CoLa: Learning to Interactively Collaborate with Large Language Models
作者: Abhishek Sharma, Dan Goldwasser
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-04-03 (更新: 2025-09-20)
💡 一句话要点
提出CoLa,通过自指导学习训练AI引导者,提升LLM在复杂语言任务中的协作能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机协作 大型语言模型 自指导学习 行为克隆 自动化引导 问答系统 复杂推理
📋 核心要点
- 现有方法缺乏有效利用人类指导经验来提升LLM在复杂任务中的协作能力。
- CoLa通过自指导学习训练自动化引导者,模拟人类指导,提升LLM解决复杂语言问题的能力。
- 实验表明,CoLa在多个任务上优于现有方法,甚至小型引导者也能超越GPT-4。
📝 摘要(中文)
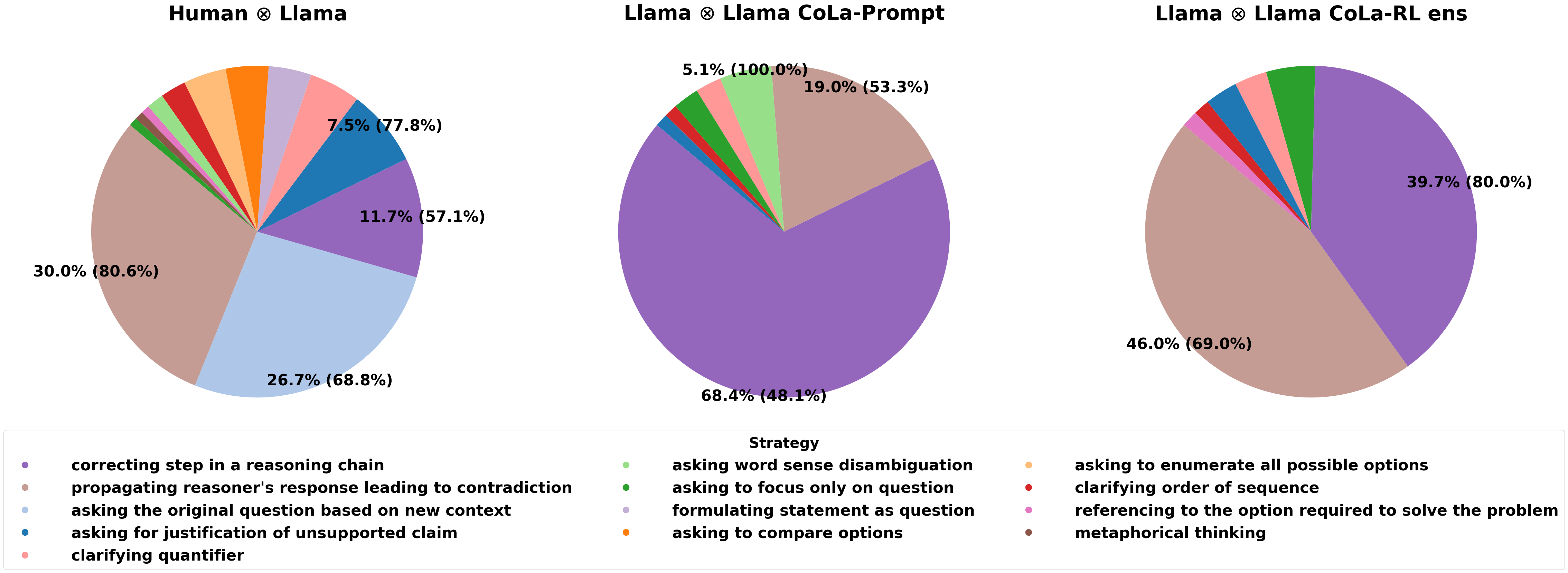
大型语言模型(LLMs)在处理各种语言任务方面的卓越能力,为人类与AI协作解决问题开辟了新的机会。LLMs可以通过大规模应用其直觉和推理策略来增强人类的能力。本文探讨了是否可以通过从人类演示中泛化,来模拟人类引导者,从而指导AI系统解决复杂的语言问题。我们提出了CoLa,一种新颖的自指导学习范式,用于训练自动化的“引导者”,并在两个问答数据集、一个解谜任务和一个约束文本生成任务上对其进行评估。实验结果表明,CoLa在所有领域都始终优于具有竞争力的baseline方法。此外,一个小型训练的引导者在作为引导者时,其性能甚至超过了像GPT-4这样的强大模型。我们通过对问答数据集进行人工研究,比较了人类和自动化引导者所采用的策略。结果表明,自动化引导者通过调整其策略以适应推理者的能力而优于人类,并进行了定性分析,突出了引导策略的明显差异。
🔬 方法详解
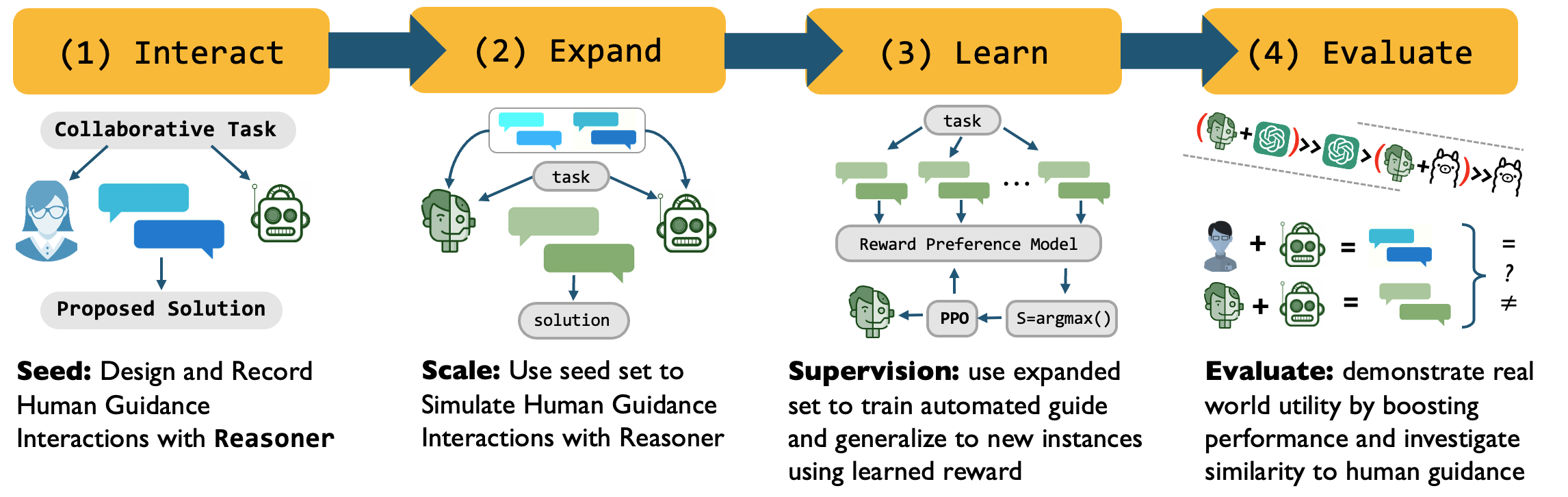
问题定义:论文旨在解决如何有效地训练AI引导者,使其能够像人类一样指导大型语言模型(LLMs)解决复杂的语言任务。现有方法要么依赖人工设计的规则,要么缺乏从人类指导经验中学习的能力,导致协作效率低下,无法充分发挥LLMs的潜力。
核心思路:CoLa的核心思路是利用自指导学习范式,通过模仿人类引导者的行为来训练AI引导者。具体来说,CoLa通过观察人类如何指导LLM解决问题,学习人类的指导策略,并将其泛化到新的任务和LLM上。这种方法避免了人工设计规则的复杂性,并能够充分利用人类的知识和经验。
技术框架:CoLa的整体框架包含以下几个主要阶段:1) 数据收集:收集人类指导LLM解决问题的演示数据。2) 引导者训练:使用收集到的数据训练AI引导者,使其能够预测在给定问题和LLM状态下,人类引导者会采取的行动。3) 协作推理:在推理阶段,AI引导者与LLM进行交互,根据LLM的输出和当前状态,动态地调整指导策略,最终解决问题。
关键创新:CoLa最重要的技术创新点在于其自指导学习范式。与传统的监督学习方法不同,CoLa不需要人工标注的指导策略,而是通过观察人类的演示数据,自动学习指导策略。这种方法大大降低了训练成本,并能够学习到更加灵活和有效的指导策略。此外,CoLa还能够根据LLM的能力和任务的特点,动态地调整指导策略,从而实现更好的协作效果。
