Inference-Time Scaling for Generalist Reward Modeling
作者: Zijun Liu, Peiyi Wang, Runxin Xu, Shirong Ma, Chong Ruan, Peng Li, Yang Liu, Yu Wu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-04-03 (更新: 2025-09-25)
备注: Preprint, under review. 44 pages. Models are available at https://huggingface.co/collections/BBQGOD/deepseek-grm-68b4681169dbb97fd30614b5 and https://www.modelscope.cn/collections/DeepSeek-GRM-ff6a2d8babdd4a
💡 一句话要点
提出SPCT方法,提升通用奖励模型推理时可扩展性,实现DeepSeek-GRM模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 强化学习 推理时扩展 自洽批判调优 生成奖励建模
📋 核心要点
- 现有奖励模型在处理通用查询时,缺乏有效的推理时可扩展性,限制了其在复杂任务中的应用。
- 提出自洽批判调优(SPCT)方法,通过在线强化学习自适应地生成原则和批判,提升奖励模型的质量和可扩展性。
- 实验表明,SPCT显著提升了GRM的性能,优于现有方法,并在推理时扩展方面表现出更好的效果。
📝 摘要(中文)
本文研究如何提升通用查询下奖励模型(RM)的推理时可扩展性,以及如何通过适当的学习方法来提高性能-计算扩展的有效性。针对RM方法,采用点式生成奖励建模(GRM),以实现不同输入类型的灵活性和推理时扩展的潜力。针对学习方法,提出自洽批判调优(SPCT),通过在线强化学习促进GRM中可扩展的奖励生成行为,自适应地生成原则并准确地进行批判,从而得到DeepSeek-GRM模型。此外,为了有效的推理时扩展,使用并行采样来扩展计算使用,并引入元RM来指导投票过程,以获得更好的扩展性能。实验表明,SPCT显著提高了GRM的质量和可扩展性,在各种RM基准测试中优于现有方法和模型,且没有严重的偏差,并且可以实现比训练时扩展更好的性能。DeepSeek-GRM在某些任务中仍然面临挑战,我们认为可以通过未来在通用奖励系统中的努力来解决。模型已在Hugging Face和ModelScope上发布。
🔬 方法详解
问题定义:论文旨在解决通用奖励模型在推理时计算资源扩展性不足的问题。现有奖励模型在面对复杂或开放式问题时,难以有效利用增加的计算资源来提升奖励预测的准确性,这限制了它们在需要高精度奖励信号的强化学习任务中的应用。
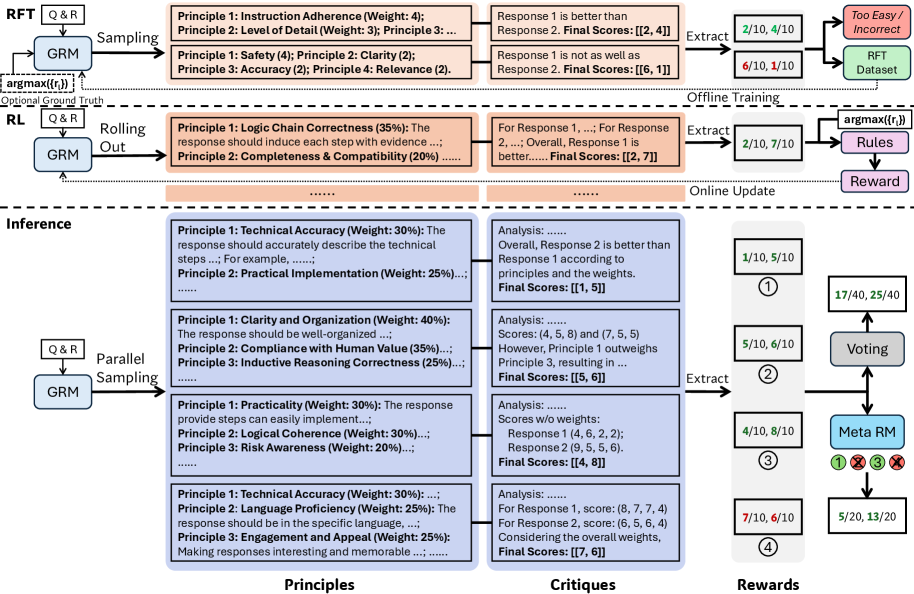
核心思路:论文的核心思路是通过一种新的训练方法——自洽批判调优(SPCT),来提升奖励模型在推理时利用更多计算资源的能力。SPCT鼓励奖励模型生成更符合人类价值观和原则的奖励,并且能够根据自身的预测结果进行批判性反思,从而提高奖励预测的准确性和一致性。
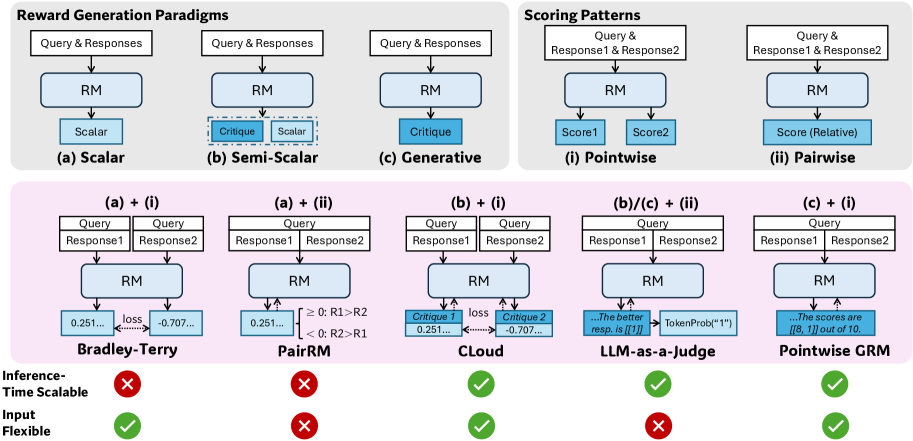
技术框架:整体框架包含以下几个主要模块:1) 点式生成奖励模型(GRM):作为基础奖励模型,负责生成奖励信号。2) 自洽批判调优(SPCT):通过在线强化学习,训练GRM生成高质量的奖励和批判。3) 并行采样:在推理时,通过并行采样生成多个奖励预测,增加计算资源的使用。4) 元奖励模型:用于指导投票过程,选择最佳的奖励预测结果。
关键创新:论文的关键创新在于SPCT方法,它通过在线强化学习的方式,让奖励模型学习生成原则和批判,从而提高奖励预测的质量和可扩展性。与传统的奖励模型训练方法相比,SPCT能够更好地利用推理时的计算资源,提升奖励模型的性能。
关键设计:SPCT的关键设计包括:1) 奖励模型生成原则和批判的机制;2) 在线强化学习的奖励函数设计,鼓励模型生成高质量的奖励和批判;3) 元奖励模型的设计,用于指导投票过程,选择最佳的奖励预测结果。具体参数设置和网络结构细节在论文中进行了详细描述,但此处未提供。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SPCT方法显著提高了GRM的质量和可扩展性,在各种RM基准测试中优于现有方法和模型。DeepSeek-GRM在多个任务上取得了领先的性能,并且在推理时扩展方面表现出更好的效果。与训练时扩展相比,推理时扩展能够更有效地利用计算资源,提升奖励模型的性能。
