Text Chunking for Document Classification for Urban System Management using Large Language Models
作者: Joshua Rodriguez, Om Sanan, Guillermo Vizarreta-Luna, Steven A. Conrad
分类: cs.CL, cs.HC
发布日期: 2025-03-31
备注: 16 pages, 6 figures, 4 tables, 2 algorithms; Replication data and code can be found https://github.com/josh-rodriguez-csu/ChunkingforLLMs
💡 一句话要点
提出基于文本分块的LLM方案,用于城市系统管理文档分类,性能媲美人工。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本分块 文档分类 城市系统管理 定性编码
📋 核心要点
- 城市系统管理依赖复杂的文本资料,人工编码分析耗时耗力,且易受主观偏差影响。
- 提出基于文本分块的提示方法,利用LLM进行文档分类,旨在减少资源需求并提高编码一致性。
- 实验表明,GPT-4o等模型采用分块方法时,与人工评估者具有显著一致性,可作为辅助评估工具。
📝 摘要(中文)
本文研究了将大型语言模型(LLM)应用于定性编码活动,以在保持与人类相当的可靠性的同时,减少资源需求。定性编码和评估面临资源限制、偏差、准确性以及人类评估者之间一致性等挑战。本文报告了使用LLM演绎编码10个案例文档,以确定城市系统管理的17个数字孪生特征。我们利用两种提示方法来比较LLM与人工编码的语义处理:全文分析和文本分块分析,使用的模型包括OpenAI的GPT-4o、GPT-4o-mini和o1-mini。研究发现,不同方法之间存在相似的内部变异趋势,结果表明,当使用特定的演绎编码上下文初始化时,LLM的性能可能与人工编码员相当。使用分块方法时,GPT-4o、o1-mini和GPT-4o-mini与人类评估者表现出显著的一致性。将GPT-4o和GPT-4o-mini作为额外的评估者与三个人工评估者一起使用时,所有评估者之间都表现出统计学上的显著一致性,表明LLM有益于文本文件的分析。我们的发现揭示了LLM应用的细微子主题,表明LLM遵循人类记忆编码过程,其中全文分析可能会引入多种含义。本文的新颖之处在于评估OpenAI GPT模型的性能,并引入基于分块的提示方法,该方法通过保留局部上下文来解决上下文聚合偏差。
