How Post-Training Reshapes LLMs: A Mechanistic View on Knowledge, Truthfulness, Refusal, and Confidence
作者: Hongzhe Du, Weikai Li, Min Cai, Karim Saraipour, Zimin Zhang, Himabindu Lakkaraju, Yizhou Sun, Shichang Zhang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-04-03 (更新: 2025-11-08)
备注: COLM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
从机制角度剖析后训练对LLM的影响:知识、真实性、拒绝与置信度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 后训练 机制分析 知识表示 真实性 拒绝 置信度
📋 核心要点
- 现有研究缺乏对后训练如何在LLM内部进行重塑的深入理解,阻碍了对后训练效果的全面认知。
- 该论文从机制角度比较基础LLM和后训练LLM,关注知识、真实性、拒绝和置信度四个关键方面。
- 研究揭示了后训练对知识表示、真实性和拒绝机制的影响,并探讨了置信度变化的内在原因。
📝 摘要(中文)
后训练对于大型语言模型(LLM)的成功至关重要,它将预训练的基础模型转化为更有用和对齐的后训练模型。虽然大量工作研究了后训练算法并通过其输出来评估后训练模型,但后训练如何在LLM内部重塑模型仍然研究不足。在本文中,我们从四个角度对基础LLM和后训练LLM进行机制比较,以更好地理解后训练效果。我们在模型家族和数据集上的发现表明:(1)后训练不改变事实知识存储位置,它调整来自基础模型的知识表示,同时开发新的知识表示;(2)真实性和拒绝都可以用隐藏表示空间中的向量表示。基础模型和后训练模型之间的真实性方向高度相似,并且可以有效地转移以进行干预;(3)基础模型和后训练模型之间的拒绝方向不同,并且显示出有限的前向可转移性;(4)基础模型和后训练模型之间置信度的差异不能归因于熵神经元。我们的研究提供了对后训练期间保留和改变的基本机制的见解,有助于模型引导等下游任务,并可能有利于未来在可解释性和LLM后训练方面的研究。我们的代码可在https://github.com/HZD01/post-training-mechanistic-analysis公开获得。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)后训练过程中,模型内部机制如何发生变化的问题。现有研究主要集中在后训练算法和模型输出评估,缺乏对模型内部知识表示、真实性、拒绝和置信度等关键属性的机制性理解。这种理解的缺失限制了我们对后训练效果的全面认知,以及对模型行为的有效控制和干预。
核心思路:论文的核心思路是通过比较基础LLM和后训练LLM的内部表示,揭示后训练对模型内部机制的影响。具体而言,论文将真实性和拒绝等概念表示为隐藏层空间中的向量,并通过分析这些向量的变化,理解后训练如何改变模型的行为。此外,论文还关注知识存储位置和置信度变化,力求从多个维度剖析后训练的机制性影响。
技术框架:论文的技术框架主要包括以下几个阶段:1) 选择具有代表性的基础LLM和后训练LLM;2) 构建包含事实知识、真实性判断、拒绝回答等多种类型的数据集;3) 提取模型在不同层级的隐藏表示;4) 使用向量分析、相似度计算等方法,比较基础模型和后训练模型在知识表示、真实性方向、拒绝方向和置信度等方面的差异;5) 通过干预实验,验证真实性和拒绝方向的可转移性。
关键创新:论文的关键创新在于:1) 从机制角度深入研究了后训练对LLM的影响,弥补了现有研究的不足;2) 将真实性和拒绝等概念表示为隐藏层空间中的向量,为理解和控制模型行为提供了新的视角;3) 揭示了后训练对知识表示、真实性和拒绝机制的不同影响,为未来的模型改进提供了指导。
关键设计:论文的关键设计包括:1) 选取多种模型家族和数据集,以保证研究结果的泛化性;2) 使用余弦相似度等指标,量化不同模型之间的向量相似度;3) 设计干预实验,通过修改模型的隐藏表示,验证真实性和拒绝方向的可转移性;4) 采用熵神经元分析方法,探究置信度变化的内在原因。
🖼️ 关键图片
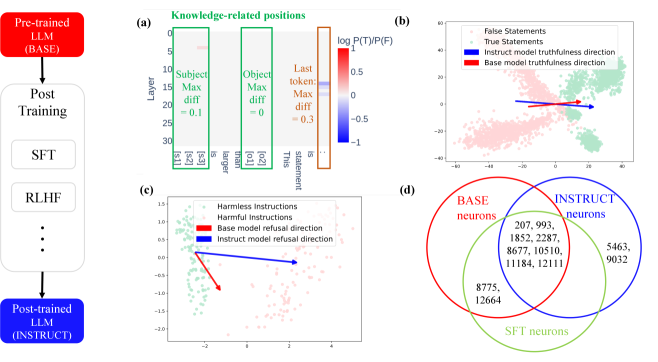
