Testing Low-Resource Language Support in LLMs Using Language Proficiency Exams: the Case of Luxembourgish
作者: Cedric Lothritz, Jordi Cabot, Laura Bernardy
分类: cs.CL
发布日期: 2025-04-02 (更新: 2026-01-15)
备注: 24pages, 4 figures, 14 tables
💡 一句话要点
利用语言能力考试评估LLM对低资源语言的支持:以卢森堡语为例
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 低资源语言 卢森堡语 语言能力考试 模型评估
📋 核心要点
- 现有LLM主要针对高资源语言开发,对卢森堡语等低资源语言的支持不足,缺乏有效的评估工具和数据集。
- 该研究探索了使用语言能力考试作为评估LLM在卢森堡语上表现的有效方法,为低资源语言的评估提供新思路。
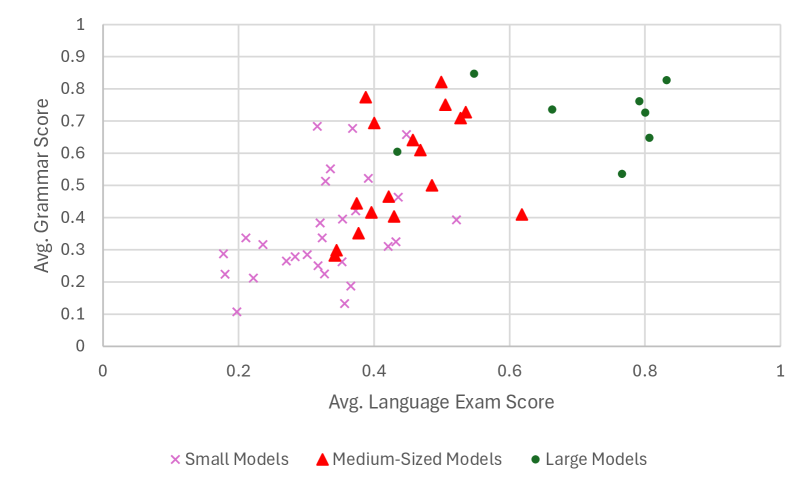
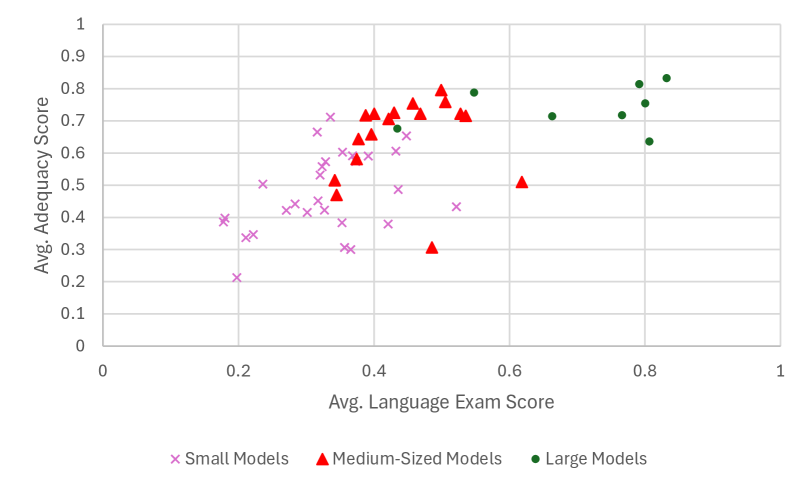
- 实验结果表明,大型LLM在卢森堡语能力考试中表现良好,且考试成绩能预测模型在其他NLP任务中的表现。
📝 摘要(中文)
大型语言模型(LLM)在研究和社会中扮演着越来越重要的角色。尽管专家和普通用户都在全球范围内广泛使用LLM,但它们主要针对以英语为母语的用户而开发,在英语和其他广泛使用的语言中表现良好,而卢森堡语等资源较少的语言则被视为优先级较低。这种缺乏关注也反映在可用评估工具和数据集的稀缺性上。在本研究中,我们调查了语言能力考试作为卢森堡语评估工具的可行性。我们发现,Claude和DeepSeek-R1等大型模型通常能获得高分,而较小的模型则表现较弱。我们还发现,此类语言考试中的表现可用于预测卢森堡语中其他NLP任务的表现。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)对低资源语言(以卢森堡语为例)的支持程度。现有方法缺乏针对低资源语言的有效评估工具和数据集,难以准确衡量LLM在这些语言上的性能。这导致LLM在低资源语言上的应用受到限制。
核心思路:论文的核心思路是利用现有的语言能力考试作为评估LLM在低资源语言上表现的指标。通过将LLM的输出与语言能力考试的答案进行比较,可以量化LLM对该语言的掌握程度。这种方法无需构建新的数据集,利用了已有的资源。
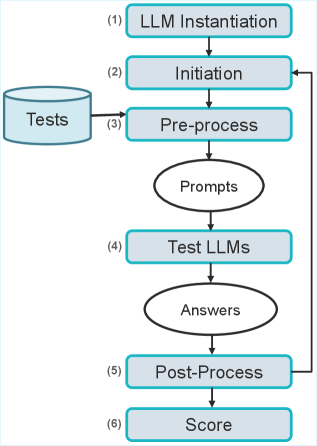
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择合适的卢森堡语语言能力考试;2) 将考试题目输入到不同的LLM中,获取模型的输出;3) 将模型的输出与标准答案进行比较,计算得分;4) 分析不同LLM的得分情况,评估其在卢森堡语上的表现;5) 将语言能力考试的得分与LLM在其他NLP任务(如翻译、文本生成等)上的表现进行关联,验证语言能力考试的预测能力。
