Beyond Accuracy: The Role of Calibration in Self-Improving Large Language Models
作者: Liangjie Huang, Dawei Li, Huan Liu, Lu Cheng
分类: cs.CL, cs.AI
发布日期: 2025-04-03
💡 一句话要点
研究自提升大语言模型校准问题,提出迭代校准方法降低过自信。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自提升学习 置信度校准 预期校准误差 模型可靠性
📋 核心要点
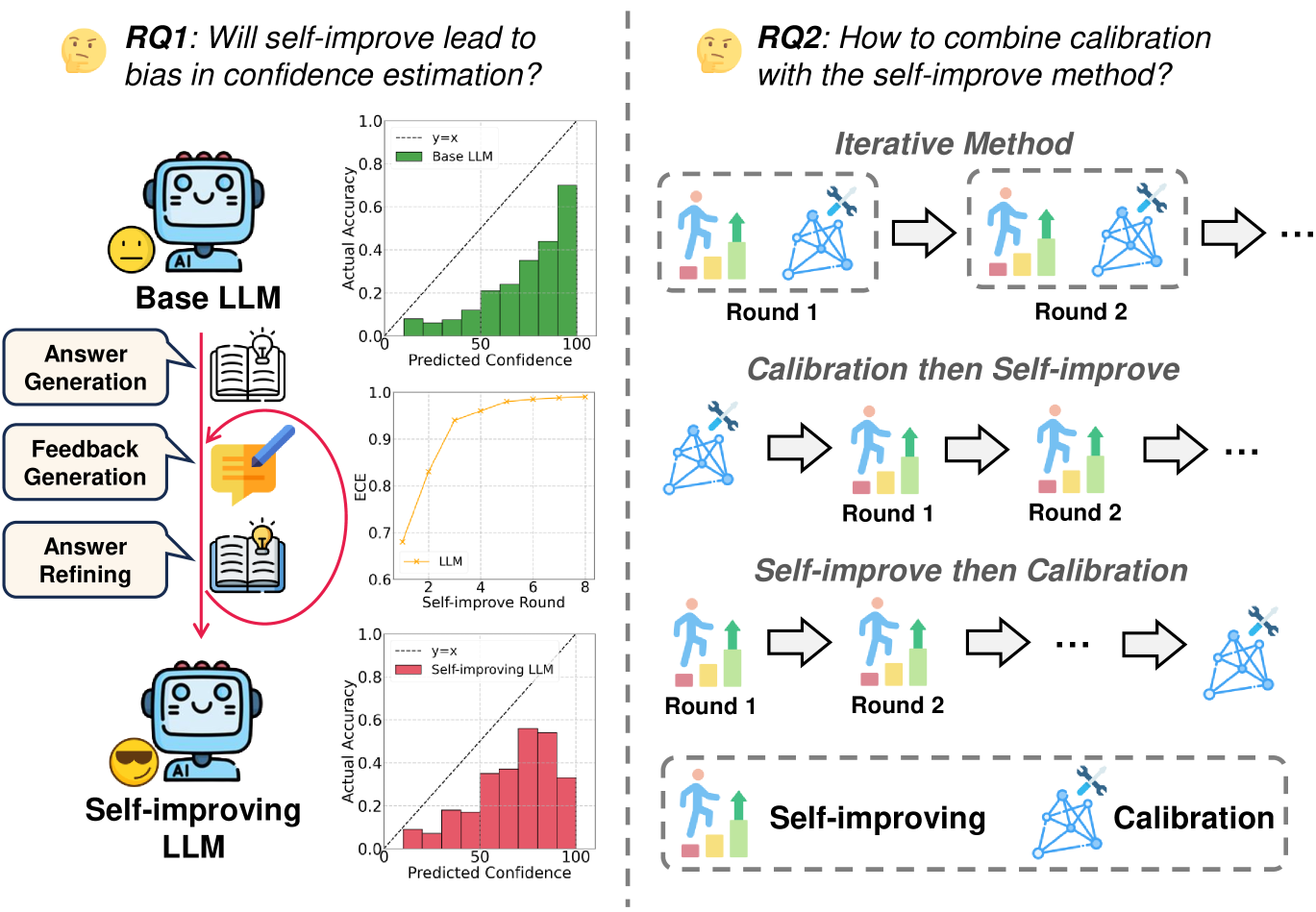
- 自提升LLM存在自我偏见,可能导致置信度估计出现偏差,现有研究缺乏对置信度校准的关注。
- 研究核心在于探索不同校准策略与自提升的结合,旨在降低自提升过程中的过度自信问题。
- 实验结果表明,迭代校准策略能有效降低预期校准误差(ECE),提升模型校准性能。
📝 摘要(中文)
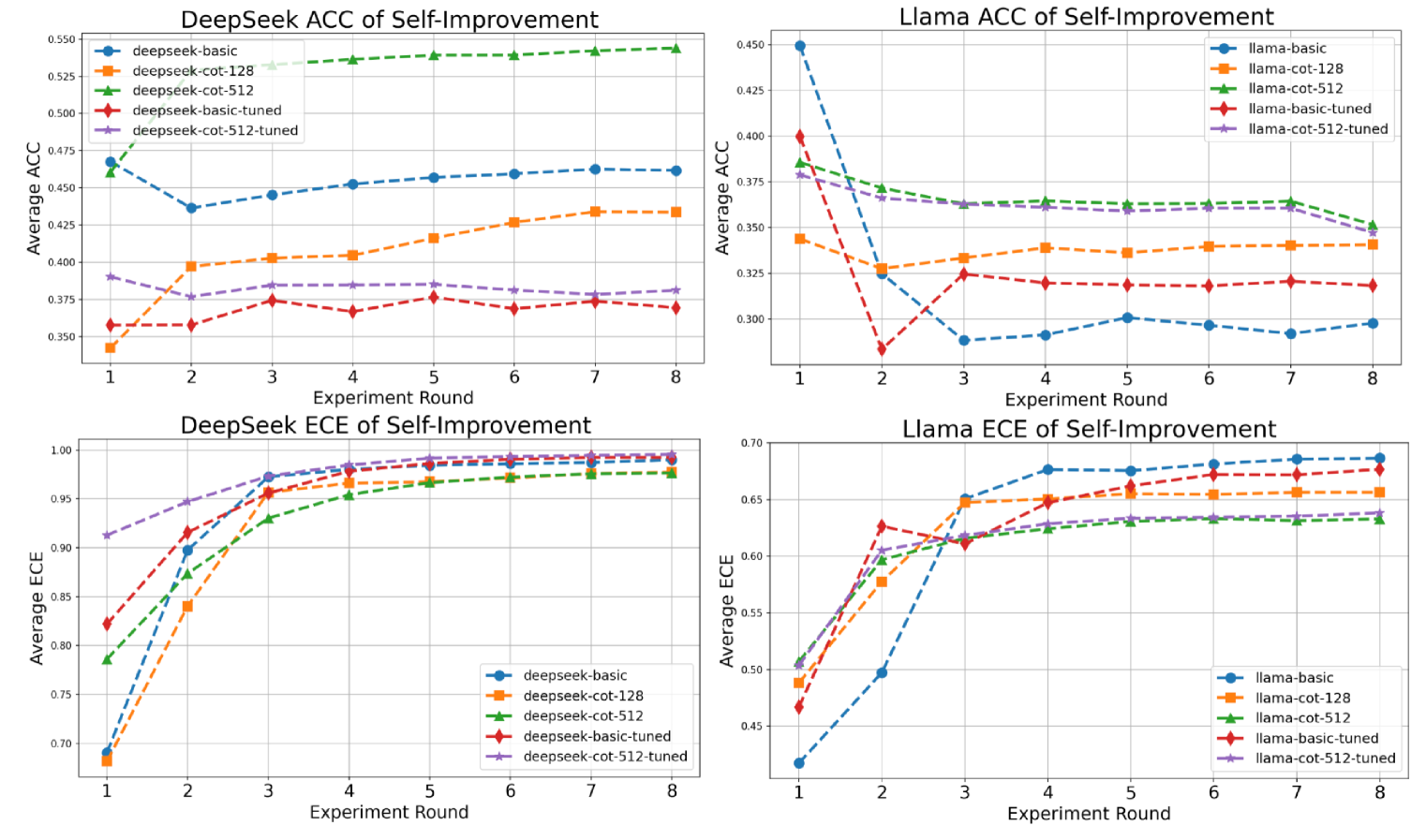
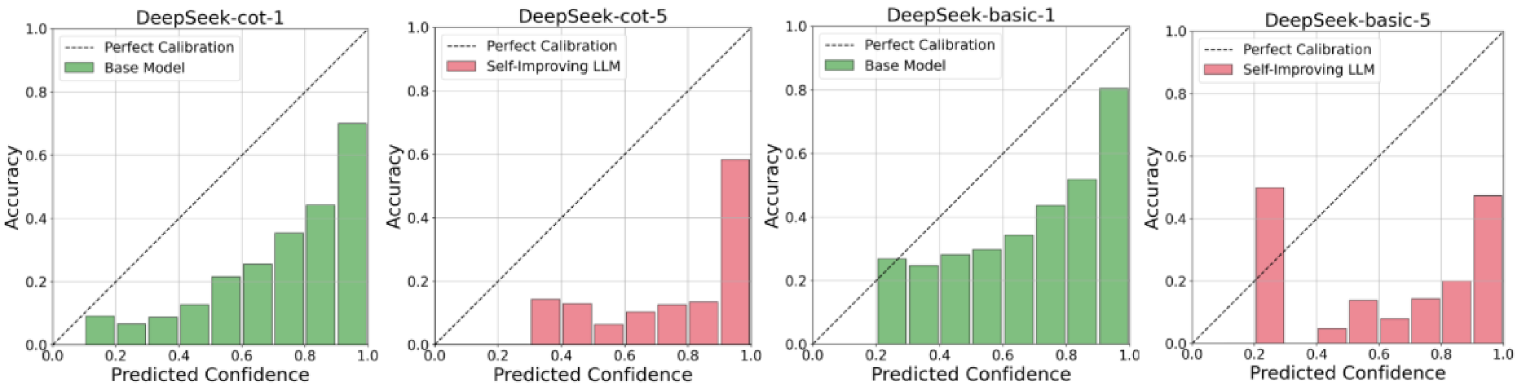
大型语言模型(LLMs)展现了卓越的自提升能力,模型可以通过自我生成的反馈迭代地修改其输出。虽然这种反思机制在提高任务性能方面显示出前景,但最近的研究表明,它也可能引入不良偏差——最显著的是自我偏差,即LLMs倾向于偏爱自己先前的输出。本文通过研究对置信度估计的影响来扩展这一研究方向。我们评估了三种具有代表性的自提升范式——基本提示、思维链(CoT)提示和基于调优的方法,发现迭代自提升可能导致系统性的过度自信,这体现在不断增加的预期校准误差(ECE)以及高置信度下的较低准确率。然后,我们进一步探索了将置信度校准技术与自提升相结合。具体来说,我们比较了三种策略:(1)在多轮自提升后应用校准,(2)在自提升前进行校准,以及(3)在每个自提升步骤中迭代地应用校准。我们的结果表明,迭代校准在降低ECE方面最有效,从而产生改进的校准。我们的工作率先从校准的角度研究自提升LLMs,为平衡模型性能和可靠性提供了宝贵的见解。
🔬 方法详解
问题定义:论文旨在解决自提升大型语言模型(LLMs)在迭代改进过程中产生的置信度偏差问题,特别是过度自信的现象。现有方法虽然关注了自提升带来的性能提升,但忽略了模型置信度估计的可靠性,导致模型在高置信度下反而准确率下降。
