LearNAT: Learning NL2SQL with AST-guided Task Decomposition for Large Language Models
作者: Weibin Liao, Xin Gao, Tianyu Jia, Rihong Qiu, Yifan Zhu, Yang Lin, Xu Chu, Junfeng Zhao, Yasha Wang
分类: cs.CL
发布日期: 2025-04-03
💡 一句话要点
LearNAT:利用AST引导的任务分解提升大语言模型在NL2SQL任务上的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: NL2SQL 任务分解 强化学习 抽象语法树 大语言模型
📋 核心要点
- 现有NL2SQL方法依赖闭源LLM或微调开源LLM,但在复杂任务中,开源LLM受限于用户意图的间接表达和语义鸿沟。
- LearNAT框架通过AST引导的任务分解和强化学习,提升开源LLM在复杂NL2SQL任务上的性能。
- 实验表明,LearNAT使7B参数的开源LLM达到与GPT-4相当的性能,同时提高了效率和可访问性。
📝 摘要(中文)
自然语言到SQL (NL2SQL) 已经成为实现与数据库无缝交互的关键任务。最近,大型语言模型 (LLM) 在该领域表现出卓越的性能。然而,现有的NL2SQL方法主要依赖于利用提示工程的闭源LLM,而开源模型通常需要进行微调以获得特定领域的知识。尽管如此,由于用户查询目标的间接表达以及用户查询和数据库模式之间的语义差距,开源LLM在复杂的NL2SQL任务中仍然面临挑战。受到强化学习在数学问题解决中鼓励LLM逐步推理的启发,我们提出了LearNAT (Learning NL2SQL with AST-guided Task Decomposition),这是一个新颖的框架,通过任务分解和强化学习来提高开源LLM在复杂NL2SQL任务上的性能。LearNAT 引入了三个关键组件:(1) 一个分解合成过程,利用抽象语法树 (AST) 来指导任务分解的有效搜索和剪枝策略,(2) 边际感知强化学习,它通过带有AST边际的DPO进行细粒度的步级优化,以及 (3) 自适应演示推理,一种用于动态选择相关示例以增强分解能力的机制。在 Spider 和 BIRD 两个基准数据集上的大量实验表明,LearNAT 使一个 7B 参数的开源 LLM 能够达到与 GPT-4 相当的性能,同时提供更高的效率和可访问性。
🔬 方法详解
问题定义:论文旨在解决开源大型语言模型(LLM)在复杂NL2SQL任务中表现不佳的问题。现有方法要么依赖闭源LLM,要么需要对开源LLM进行微调,但由于用户查询目标表达的间接性和用户查询与数据库模式之间的语义差距,开源LLM在处理复杂查询时仍然存在困难。
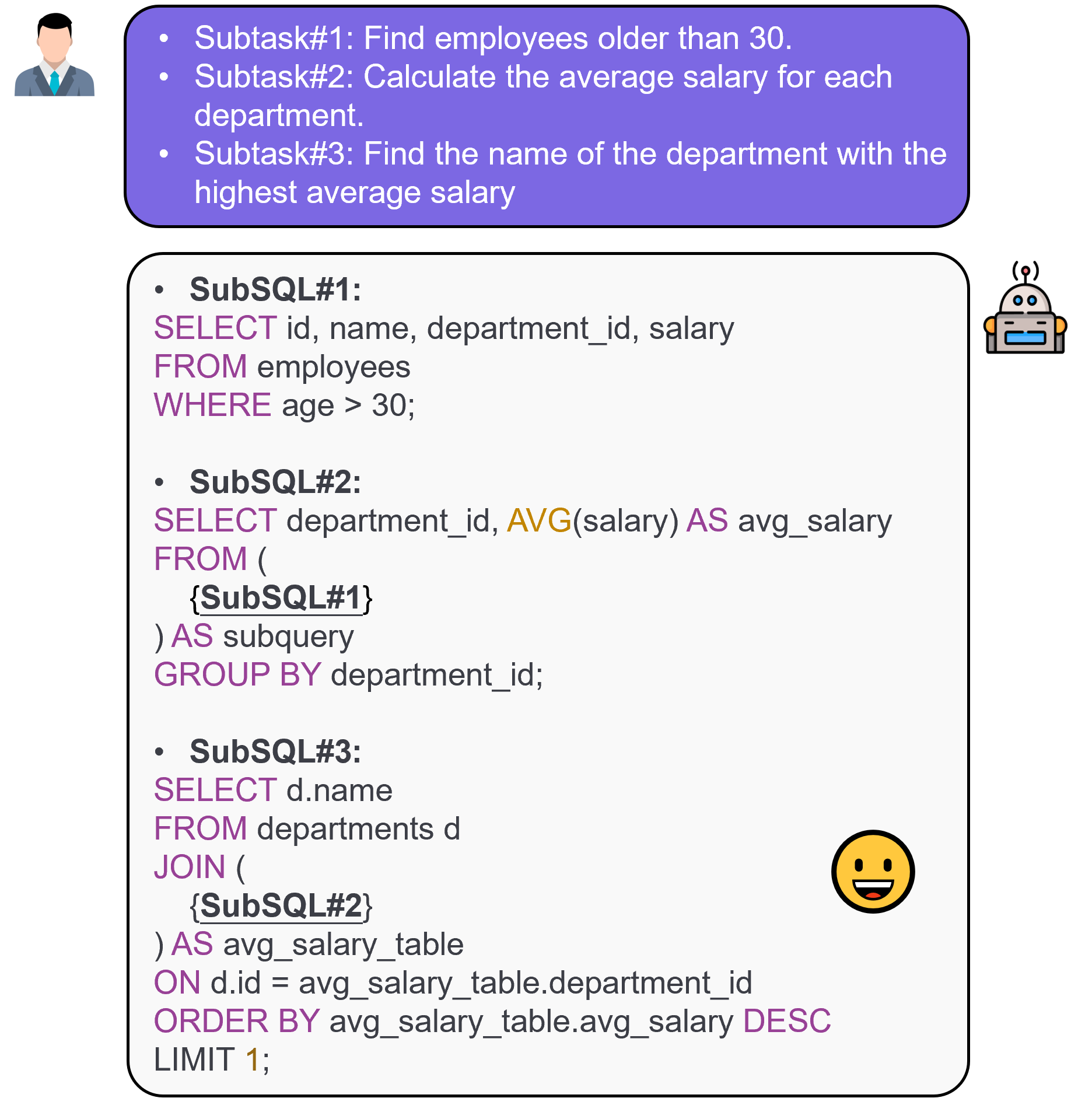
核心思路:论文的核心思路是将复杂的NL2SQL任务分解为更小的、更易于管理的子任务,并利用抽象语法树(AST)来指导任务分解过程。通过强化学习,模型可以学习如何有效地分解任务,并逐步生成正确的SQL查询。这种分解策略借鉴了人类解决复杂问题的思维方式,即分而治之。
技术框架:LearNAT框架包含三个主要组成部分:(1) 分解合成过程:利用AST指导任务分解的搜索和剪枝策略,高效地将复杂NL2SQL任务分解为子任务。(2) 边际感知强化学习:通过带有AST边际的DPO算法进行细粒度的步级优化,提升模型在每一步分解中的准确性。(3) 自适应演示推理:动态选择相关示例,以增强模型在任务分解方面的能力。整体流程是,给定一个NL查询,首先通过分解合成过程将其分解为一系列子任务,然后利用强化学习优化分解策略,最后通过自适应演示推理选择合适的示例来指导分解过程。
关键创新:LearNAT的关键创新在于利用AST来指导任务分解,并结合强化学习进行优化。与传统的端到端方法相比,LearNAT能够更好地处理复杂查询,因为它将问题分解为更小的、更易于理解的部分。此外,边际感知强化学习和自适应演示推理进一步提升了模型的性能。
关键设计:分解合成过程利用AST来表示SQL查询的结构,并根据AST的结构进行任务分解。边际感知强化学习使用DPO算法,并结合AST边际来优化模型在每一步分解中的决策。自适应演示推理使用一种动态选择策略,根据当前查询的特征选择最相关的示例。
🖼️ 关键图片


📊 实验亮点
