One Pic is All it Takes: Poisoning Visual Document Retrieval Augmented Generation with a Single Image
作者: Ezzeldin Shereen, Dan Ristea, Shae McFadden, Burak Hasircioglu, Vasilios Mavroudis, Chris Hicks
分类: cs.CL, cs.CR, cs.CV, cs.IR
发布日期: 2025-04-02 (更新: 2025-11-20)
💡 一句话要点
揭示视觉文档RAG易受投毒攻击的脆弱性:单张恶意图片即可破坏检索与生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉文档RAG 投毒攻击 对抗样本 信息安全 检索增强生成
📋 核心要点
- 现有的基于文本的RAG方法在处理包含丰富多模态信息的文档(如PDF)时存在局限性,无法充分利用视觉信息。
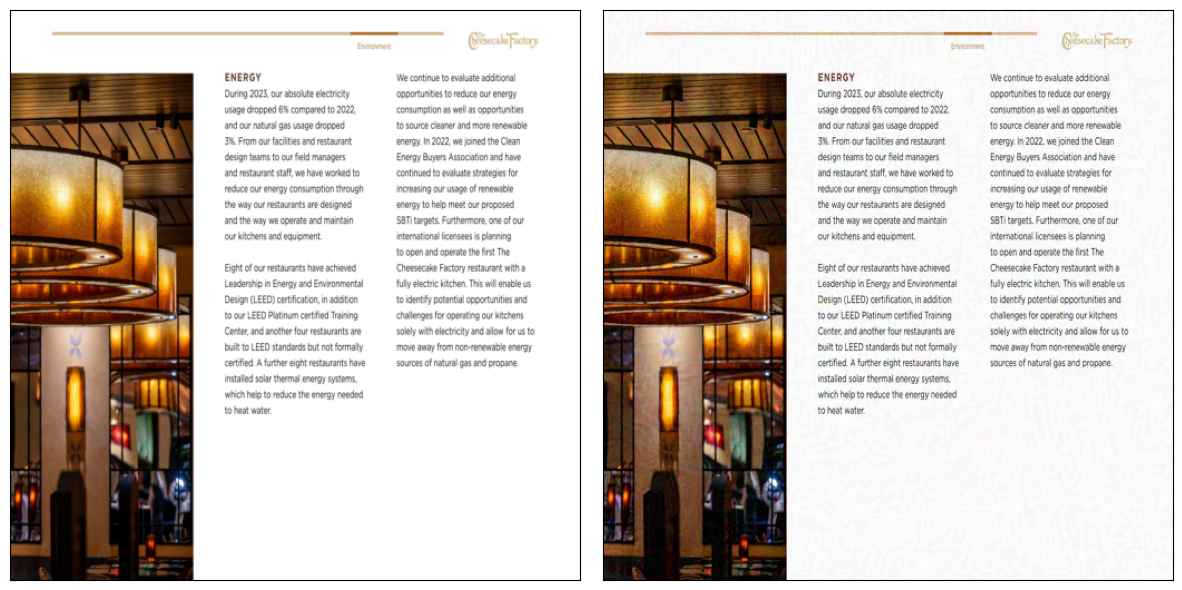
- 论文提出针对视觉文档RAG(VD-RAG)的投毒攻击方法,通过注入单张恶意图片即可干扰检索和生成过程。
- 实验证明,VD-RAG在定向和通用设置下均易受投毒攻击,但在通用设置的黑盒攻击中表现出一定的鲁棒性。
📝 摘要(中文)
检索增强生成(RAG)通过使用事实知识库(KB)来抑制大型语言模型(LLM)中的幻觉。虽然PDF文档是重要的知识来源,但基于文本的RAG管道无法有效地捕获其丰富的多模态信息。相比之下,视觉文档RAG(VD-RAG)使用文档页面的屏幕截图作为KB,已被证明可以实现最先进的结果。然而,通过引入图像模态,VD-RAG引入了新的攻击向量,攻击者可以通过将恶意文档注入KB来破坏系统。本文证明了VD-RAG对针对检索和生成的投毒攻击的脆弱性。我们定义了两个攻击目标,并证明只需将一张对抗性图像注入KB即可实现这两个目标。首先,我们提出了一种针对一个或一组查询的定向攻击,旨在传播有针对性的虚假信息。其次,我们提出了一种通用攻击,对于任何潜在的用户查询,都会影响响应,从而导致VD-RAG系统中的拒绝服务。我们研究了在白盒和黑盒假设下的两个攻击目标,采用了多目标基于梯度的优化方法以及提示最先进的生成模型。使用两个视觉文档数据集、一组不同的最先进的检索器(嵌入模型)和生成器(视觉语言模型),我们表明VD-RAG在定向和通用设置中都容易受到投毒攻击,但在通用设置中表现出对黑盒攻击的鲁棒性。
🔬 方法详解
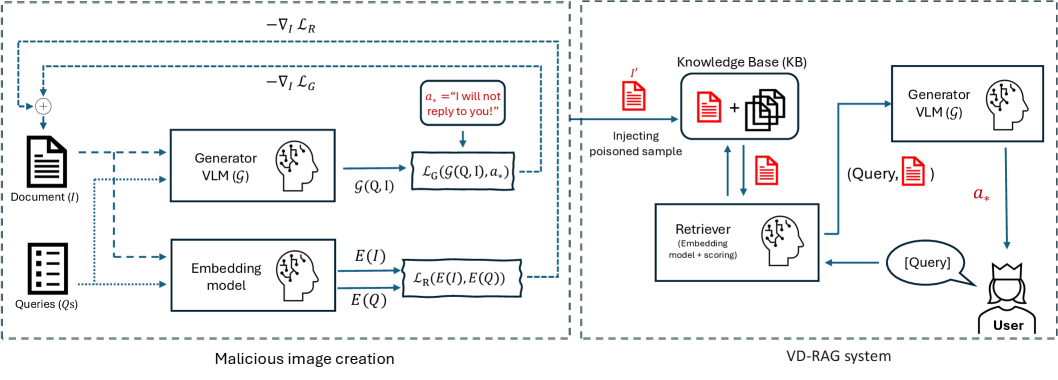
问题定义:论文旨在揭示视觉文档检索增强生成(VD-RAG)系统对投毒攻击的脆弱性。现有基于文本的RAG方法无法有效处理包含图像的文档,而VD-RAG虽然利用了图像信息,但也引入了新的攻击面。攻击者可以通过注入恶意图像来干扰系统的检索和生成过程,从而传播虚假信息或导致服务中断。
核心思路:论文的核心思路是,通过精心设计的对抗性图像,影响VD-RAG系统的检索结果,使其检索到包含错误信息的文档,从而误导后续的生成过程。这种攻击只需要注入一张图像,就能对特定查询或所有查询产生影响。
技术框架:该研究主要包含以下几个关键模块:1) VD-RAG系统:包括图像检索器(用于从知识库中检索相关图像)和视觉语言模型(用于基于检索到的图像生成答案)。2) 攻击目标定义:包括定向攻击(针对特定查询)和通用攻击(影响所有查询)。3) 攻击方法:包括白盒攻击(攻击者了解系统内部结构和参数)和黑盒攻击(攻击者只能通过输入输出进行攻击)。4) 对抗样本生成:使用基于梯度的优化方法或提示生成模型来生成对抗性图像。
关键创新:该论文的关键创新在于证明了仅需单张对抗性图像即可有效攻击VD-RAG系统,突显了该系统在安全性方面的脆弱性。此外,论文还提出了针对定向攻击和通用攻击的不同攻击策略,并研究了在白盒和黑盒条件下的攻击效果。
关键设计:在对抗样本生成方面,论文采用了多目标优化方法,同时考虑了攻击成功率和图像的视觉相似度。在白盒攻击中,使用梯度信息来调整图像像素,以最大化攻击目标函数。在黑盒攻击中,则利用生成模型生成具有欺骗性的图像。具体的损失函数和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过注入单张对抗性图像,可以成功实现针对VD-RAG系统的定向攻击和通用攻击。在白盒攻击设置下,攻击成功率较高。虽然在通用设置的黑盒攻击中,VD-RAG表现出一定的鲁棒性,但仍然存在被攻击的风险。具体的性能数据和提升幅度未在摘要中给出,属于未知信息。
