Enhancing Personalized Multi-Turn Dialogue with Curiosity Reward
作者: Yanming Wan, Jiaxing Wu, Marwa Abdulhai, Lior Shani, Natasha Jaques
分类: cs.CL, cs.AI
发布日期: 2025-04-04 (更新: 2025-10-02)
💡 一句话要点
提出基于好奇心奖励的个性化多轮对话方法,提升LLM用户建模能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化对话 多轮对话 强化学习 好奇心奖励 用户建模 大型语言模型 RLHF
📋 核心要点
- 现有对话Agent在个性化方面不足,尤其是在用户历史数据有限的情况下,难以进行有效用户建模。
- 论文提出基于好奇心奖励的强化学习方法,鼓励Agent通过对话主动推断用户特征,提升用户建模准确性。
- 实验表明,该方法在对话推荐和教育场景中均能显著提升个性化性能,并具有更好的泛化能力。
📝 摘要(中文)
大型语言模型(LLM)作为对话Agent,需要进行个性化交互以适应用户在教育和医疗等领域中的偏好、个性和属性。现有方法,如基于人类反馈的强化学习(RLHF),通常侧重于有用性和安全性,但在培养真正具有同理心、适应性和个性化的对话方面存在不足。现有的个性化方法通常依赖于广泛的用户历史,限制了它们对新用户或上下文有限用户的有效性。为了解决这些限制,我们提出利用用户模型将基于好奇心的内在奖励纳入多轮RLHF中。这种新颖的奖励机制鼓励LLM Agent通过优化对话来提高其用户模型的准确性,从而主动推断用户特征。因此,Agent通过更多地了解用户来提供更个性化的交互。我们在两个不同的领域证明了我们方法的有效性:显著提高了对话推荐任务中的个性化性能,并在教育环境中针对不同的学习风格进行个性化对话。我们展示了与传统多轮RLHF相比,改进的泛化能力,同时保持了对话质量。我们的方法为创建更个性化、适应性和引人入胜的对话Agent提供了一个有希望的解决方案。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)方法在个性化对话方面存在不足,尤其是在用户历史数据有限的情况下,难以准确捕捉用户偏好和个性特征。传统方法依赖大量用户数据,对新用户或上下文信息不足的用户效果不佳。
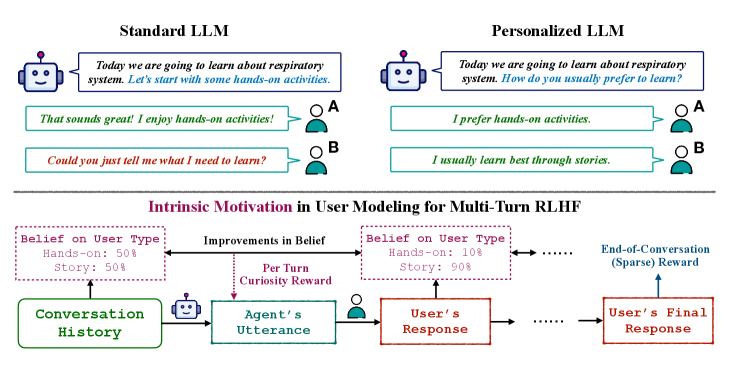
核心思路:论文的核心思路是引入基于好奇心的内在奖励机制,鼓励LLM Agent主动探索用户特征,优化用户建模过程。通过奖励Agent在对话中能够提升用户模型准确性的行为,促使其更有效地学习用户偏好。
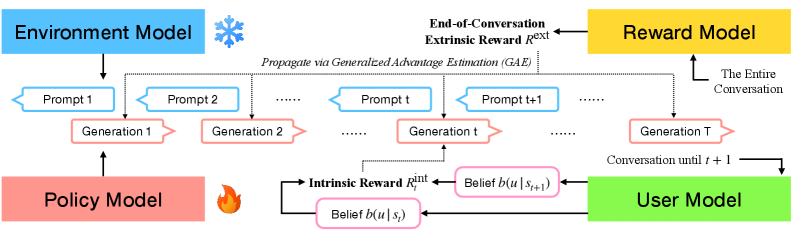
技术框架:整体框架是在传统RLHF的基础上,增加了一个用户模型和一个好奇心奖励模块。Agent与用户进行多轮对话,用户模型根据对话历史更新用户画像,好奇心奖励模块根据用户模型的变化情况给予Agent奖励。Agent的目标是最大化外部奖励(如对话成功率)和内在奖励(好奇心奖励)的总和。
关键创新:关键创新在于好奇心奖励的设计。该奖励不是直接基于对话内容,而是基于用户模型在对话前后的变化。如果Agent的对话能够显著提升用户模型的准确性,则会获得更高的奖励。这种设计鼓励Agent主动探索,而非仅仅迎合已知的用户偏好。
关键设计:用户模型可以使用各种技术实现,例如贝叶斯网络或神经网络。好奇心奖励可以定义为用户模型更新前后概率分布的差异,例如KL散度。具体参数设置需要根据具体应用场景进行调整。损失函数是外部奖励和好奇心奖励的加权和,权重系数需要仔细调整以平衡对话质量和个性化程度。
🖼️ 关键图片
📊 实验亮点
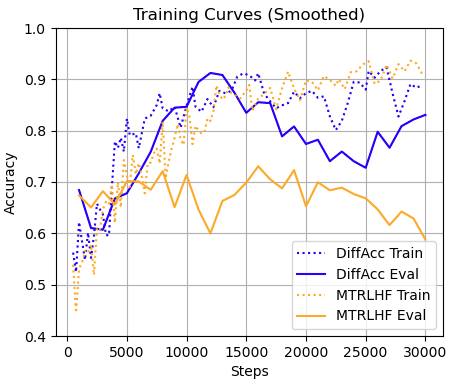
实验结果表明,该方法在对话推荐任务中显著提升了个性化性能,并在教育场景中成功实现了针对不同学习风格的个性化对话。与传统多轮RLHF相比,该方法具有更好的泛化能力,能够在用户数据有限的情况下提供更有效的个性化服务。具体性能数据未知。
🎯 应用场景
该研究成果可广泛应用于各种需要个性化对话的场景,例如智能客服、个性化推荐系统、教育辅导机器人和医疗健康咨询等。通过提升用户建模能力,可以提供更贴合用户需求的对话体验,提高用户满意度和使用效率,并有可能在教育和医疗等领域产生积极影响。
📄 摘要(原文)
Effective conversational agents like large language models (LLMs) must personalize their interactions to adapt to user preferences, personalities, and attributes across diverse domains like education and healthcare. Current methods like Reinforcement Learning from Human Feedback (RLHF), often prioritize helpfulness and safety but fall short in fostering truly empathetic, adaptive, and personalized dialogues. Existing personalization approaches typically rely on extensive user history, limiting their effectiveness for new or context-limited users. To address these limitations, we propose leveraging a user model to incorporate a curiosity-based intrinsic reward into multi-turn RLHF. This novel reward mechanism encourages the LLM agent to actively infer user traits by optimizing conversations to improve its user model's accuracy. Consequently, the agent delivers more personalized interactions by learning more about the user. We demonstrate our method's effectiveness in two distinct domains: significantly improving personalization performance in a conversational recommendation task, and personalizing conversations for different learning styles in an educational setting. We show improved generalization capabilities compared to traditional multi-turn RLHF, all while maintaining conversation quality. Our method offers a promising solution for creating more personalized, adaptive, and engaging conversational agents.