关键创新:该研究的关键创新在于将语言能力考试应用于评估LLM对低资源语言的支持。与传统的评估方法相比,这种方法具有以下优势:1) 无需构建新的数据集,节省了时间和资源;2) 语言能力考试能够全面评估LLM对语言的掌握程度,包括语法、词汇、阅读理解等方面;3) 语言能力考试的结果具有可解释性,可以帮助研究人员了解LLM在哪些方面表现良好,哪些方面需要改进。
关键设计:论文中没有详细描述关键的参数设置、损失函数、网络结构等技术细节,因为其重点在于评估方法而非模型本身。研究中使用了现成的LLM,如Claude和DeepSeek-R1,并直接利用它们的输出进行评估。对于语言能力考试的评分,采用了标准的评分规则,确保评估的客观性和公正性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,大型LLM(如Claude和DeepSeek-R1)在卢森堡语能力考试中表现出色,而较小的模型则表现较弱。更重要的是,研究发现语言能力考试的成绩能够有效预测LLM在其他卢森堡语NLP任务中的表现,验证了该评估方法的有效性。
🎯 应用场景
该研究成果可应用于评估和改进LLM对低资源语言的支持,促进LLM在多语言环境下的应用。语言能力考试评估方法可以推广到其他低资源语言,为开发更具包容性的LLM提供参考。此外,该研究也为低资源语言的数字化和保护提供了新的思路。
📄 摘要(原文)
Large Language Models (LLMs) have become an increasingly important tool in research and society at large. While LLMs are regularly used all over the world by experts and lay-people alike, they are predominantly developed with English-speaking users in mind, performing well in English and other wide-spread languages while less-resourced languages such as Luxembourgish are seen as a lower priority. This lack of attention is also reflected in the sparsity of available evaluation tools and datasets. In this study, we investigate the viability of language proficiency exams as such evaluation tools for the Luxembourgish language. We find that large models such as Claude and DeepSeek-R1 typically achieve high scores, while smaller models show weak performances. We also find that the performances in such language exams can be used to predict performances in other NLP tasks in Luxembourgish.