🎯 应用场景
该研究成果可应用于各种需要高质量奖励信号的强化学习任务中,例如对话系统、文本生成、代码生成等。通过提升奖励模型的推理时可扩展性,可以更好地利用计算资源,提高强化学习算法的性能,从而实现更智能、更高效的AI系统。该研究对于构建通用人工智能系统具有重要意义。
📄 摘要(原文)
Reinforcement learning (RL) has been widely adopted in post-training for large language models (LLMs) at scale. Recently, the incentivization of reasoning capabilities in LLMs from RL indicates that $\textit{proper learning methods could enable effective inference-time scalability}$. A key challenge of RL is to obtain accurate reward signals for LLMs in various domains beyond verifiable questions or artificial rules. In this work, we investigate how to improve reward modeling (RM) with more inference compute for general queries, i.e. the $\textbf{inference-time scalability of generalist RM}$, and further, how to improve the effectiveness of performance-compute scaling with proper learning methods. For the RM approach, we adopt pointwise generative reward modeling (GRM) to enable flexibility for different input types and potential for inference-time scaling. For the learning method, we propose Self-Principled Critique Tuning (SPCT) to foster scalable reward generation behaviors in GRMs through online RL, to generate principles adaptively and critiques accurately, resulting in $\textbf{DeepSeek-GRM}$ models. Furthermore, for effective inference-time scaling, we use parallel sampling to expand compute usage, and introduce a meta RM to guide voting process for better scaling performance. Empirically, we show that SPCT significantly improves the quality and scalability of GRMs, outperforming existing methods and models in various RM benchmarks without severe biases, and could achieve better performance compared to training-time scaling. DeepSeek-GRM still meets challenges in some tasks, which we believe can be addressed by future efforts in generalist reward systems. The models are released at Hugging Face and ModelScope.