🔬 方法详解
问题定义:城市系统管理需要处理大量的文本资料,例如政策文件、规划报告等。人工对这些文档进行编码和分类,以提取关键信息,用于需求分析和性能评估。然而,人工编码存在资源消耗大、主观偏差以及一致性难以保证等问题。现有方法难以在效率和准确性之间取得平衡。
核心思路:本文的核心思路是将大型语言模型(LLM)应用于城市系统管理文档的定性编码任务。通过设计合适的提示策略,引导LLM理解文档内容并进行分类。特别地,论文提出了文本分块(Text Chunking)的方法,将长文档分割成较小的文本块,分别进行分析,以减少上下文聚合偏差。
技术框架:整体流程包括以下几个步骤:1) 收集城市系统管理相关的文档;2) 将文档分割成文本块;3) 使用不同的LLM(GPT-4o, GPT-4o-mini, o1-mini)和提示策略(全文分析和文本分块分析)对文本块进行编码;4) 将LLM的编码结果与人工编码结果进行比较,评估LLM的性能。
关键创新:论文的关键创新在于提出了基于文本分块的提示方法,用于解决LLM在处理长文本时可能出现的上下文聚合偏差问题。通过将长文本分割成小块,可以更好地保留局部上下文信息,提高LLM的编码准确性。
关键设计:论文使用了两种提示方法:全文分析和文本分块分析。在文本分块分析中,文档被分割成多个文本块,每个文本块单独输入到LLM中进行编码。论文比较了不同LLM(GPT-4o, GPT-4o-mini, o1-mini)在两种提示方法下的性能,并与人工编码结果进行了对比。评估指标包括准确率、一致性等。
🖼️ 关键图片
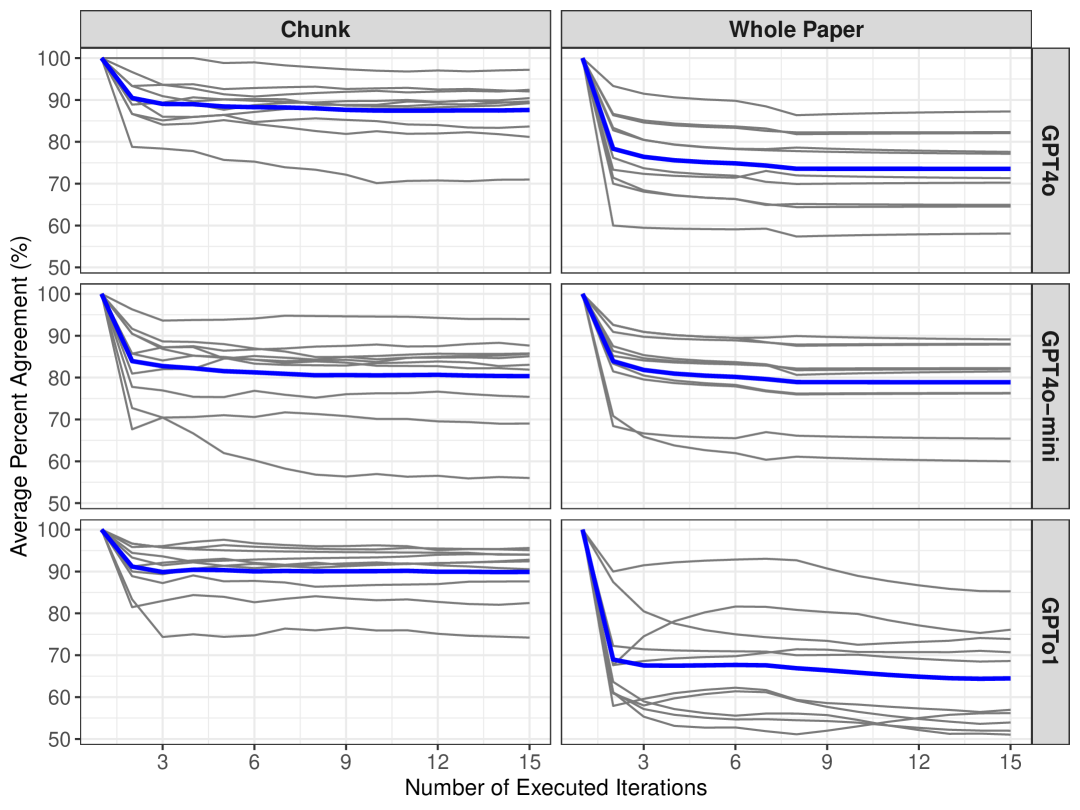
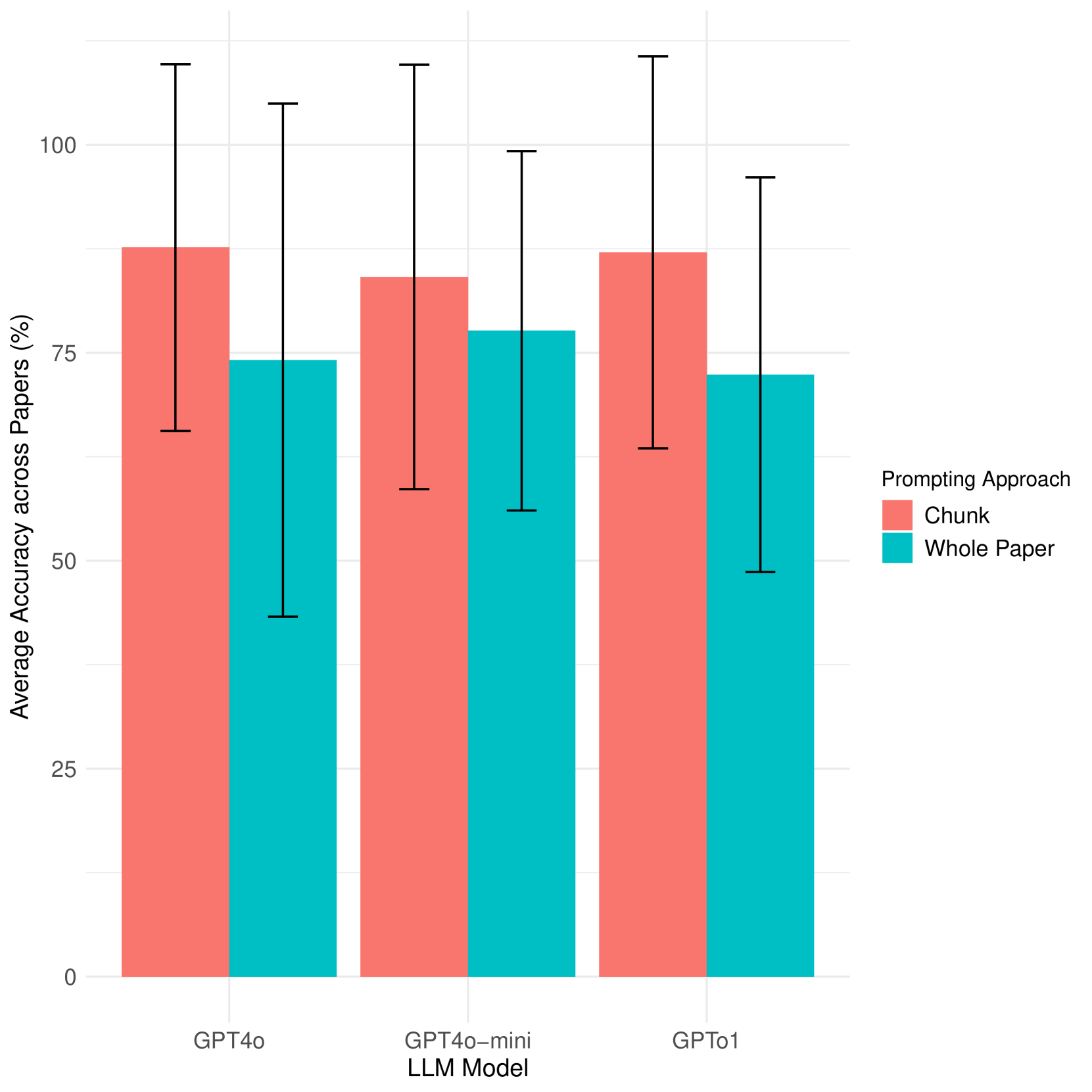
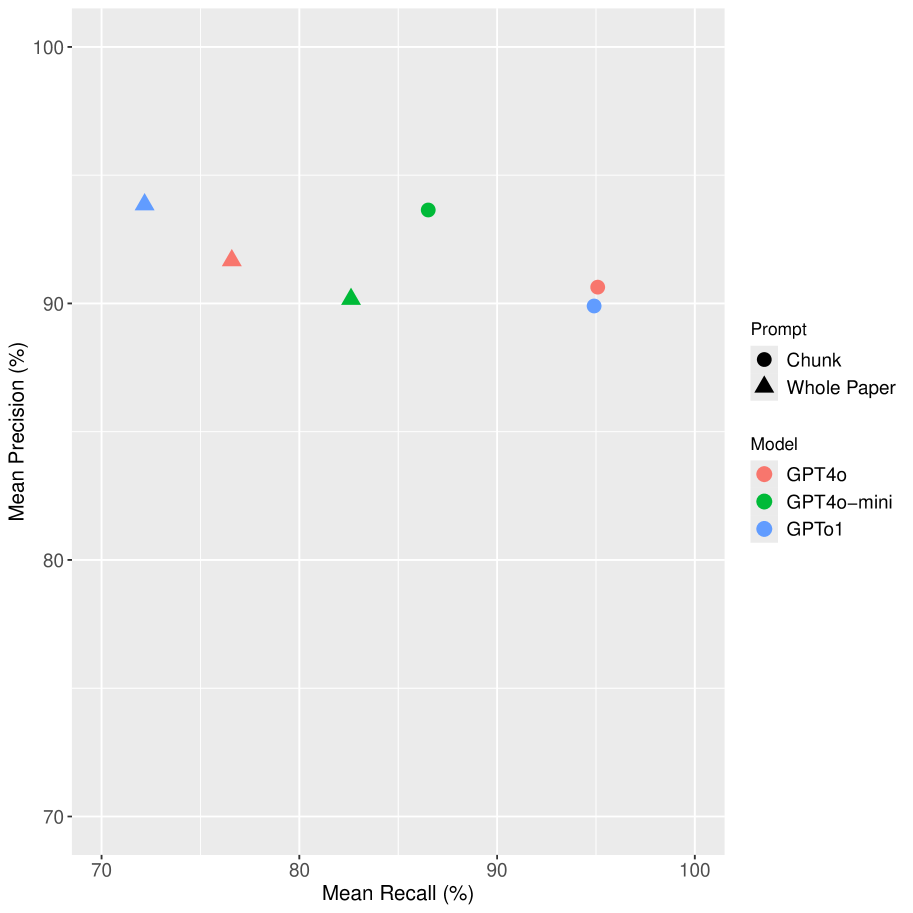
📊 实验亮点
