Register Always Matters: Analysis of LLM Pretraining Data Through the Lens of Language Variation
作者: Amanda Myntti, Erik Henriksson, Veronika Laippala, Sampo Pyysalo
分类: cs.CL
发布日期: 2025-04-02 (更新: 2025-09-09)
💡 一句话要点
通过语域视角分析LLM预训练数据,揭示语域对模型性能的关键影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预训练数据 语域分析 文本分类 模型性能评估
📋 核心要点
- 现有LLM预训练数据筛选方法过于简化,缺乏对不同文本类型贡献的细致理解。
- 本研究利用语域(体裁)这一语言学标准,对预训练数据进行分类和分析,考察其对LLM性能的影响。
- 实验表明,语域对模型性能有显著影响,特定语域组合能带来性能提升,并揭示了各语域的优缺点。
📝 摘要(中文)
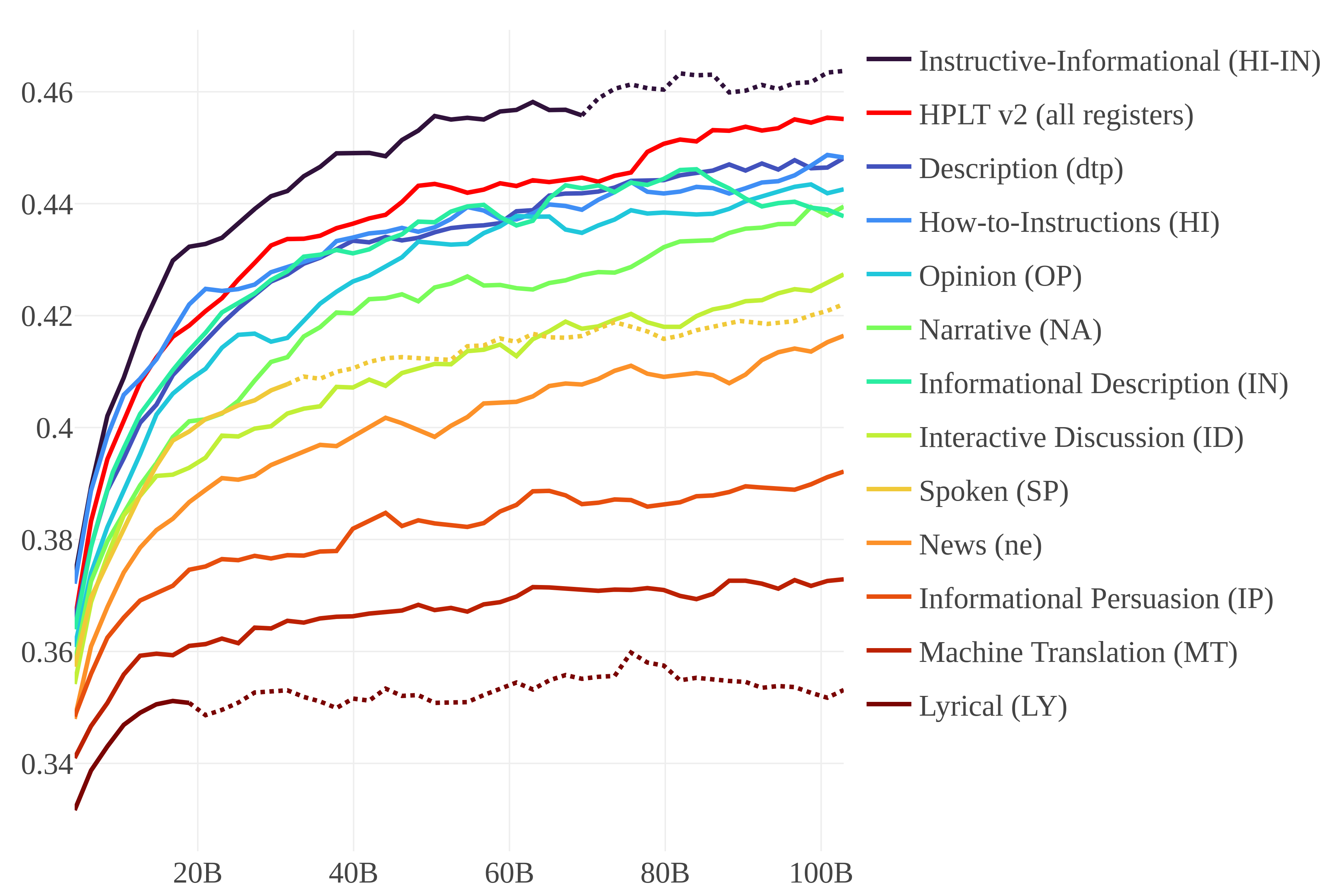
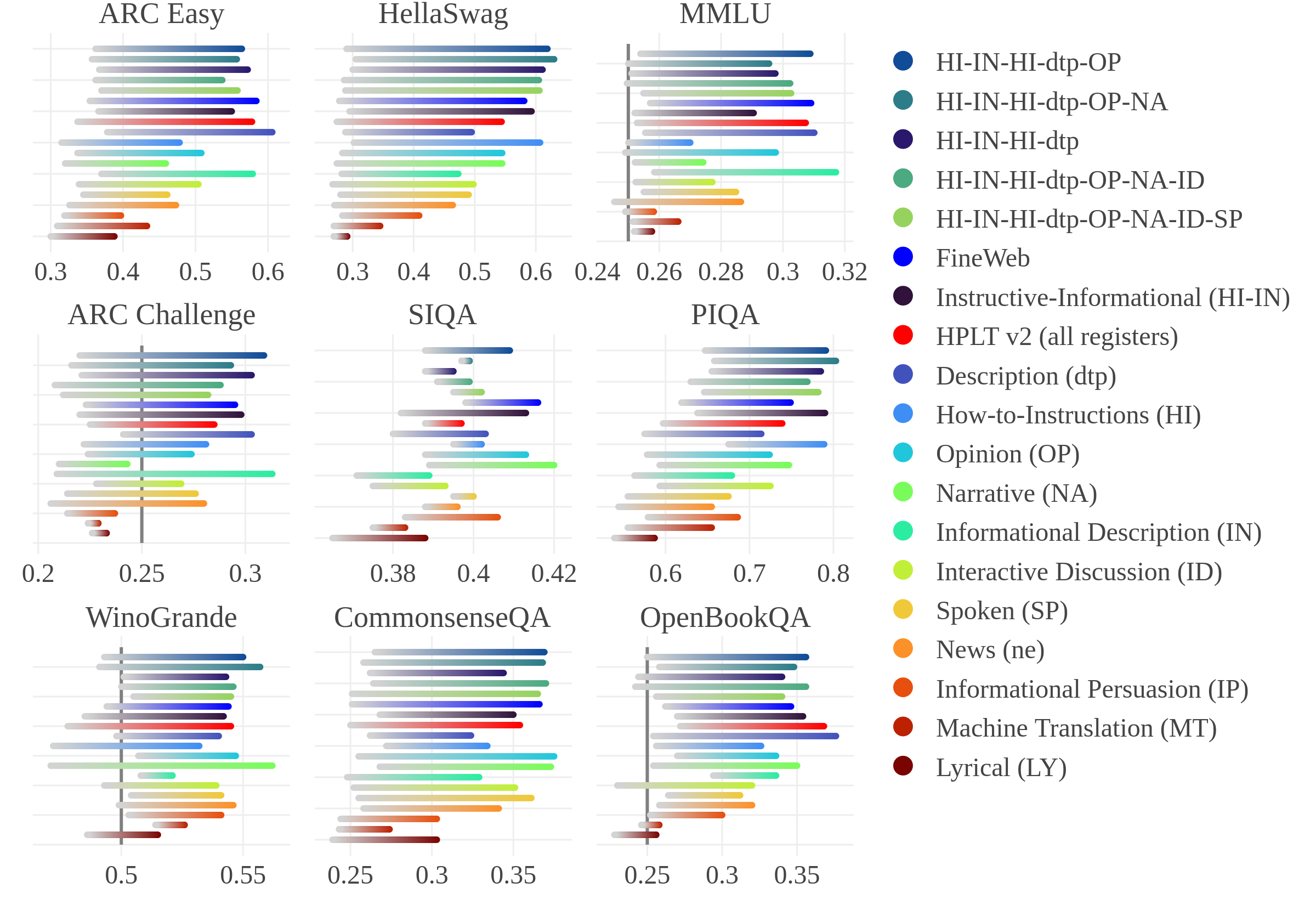
预训练数据筛选是大型语言模型(LLM)开发中的基石,促使越来越多的研究关注大规模网络语料库的质量过滤。从统计质量标志到基于LLM的标注系统,数据集被划分为不同的类别,通常简化为二元分类:通过过滤器的被认为是宝贵的例子,其他的则被丢弃为无用或有害的。然而,对于不同类型的文本对模型性能的贡献的更详细的理解仍然很大程度上缺乏。在本文中,我们提出了第一个利用语域或体裁(语料库语言学中广泛使用的用于建模语言变异的标准)来管理预训练数据集并研究语域对LLM性能的影响的研究。我们使用语域分类的数据训练小型生成模型,并使用标准基准评估它们,结果表明预训练数据的语域对模型性能有很大影响。我们发现了预训练材料和生成的模型之间令人惊讶的关系:使用新闻语域会导致次优的性能,相反,包括意见类(涵盖评论和意见博客等文本)是非常有益的。虽然在整个未过滤的数据集上训练的模型优于那些在仅限于单个语域的数据集上训练的模型,但结合表现良好的语域(如操作指南、信息描述和意见)可以带来重大改进。此外,对单个基准测试结果的分析揭示了特定语域类别作为预训练数据的优势和缺点的关键差异。这些发现表明,语域是模型变异的重要解释因素,可以促进未来更慎重的数据选择实践。
🔬 方法详解
问题定义:现有LLM预训练数据筛选方法通常采用二元分类,将数据简单划分为“有用”和“无用”,忽略了不同类型文本(如新闻、评论、教程等)对模型学习的差异化影响。这种粗粒度的筛选方式可能导致模型性能的次优化,无法充分利用各种文本的优势。现有方法缺乏对预训练数据中语言变异性的深入理解。
