Contradiction Detection in RAG Systems: Evaluating LLMs as Context Validators for Improved Information Consistency
作者: Vignesh Gokul, Srikanth Tenneti, Alwarappan Nakkiran
分类: cs.CL, cs.AI
发布日期: 2025-03-31
💡 一句话要点
提出RAG系统矛盾检测框架,评估LLM作为上下文验证器的信息一致性能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RAG系统 矛盾检测 上下文验证 大型语言模型 信息一致性
📋 核心要点
- RAG系统易受检索到的矛盾信息影响,导致LLM生成不一致的输出,尤其是在信息快速变化的领域。
- 论文提出了一种新的数据生成框架,用于模拟RAG系统中可能出现的各种矛盾类型,从而为评估LLM的上下文验证能力提供基础。
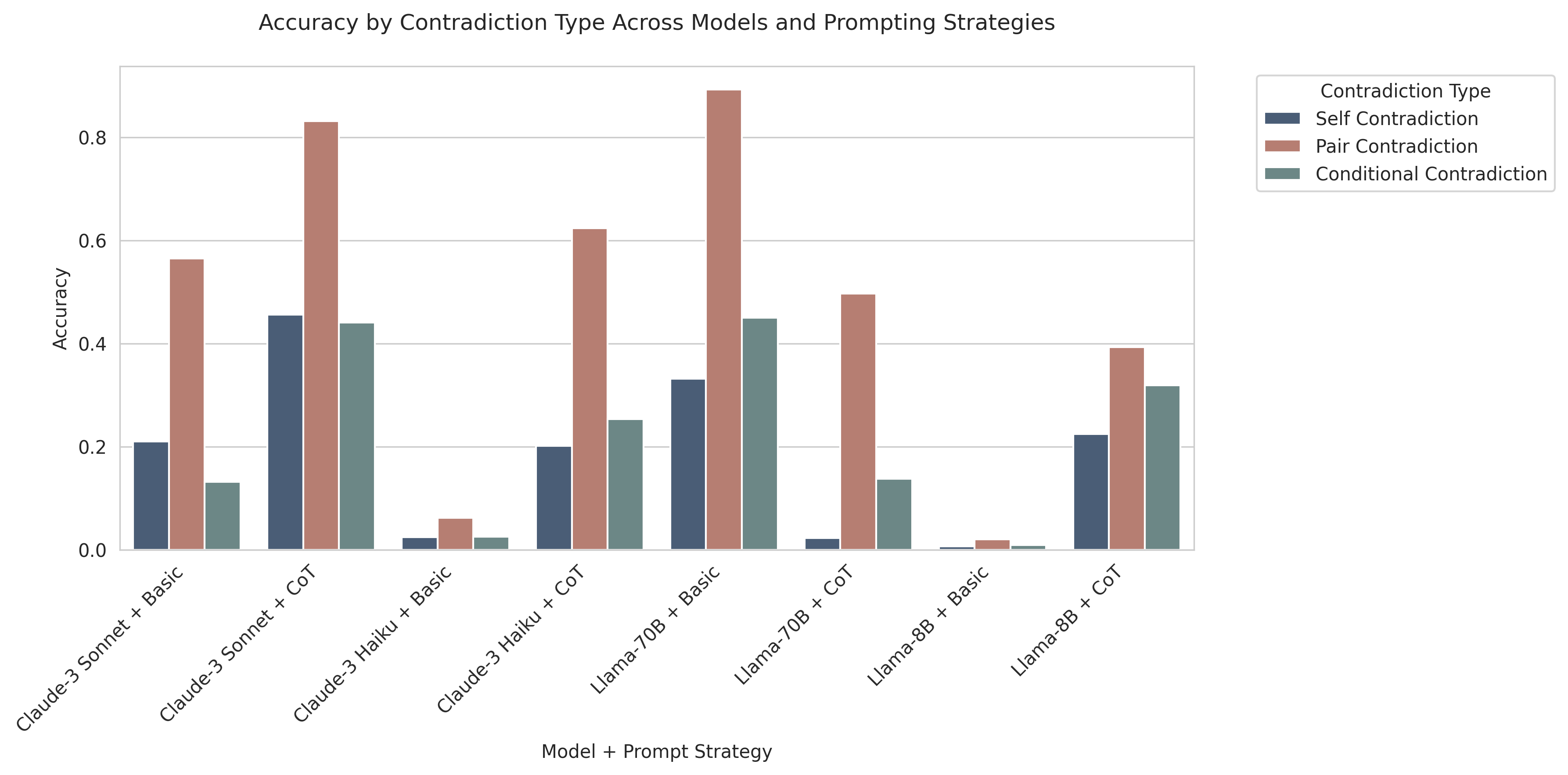
- 实验结果表明,即使是最先进的LLM在上下文验证方面仍然面临挑战,且不同提示策略对模型性能的影响存在差异。
📝 摘要(中文)
检索增强生成(RAG)系统已成为利用最新信息增强大型语言模型(LLM)的有效方法。然而,RAG中的检索步骤有时会检索到包含矛盾信息的文件,尤其是在新闻等快速发展的领域。这些矛盾会显著影响LLM的性能,导致不一致或错误的输出。本研究通过两种方式解决这一关键挑战。首先,我们提出了一个新颖的数据生成框架,用于模拟RAG系统检索阶段可能出现的不同类型的矛盾。其次,我们评估了不同LLM作为上下文验证器的鲁棒性,评估它们检测检索文档集中矛盾信息的能力。实验结果表明,即使对于最先进的LLM来说,上下文验证仍然是一项具有挑战性的任务,并且性能因不同类型的矛盾而异。虽然较大的模型通常在矛盾检测方面表现更好,但不同提示策略的有效性因任务和模型架构而异。我们发现,思维链提示在某些模型上显示出显著的改进,但在其他模型上可能会阻碍性能,突出了该任务的复杂性以及对RAG系统中更强大的上下文验证方法的需求。
🔬 方法详解
问题定义:RAG系统在检索阶段可能引入包含矛盾信息的文件,导致LLM生成不一致或错误的答案。现有方法缺乏有效检测和处理这些矛盾信息的能力,从而影响了RAG系统的可靠性。
核心思路:将LLM作为上下文验证器,评估其检测检索到的文档集中矛盾信息的能力。通过构建包含不同类型矛盾的数据集,并设计不同的提示策略,来考察LLM在矛盾检测任务中的表现。核心在于模拟真实场景下的矛盾,并分析LLM在不同情况下的鲁棒性。