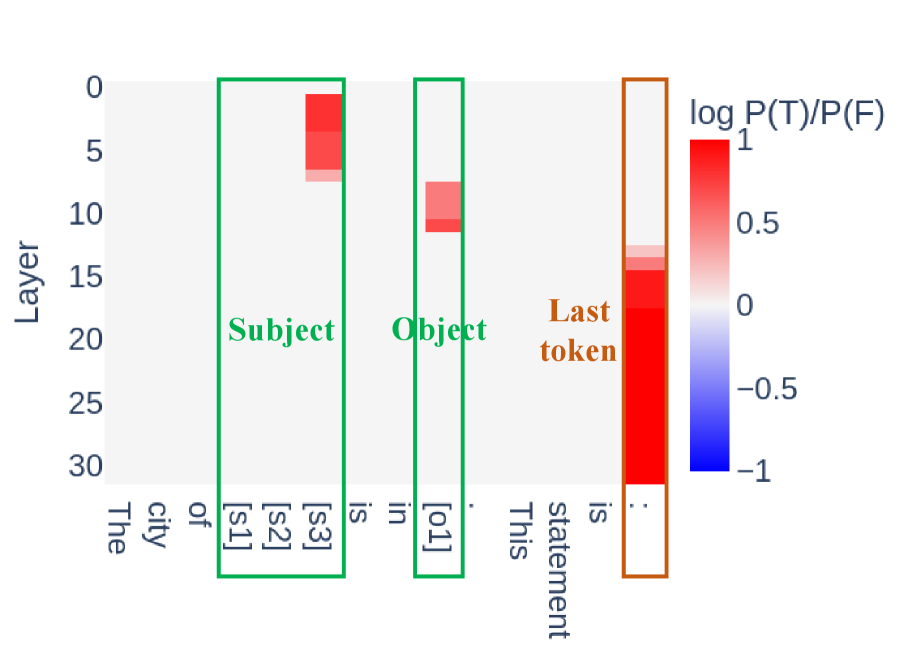
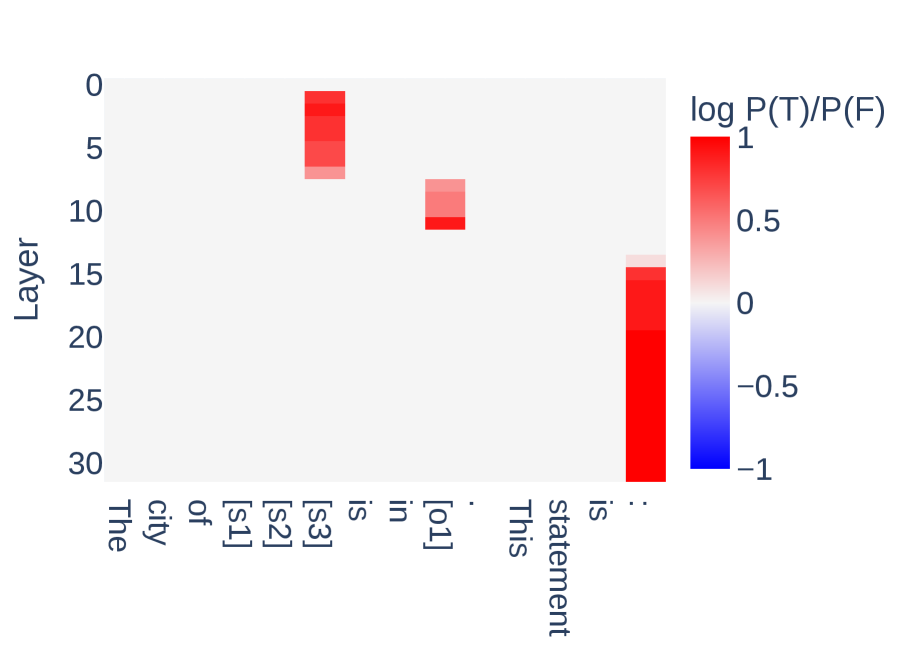
📊 实验亮点
研究发现,后训练不改变事实知识存储位置,但会调整知识表示并开发新的知识表示。真实性方向在基础模型和后训练模型之间高度相似且可转移,而拒绝方向则不同且可转移性有限。置信度的差异不能归因于熵神经元。这些发现为理解后训练的机制性影响提供了重要依据。
🎯 应用场景
该研究成果可应用于模型引导、可解释性研究和LLM后训练等领域。通过理解后训练对模型内部机制的影响,可以更有效地控制模型行为,提升模型性能,并为开发更安全、可靠的LLM提供理论基础。此外,该研究也有助于提升模型的可解释性,从而更好地理解模型的决策过程。
📄 摘要(原文)
Post-training is essential for the success of large language models (LLMs), transforming pre-trained base models into more useful and aligned post-trained models. While plenty of works have studied post-training algorithms and evaluated post-training models by their outputs, it remains understudied how post-training reshapes LLMs internally. In this paper, we compare base and post-trained LLMs mechanistically from four perspectives to better understand post-training effects. Our findings across model families and datasets reveal that: (1) Post-training does not change the factual knowledge storage locations, and it adapts knowledge representations from the base model while developing new knowledge representations; (2) Both truthfulness and refusal can be represented by vectors in the hidden representation space. The truthfulness direction is highly similar between the base and post-trained model, and it is effectively transferable for interventions; (3) The refusal direction is different between the base and post-trained models, and it shows limited forward transferability; (4) Differences in confidence between the base and post-trained models cannot be attributed to entropy neurons. Our study provides insights into the fundamental mechanisms preserved and altered during post-training, facilitates downstream tasks like model steering, and could potentially benefit future research in interpretability and LLM post-training. Our code is publicly available at https://github.com/HZD01/post-training-mechanistic-analysis.