-28)
备注: Accepted at SEPLN 2025 conference
💡 一句话要点
评估紧凑型LLM在终端设备上零样本伊比利亚语任务的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 紧凑型模型 零样本学习 伊比利亚语 低资源语言
📋 核心要点
- 大型语言模型计算需求高,难以在消费级设备上部署,限制了其应用范围。
- 针对伊比利亚语等低资源语言,评估紧凑型LLM在各种NLP任务上的零样本性能。
- 实验结果揭示了模型在不同语言和任务上的性能差异,突出了进一步研究的必要性。
📝 摘要(中文)
大型语言模型(LLM)在自然语言处理领域取得了显著进展,在语言生成、翻译和推理等任务中表现出色。然而,它们巨大的计算需求限制了其在高端系统上的部署,从而限制了在消费级设备上的可访问性。对于伊比利亚半岛使用的资源匮乏型语言来说,这一挑战尤为突出,因为相对有限的语言资源和基准阻碍了有效的评估。本文对几种针对伊比利亚语言定制的基本NLP任务,全面评估了最先进的紧凑型LLM。结果表明,虽然某些模型在特定任务中始终表现出色,但仍然存在显著的性能差距,尤其是对于巴斯克语等语言。这些发现强调需要进一步研究,以平衡模型的紧凑性与强大的多语言性能。
🔬 方法详解
问题定义:论文旨在评估紧凑型大型语言模型(LLM)在伊比利亚语(包括巴斯克语等低资源语言)上的零样本学习能力。现有大型LLM计算资源需求高,难以在终端设备上部署,而针对低资源语言的评估基准和资源又相对匮乏,导致无法有效评估和优化这些模型在实际应用中的性能。
核心思路:论文的核心思路是通过在多个针对伊比利亚语定制的NLP任务上,对一系列紧凑型LLM进行零样本评估,从而分析这些模型在不同语言和任务上的性能表现。通过这种方式,可以识别出模型在哪些方面表现良好,哪些方面存在不足,为未来的模型优化和资源建设提供指导。