实验结果表明,使用文本分块方法时,GPT-4o、o1-mini和GPT-4o-mini与人类评估者表现出显著的一致性。将GPT-4o和GPT-4o-mini作为额外的评估者与三个人工评估者一起使用时,所有评估者之间都表现出统计学上的显著一致性,表明LLM可以有效辅助文本分析任务。
🎯 应用场景
该研究成果可应用于智慧城市建设、城市规划、政策制定等领域。通过利用LLM自动分析城市管理相关文档,可以提高决策效率,减少人工成本,并为城市管理者提供更全面、客观的信息支持。未来,该方法有望推广到其他需要处理大量文本数据的领域。
📄 摘要(原文)
Urban systems are managed using complex textual documentation that need coding and analysis to set requirements and evaluate built environment performance. This paper contributes to the study of applying large-language models (LLM) to qualitative coding activities to reduce resource requirements while maintaining comparable reliability to humans. Qualitative coding and assessment face challenges like resource limitations and bias, accuracy, and consistency between human evaluators. Here we report the application of LLMs to deductively code 10 case documents on the presence of 17 digital twin characteristics for the management of urban systems. We utilize two prompting methods to compare the semantic processing of LLMs with human coding efforts: whole text analysis and text chunk analysis using OpenAI's GPT-4o, GPT-4o-mini, and o1-mini models. We found similar trends of internal variability between methods and results indicate that LLMs may perform on par with human coders when initialized with specific deductive coding contexts. GPT-4o, o1-mini and GPT-4o-mini showed significant agreement with human raters when employed using a chunking method. The application of both GPT-4o and GPT-4o-mini as an additional rater with three manual raters showed statistically significant agreement across all raters, indicating that the analysis of textual documents is benefited by LLMs. Our findings reveal nuanced sub-themes of LLM application suggesting LLMs follow human memory coding processes where whole-text analysis may introduce multiple meanings. The novel contributions of this paper lie in assessing the performance of OpenAI GPT models and introduces the chunk-based prompting approach, which addresses context aggregation biases by preserving localized context.