Reasoning Transfer for an Extremely Low-Resource and Endangered Language: Bridging Languages Through Sample-Efficient Language Understanding
作者: Khanh-Tung Tran, Barry O'Sullivan, Hoang D. Nguyen
分类: cs.CL, cs.AI
发布日期: 2025-04-02 (更新: 2025-11-26)
💡 一句话要点
提出英语枢轴CoT训练,解决极低资源语言的推理迁移问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源语言 思维链 推理迁移 跨语言学习 数学推理
📋 核心要点
- 现有CoT方法在低资源语言上表现不佳,无法有效利用LLM的推理能力。
- 提出英语枢轴CoT训练,利用LLM内部对齐的潜在空间,先用英语生成CoT,再翻译回目标语言。
- 实验表明,该方法在低资源数学推理任务上显著优于其他基线,最高提升28.33%。
📝 摘要(中文)
大型语言模型(LLM)通过生成思维链(CoT)推理在推理任务中取得了显著进展,但这些成果主要集中在高资源语言上,低资源语言则相对滞后。本文首先研究了在极低资源场景下,通过提示、模型编辑和微调等方法应用CoT技术。我们提出了英语枢轴CoT训练,利用LLM在潜在空间中倾向于与主要语言对齐的特性。给定低资源语言的输入,我们执行监督微调以生成英语的CoT,并以目标语言输出最终响应。在数学推理基准测试中,我们的方法优于其他基线,在低资源场景下提升高达28.33%。我们的分析和额外实验,包括混合语言CoT和两阶段训练,表明将语言理解与推理显式分离可以增强跨语言推理能力。为了促进未来的研究,我们还发布了LC2024,这是第一个针对极低资源和濒危语言爱尔兰语的数学任务基准。我们的结果和资源突出了在数据稀缺的情况下,实现多语言推理的实用途径,而无需在每种极低资源语言中进行广泛的重新训练。
🔬 方法详解
问题定义:论文旨在解决极低资源语言的推理能力问题,特别是数学推理。现有方法,如直接提示、模型编辑和微调等,在这些语言上的表现不佳,无法充分利用大型语言模型的推理潜力。主要痛点在于缺乏足够的训练数据,导致模型难以学习到有效的推理模式。
核心思路:论文的核心思路是利用大型语言模型内部的语言对齐特性,即LLM在潜在空间中倾向于与高资源语言(如英语)对齐。因此,将低资源语言的推理过程桥接到英语,可以借助LLM在英语上的强大推理能力。具体而言,先将低资源语言的输入翻译成英语,然后生成英语的CoT推理过程,最后将推理结果翻译回目标语言。
技术框架:整体框架包含以下几个主要阶段:1) 输入:接收低资源语言的数学问题。2) 翻译(可选):将低资源语言的问题翻译成英语(如果需要)。3) 英语CoT生成:使用微调后的LLM,基于英语问题生成CoT推理过程。4) 答案提取:从英语CoT中提取最终答案。5) 翻译(可选):将英语答案翻译回低资源语言。
关键创新:最重要的创新点在于英语枢轴CoT训练方法,它显式地将语言理解和推理过程分离。通过在英语上进行CoT生成,可以有效利用LLM在英语上的预训练知识和推理能力,从而克服低资源语言数据稀缺的限制。与直接在低资源语言上进行CoT训练相比,该方法能够更好地泛化到新的推理任务。
关键设计:论文采用监督微调的方式训练LLM生成英语CoT。具体而言,使用低资源语言的数学问题作为输入,对应的英语CoT作为目标输出。损失函数采用标准的交叉熵损失。在实验中,作者探索了不同的LLM架构和微调策略。此外,论文还提出了混合语言CoT和两阶段训练等变体,进一步提升模型的性能。
🖼️ 关键图片

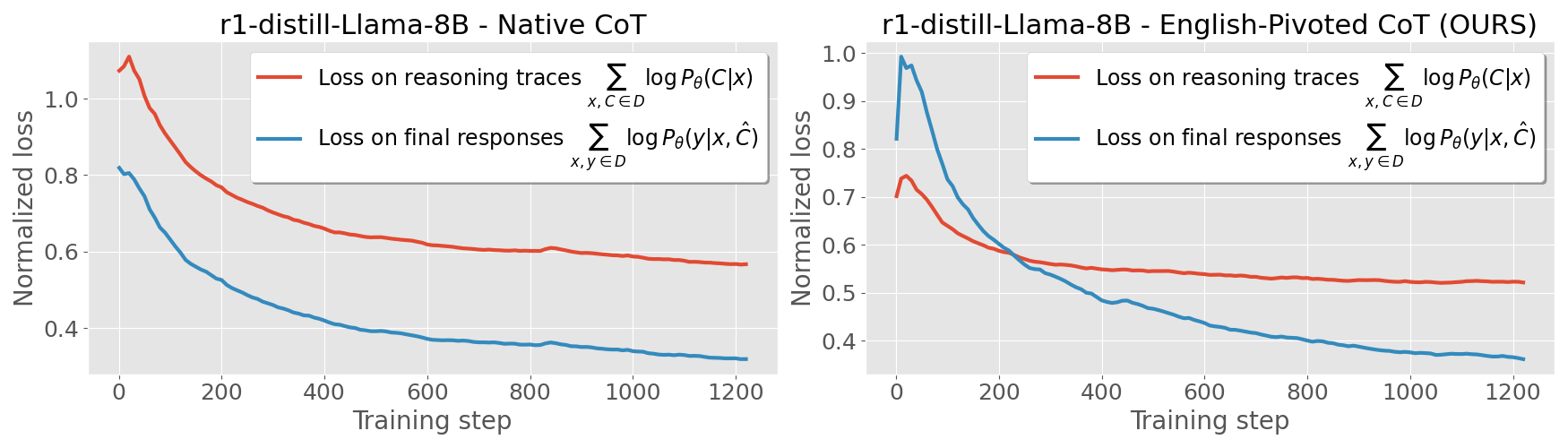
📊 实验亮点