核心思路:论文的核心思路是将置信度校准技术融入到自提升的迭代过程中,通过校准模型的置信度输出,使其与实际准确率更加一致。通过比较不同的校准策略,找到最有效的降低过度自信、提升模型校准性能的方法。
技术框架:论文评估了三种自提升范式(基本提示、CoT提示、基于调优的方法)与三种校准策略的结合:(1)自提升后校准;(2)自提升前校准;(3)迭代校准。整体流程包括:首先,使用不同的自提升方法迭代改进模型;然后,在不同阶段应用校准技术;最后,评估校准后的模型在置信度估计方面的表现,使用预期校准误差(ECE)作为主要评估指标。
关键创新:论文最重要的创新点在于首次从置信度校准的角度研究自提升LLMs。以往研究主要关注自提升对任务性能的影响,而忽略了其对置信度估计的影响。论文提出的迭代校准策略,通过在每个自提升步骤中进行校准,能够更有效地降低过度自信,提升模型校准性能。
关键设计:论文的关键设计在于比较了三种不同的校准策略。迭代校准策略的具体实现细节未知,但推测可能涉及在每次自提升迭代后,使用校准数据集调整模型的置信度输出,使其与实际准确率更加匹配。具体的校准方法可能采用温度缩放、等渗回归等技术。
🖼️ 关键图片
📊 实验亮点
实验结果表明,迭代校准策略在降低预期校准误差(ECE)方面表现最佳,能够有效缓解自提升LLM的过度自信问题。具体性能提升数据未知,但论文强调迭代校准能够显著改善模型的校准性能,使其置信度估计更加可靠。
🎯 应用场景
该研究成果可应用于对模型可靠性要求较高的领域,如医疗诊断、金融风控等。通过提升自提升LLM的校准性能,可以提高模型决策的透明度和可信度,降低因过度自信导致的错误决策风险。未来,该研究可进一步探索更有效的校准方法,并将其应用于更广泛的自提升场景。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable self-improvement capabilities, whereby models iteratively revise their outputs through self-generated feedback. While this reflective mechanism has shown promise in enhancing task performance, recent studies suggest that it may also introduce undesirable biases-most notably, self-bias, or the tendency of LLMs to favor their own prior outputs. In this work, we extend this line of inquiry by investigating the impact on confidence estimation. We evaluate three representative self-improvement paradigms-basic prompting, Chain-of-Thought (CoT) prompting, and tuning-based methods and find that iterative self-improvement can lead to systematic overconfidence, as evidenced by a steadily increasing Expected Calibration Error (ECE) and lower accuracy with high confidence. We then further explore the integration of confidence calibration techniques with self-improvement. Specifically, we compare three strategies: (1) applying calibration after multiple rounds of self-improvement, (2) calibrating before self-improvement, and (3) applying calibration iteratively at each self-improvement step. Our results show that iterative calibration is most effective in reducing ECE, yielding improved calibration. Our work pioneers the study of self-improving LLMs from a calibration perspective, offering valuable insights into balancing model performance and reliability.