关键设计:CoLa的关键设计包括:1) 使用Transformer模型作为AI引导者的基础架构。2) 使用行为克隆(Behavior Cloning)作为训练方法,即最小化AI引导者预测的行动与人类引导者实际行动之间的差异。3) 设计合适的奖励函数,鼓励AI引导者采取有效的指导策略,例如,鼓励其提供有用的信息,避免重复提问等。4) 通过实验选择合适的超参数,例如学习率、batch size等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CoLa在问答、解谜和约束文本生成等任务上,均显著优于现有的baseline方法。例如,在某些任务上,CoLa的性能提升超过10%。更令人惊讶的是,一个小型训练的CoLa引导者,其性能甚至超过了强大的GPT-4模型,证明了CoLa的有效性和潜力。
🎯 应用场景
CoLa具有广泛的应用前景,例如智能客服、教育辅导、代码生成等。它可以用于构建更加智能和高效的人机协作系统,提升LLM在各种实际应用中的性能。未来,CoLa可以进一步扩展到其他领域,例如机器人控制、游戏AI等,实现更加复杂和智能的人机交互。
📄 摘要(原文)
LLMs' remarkable ability to tackle a wide range of language tasks opened new opportunities for collaborative human-AI problem solving. LLMs can amplify human capabilities by applying their intuitions and reasoning strategies at scale. We explore whether human guides can be simulated, by generalizing from human demonstrations of guiding an AI system to solve complex language problems. We introduce CoLa, a novel self-guided learning paradigm for training automated $\textit{guides}$ and evaluate it on two QA datasets, a puzzle-solving task, and a constrained text generation task. Our empirical results show that CoLa consistently outperforms competitive approaches across all domains. Moreover, a small-sized trained guide outperforms a strong model like GPT-4 when acting as a guide. We compare the strategies employed by humans and automated guides by conducting a human study on a QA dataset. We show that automated guides outperform humans by adapting their strategies to reasoners' capabilities and conduct qualitative analyses highlighting distinct differences in guiding strategies.