实验结果表明,英语枢轴CoT训练在低资源数学推理任务上取得了显著的提升。在爱尔兰语数据集上,该方法优于其他基线,最高提升28.33%。此外,混合语言CoT和两阶段训练等变体也进一步提升了模型的性能。这些结果表明,将语言理解和推理显式分离可以有效增强跨语言推理能力。
🎯 应用场景
该研究成果可应用于各种低资源语言的自然语言处理任务,尤其是在教育、文化遗产保护和信息可访问性等领域。例如,可以开发低资源语言的智能辅导系统,帮助学生学习数学等科目。此外,该方法还可以用于构建低资源语言的知识库和问答系统,促进文化交流和信息传播。未来,该技术有望扩展到其他推理任务和语言,实现真正的多语言智能。
📄 摘要(原文)
Recent advances have enabled Large Language Models (LLMs) to tackle reasoning tasks by generating chain-of-thought (CoT) rationales, yet these gains have largely applied to high-resource languages, leaving low-resource languages behind. In this work, we first investigate CoT techniques in extremely low-resource scenarios through previous prompting, model-editing, and fine-tuning approaches. We introduce English-Pivoted CoT Training, leveraging the insight that LLMs internally operate in a latent space aligned toward the dominant language. Given input in a low-resource language, we perform supervised fine-tuning to generate CoT in English and output the final response in the target language. Across mathematical reasoning benchmarks, our approach outperforms other baselines with up to 28.33% improvement in low-resource scenarios. Our analysis and additional experiments, including Mixed-Language CoT and Two-Stage Training, show that explicitly separating language understanding from reasoning enhances cross-lingual reasoning abilities. To facilitate future work, we also release \emph{LC2024}, the first benchmark for mathematical tasks in Irish, an extremely low-resource and endangered language. Our results and resources highlight a practical pathway to multilingual reasoning without extensive retraining in every extremely low-resource language, despite data scarcity.