🎯 应用场景
该研究对提升视觉文档RAG系统的安全性具有重要意义。研究结果可以帮助开发者更好地理解和防范针对VD-RAG系统的投毒攻击,从而构建更安全可靠的知识密集型应用,例如智能文档处理、信息检索和问答系统等。未来的研究可以探索更有效的防御机制,例如对抗训练和输入验证。
📄 摘要(原文)
Retrieval-augmented generation (RAG) is instrumental for inhibiting hallucinations in large language models (LLMs) through the use of a factual knowledge base (KB). Although PDF documents are prominent sources of knowledge, text-based RAG pipelines are ineffective at capturing their rich multi-modal information. In contrast, visual document RAG (VD-RAG) uses screenshots of document pages as the KB, which has been shown to achieve state-of-the-art results. However, by introducing the image modality, VD-RAG introduces new attack vectors for adversaries to disrupt the system by injecting malicious documents into the KB. In this paper, we demonstrate the vulnerability of VD-RAG to poisoning attacks targeting both retrieval and generation. We define two attack objectives and demonstrate that both can be realized by injecting only a single adversarial image into the KB. Firstly, we introduce a targeted attack against one or a group of queries with the goal of spreading targeted disinformation. Secondly, we present a universal attack that, for any potential user query, influences the response to cause a denial-of-service in the VD-RAG system. We investigate the two attack objectives under both white-box and black-box assumptions, employing a multi-objective gradient-based optimization approach as well as prompting state-of-the-art generative models. Using two visual document datasets, a diverse set of state-of-the-art retrievers (embedding models) and generators (vision language models), we show VD-RAG is vulnerable to poisoning attacks in both the targeted and universal settings, yet demonstrating robustness to black-box attacks in the universal setting.