核心思路:本研究的核心思路是利用语域(register)这一语言学概念,将预训练数据按照不同的文本类型进行分类,并分别训练模型,从而考察不同语域对模型性能的影响。通过分析不同语域训练出的模型的优缺点,可以为未来的预训练数据选择提供更精细化的指导。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 使用语域分类器对大规模预训练数据进行分类,将数据划分为不同的语域类别(如新闻、意见、操作指南等)。2) 使用不同语域的数据分别训练小型生成模型。3) 使用标准基准测试评估这些模型的性能。4) 分析不同语域训练出的模型在不同基准测试上的表现,从而揭示不同语域的优势和劣势。
关键创新:本研究的关键创新在于将语域这一语言学概念引入到LLM预训练数据的分析中。与以往的基于统计或LLM的二元分类方法不同,本研究关注的是不同文本类型的差异,并考察这些差异对模型性能的影响。这种基于语域的分析方法可以为预训练数据的选择提供更细粒度的指导。
关键设计:研究中使用了小型生成模型进行实验,以便在有限的计算资源下快速评估不同语域的影响。具体使用的模型架构和训练参数未知。语域分类器的具体实现方式也未知。评估基准测试的具体选择也未知,但使用了“标准基准”。研究重点在于不同语域数据训练出的模型在不同基准测试上的相对表现,而非追求绝对性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,新闻语域的预训练数据会导致模型性能下降,而包含评论和博客等文本的意见语域则对模型性能有益。结合操作指南、信息描述和意见等语域的数据可以显著提升模型性能。对不同基准测试的分析揭示了特定语域的优势和劣势。
🎯 应用场景
该研究成果可应用于LLM预训练数据的优化选择,通过合理搭配不同语域的数据,提升模型在特定任务上的性能。例如,针对需要生成高质量评论的LLM,可以增加评论语域的数据比例。此外,该研究也为理解LLM的学习机制提供了新的视角,有助于开发更有效的预训练方法。
📄 摘要(原文)
Pretraining data curation is a cornerstone in Large Language Model (LLM) development, leading to growing research on quality filtering of large web corpora. From statistical quality flags to LLM-based labelling systems, datasets are divided into categories, frequently reducing to a binary: those passing the filters are deemed as valuable examples, others are discarded as useless or detrimental. However, a more detailed understanding of the contribution of different kinds of texts to model performance is still largely lacking. In this article, we present the first study utilising registers or genres - a widely used standard in corpus linguistics to model linguistic variation - to curate pretraining datasets and investigate the effect of register on the performance of LLMs. We train small generative models with register classified data and evaluate them using standard benchmarks, and show that the register of pretraining data substantially affects model performance. We uncover surprising relationships between the pretraining material and the resulting models: using the News register results in subpar performance, and on the contrary, including the Opinion class, covering texts such as reviews and opinion blogs, is highly beneficial. While a model trained on the entire unfiltered dataset outperforms those trained on datasets limited to a single register, combining well-performing registers like How-to-Instructions, Informational Description, and Opinion leads to major improvements. Furthermore, analysis of individual benchmark results reveals key differences in the strengths and drawbacks of specific register classes as pretraining data. These findings show that register is an important explainer of model variation and can facilitate more deliberate future data selection practices.