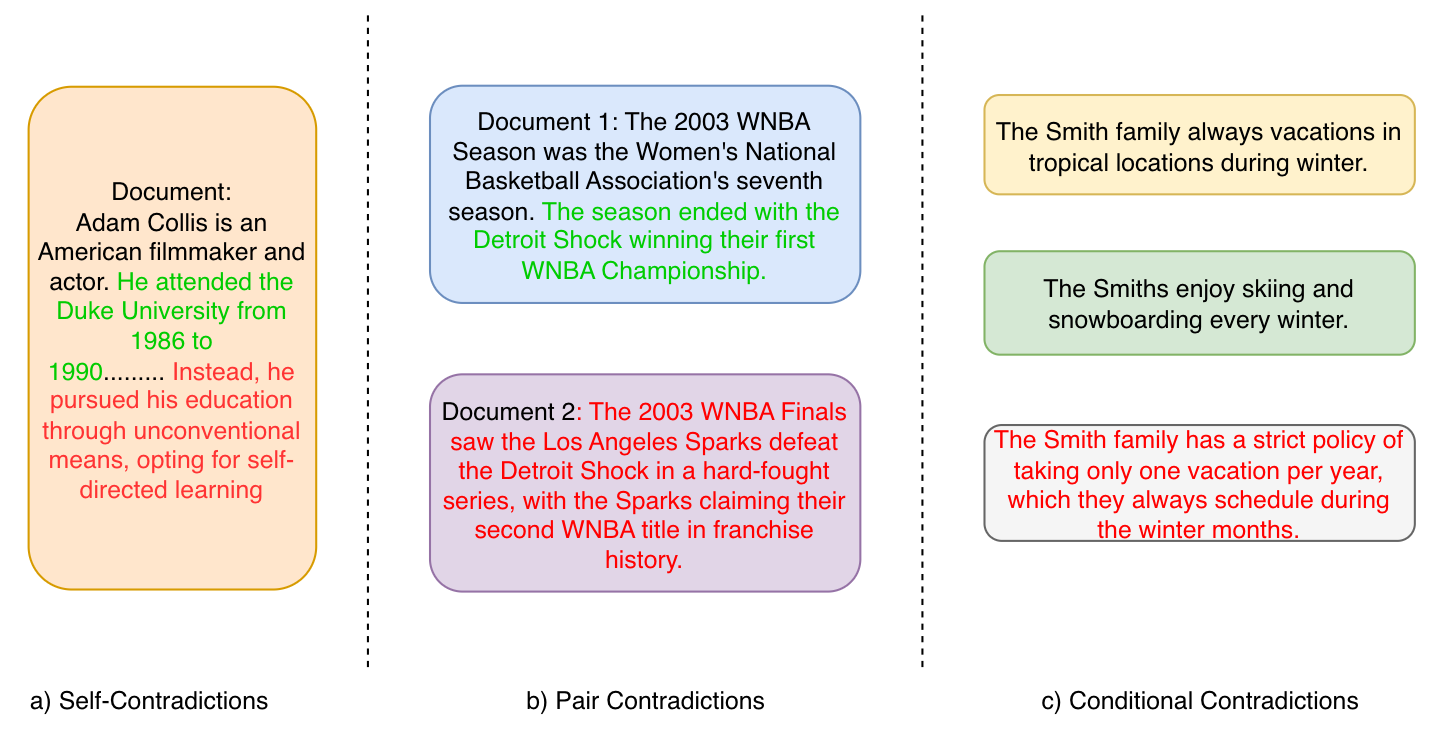
技术框架:该研究主要包含两个阶段:1) 数据生成阶段:构建一个数据生成框架,用于模拟RAG系统中可能出现的不同类型的矛盾。这些矛盾包括事实性矛盾、观点性矛盾等。2) 模型评估阶段:使用生成的数据集,评估不同LLM作为上下文验证器的性能。通过不同的提示策略(如思维链提示)来考察LLM的矛盾检测能力。
关键创新:提出了一个新颖的数据生成框架,能够模拟RAG系统中可能出现的各种类型的矛盾。该框架可以用于生成大规模的矛盾检测数据集,为评估LLM的上下文验证能力提供基础。此外,该研究还系统地评估了不同LLM在矛盾检测任务中的表现,并分析了不同提示策略对模型性能的影响。
关键设计:数据生成框架的设计需要考虑不同类型的矛盾,例如事实性矛盾、观点性矛盾等。提示策略的设计需要考虑如何引导LLM进行推理和判断,例如使用思维链提示来帮助LLM逐步分析和比较不同信息源。评估指标的选择需要能够准确反映LLM的矛盾检测能力,例如使用准确率、召回率等指标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是最先进的LLM在上下文验证方面仍然面临挑战,性能因不同类型的矛盾而异。较大的模型通常表现更好,但不同提示策略的有效性也存在差异。思维链提示在某些模型上有所改进,但在其他模型上可能会降低性能。例如,某些模型在特定类型的矛盾检测任务中,准确率提升了5%-10%。
🎯 应用场景
该研究成果可应用于提升RAG系统的可靠性和准确性,尤其是在新闻、金融等对信息一致性要求较高的领域。通过集成上下文验证模块,可以有效过滤掉包含矛盾信息的文件,从而提高LLM生成答案的质量。此外,该研究还可以为LLM的上下文理解和推理能力提供新的研究方向。
📄 摘要(原文)
Retrieval Augmented Generation (RAG) systems have emerged as a powerful method for enhancing large language models (LLMs) with up-to-date information. However, the retrieval step in RAG can sometimes surface documents containing contradictory information, particularly in rapidly evolving domains such as news. These contradictions can significantly impact the performance of LLMs, leading to inconsistent or erroneous outputs. This study addresses this critical challenge in two ways. First, we present a novel data generation framework to simulate different types of contradictions that may occur in the retrieval stage of a RAG system. Second, we evaluate the robustness of different LLMs in performing as context validators, assessing their ability to detect contradictory information within retrieved document sets. Our experimental results reveal that context validation remains a challenging task even for state-of-the-art LLMs, with performance varying significantly across different types of contradictions. While larger models generally perform better at contradiction detection, the effectiveness of different prompting strategies varies across tasks and model architectures. We find that chain-of-thought prompting shows notable improvements for some models but may hinder performance in others, highlighting the complexity of the task and the need for more robust approaches to context validation in RAG systems.