技术框架:论文的整体框架包括以下几个主要步骤:1) 选择一系列紧凑型LLM作为评估对象;2) 选取多个针对伊比利亚语定制的NLP任务,例如文本分类、命名实体识别、问答等;3) 在选定的任务上,使用零样本学习的方式评估各个模型的性能;4) 分析实验结果,比较不同模型在不同语言和任务上的表现,找出优势和不足。
关键创新:论文的关键创新在于针对伊比利亚语等低资源语言,系统性地评估了紧凑型LLM的零样本学习能力。以往的研究大多集中在通用的大型LLM上,或者只关注高资源语言。本文的研究填补了这一空白,为低资源语言的NLP研究提供了有价值的参考。
关键设计:论文的关键设计包括:1) 任务选择:选择了多个具有代表性的NLP任务,覆盖了不同的语言处理能力;2) 模型选择:选择了多个具有代表性的紧凑型LLM,覆盖了不同的模型架构和训练方法;3) 评估指标:使用了常用的NLP评估指标,例如准确率、F1值等,以便于比较不同模型的性能。
🖼️ 关键图片
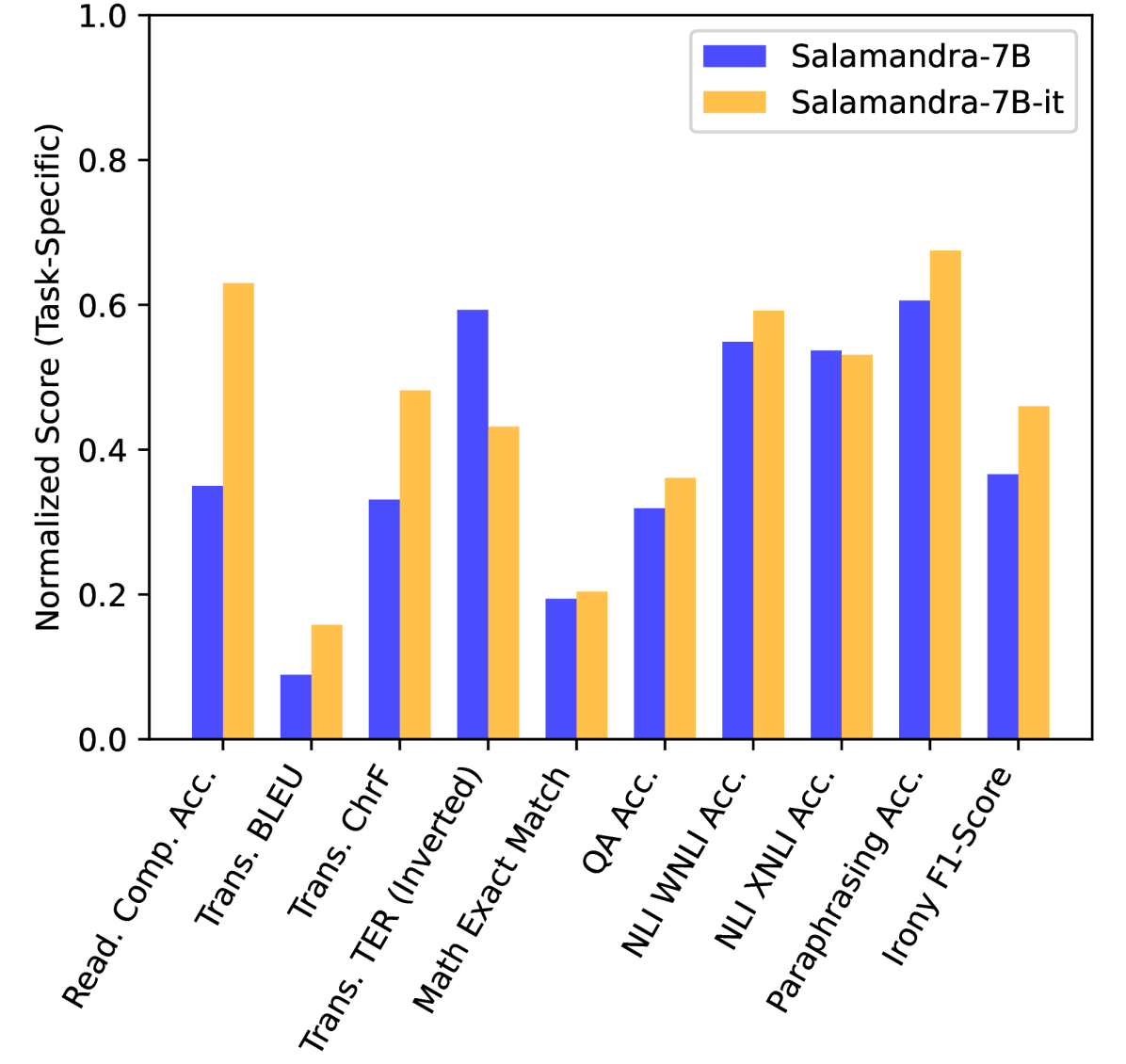
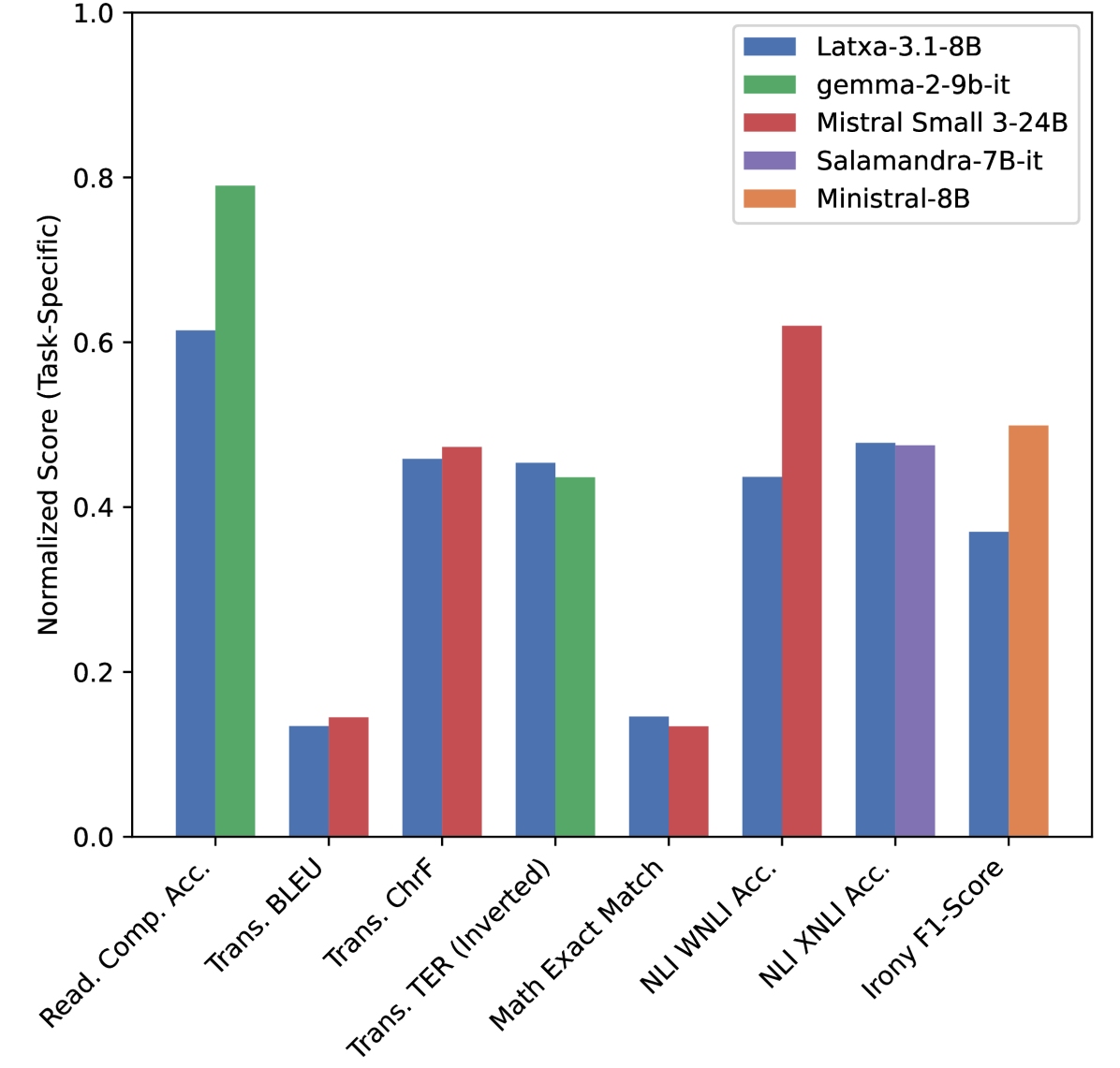
📊 实验亮点
实验结果表明,不同的紧凑型LLM在不同的伊比利亚语任务上表现出显著的性能差异。例如,某些模型在加泰罗尼亚语和西班牙语等高资源语言上表现良好,但在巴斯克语等低资源语言上性能明显下降。这些结果突出了模型在多语言环境下的泛化能力问题,以及针对低资源语言进行模型优化的必要性。
🎯 应用场景
该研究成果可应用于开发面向伊比利亚语使用者的终端设备应用,例如智能助手、机器翻译、文本摘要等。通过选择合适的紧凑型LLM,可以在资源受限的设备上实现高效的语言处理功能,促进低资源语言的信息化发展,并为相关领域的研究提供参考。
📄 摘要(原文)
Large Language Models have significantly advanced natural language processing, achieving remarkable performance in tasks such as language generation, translation, and reasoning. However, their substantial computational requirements restrict deployment to high-end systems, limiting accessibility on consumer-grade devices. This challenge is especially pronounced for under-resourced languages like those spoken in the Iberian Peninsula, where relatively limited linguistic resources and benchmarks hinder effective evaluation. This work presents a comprehensive evaluation of compact state-of-the-art LLMs across several essential NLP tasks tailored for Iberian languages. The results reveal that while some models consistently excel in certain tasks, significant performance gaps remain, particularly for languages such as Basque. These findings highlight the need for further research on balancing model compactness with robust multilingual performance