在Spider和BIRD两个基准数据集上的实验表明,LearNAT框架使一个7B参数的开源LLM能够达到与GPT-4相当的性能。具体来说,LearNAT在Spider数据集上取得了显著的性能提升,并在BIRD数据集上也表现出强大的竞争力,证明了其在复杂NL2SQL任务上的有效性。
🎯 应用场景
LearNAT框架具有广泛的应用前景,可用于构建更智能、更易用的数据库交互系统。它可以应用于金融、医疗、电商等领域,帮助用户通过自然语言查询数据库,从而提高数据分析和决策效率。此外,该研究可以促进开源LLM在NL2SQL领域的应用,降低数据库交互的成本和门槛。
📄 摘要(原文)
Natural Language to SQL (NL2SQL) has emerged as a critical task for enabling seamless interaction with databases. Recent advancements in Large Language Models (LLMs) have demonstrated remarkable performance in this domain. However, existing NL2SQL methods predominantly rely on closed-source LLMs leveraging prompt engineering, while open-source models typically require fine-tuning to acquire domain-specific knowledge. Despite these efforts, open-source LLMs struggle with complex NL2SQL tasks due to the indirect expression of user query objectives and the semantic gap between user queries and database schemas. Inspired by the application of reinforcement learning in mathematical problem-solving to encourage step-by-step reasoning in LLMs, we propose LearNAT (Learning NL2SQL with AST-guided Task Decomposition), a novel framework that improves the performance of open-source LLMs on complex NL2SQL tasks through task decomposition and reinforcement learning. LearNAT introduces three key components: (1) a Decomposition Synthesis Procedure that leverages Abstract Syntax Trees (ASTs) to guide efficient search and pruning strategies for task decomposition, (2) Margin-aware Reinforcement Learning, which employs fine-grained step-level optimization via DPO with AST margins, and (3) Adaptive Demonstration Reasoning, a mechanism for dynamically selecting relevant examples to enhance decomposition capabilities. Extensive experiments on two benchmark datasets, Spider and BIRD, demonstrate that LearNAT enables a 7B-parameter open-source LLM to achieve performance comparable to GPT-4, while offering improved efficiency and accessibility.