JudgeLRM: Large Reasoning Models as a Judge
作者: Nuo Chen, Zhiyuan Hu, Qingyun Zou, Jiaying Wu, Qian Wang, Bryan Hooi, Bingsheng He
分类: cs.CL, cs.AI
发布日期: 2025-03-31 (更新: 2025-11-03)
备注: Preprint
💡 一句话要点
提出JudgeLRM,利用强化学习训练面向判断任务的大型推理模型,显著提升推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 判断任务 推理能力 自动化评估
📋 核心要点
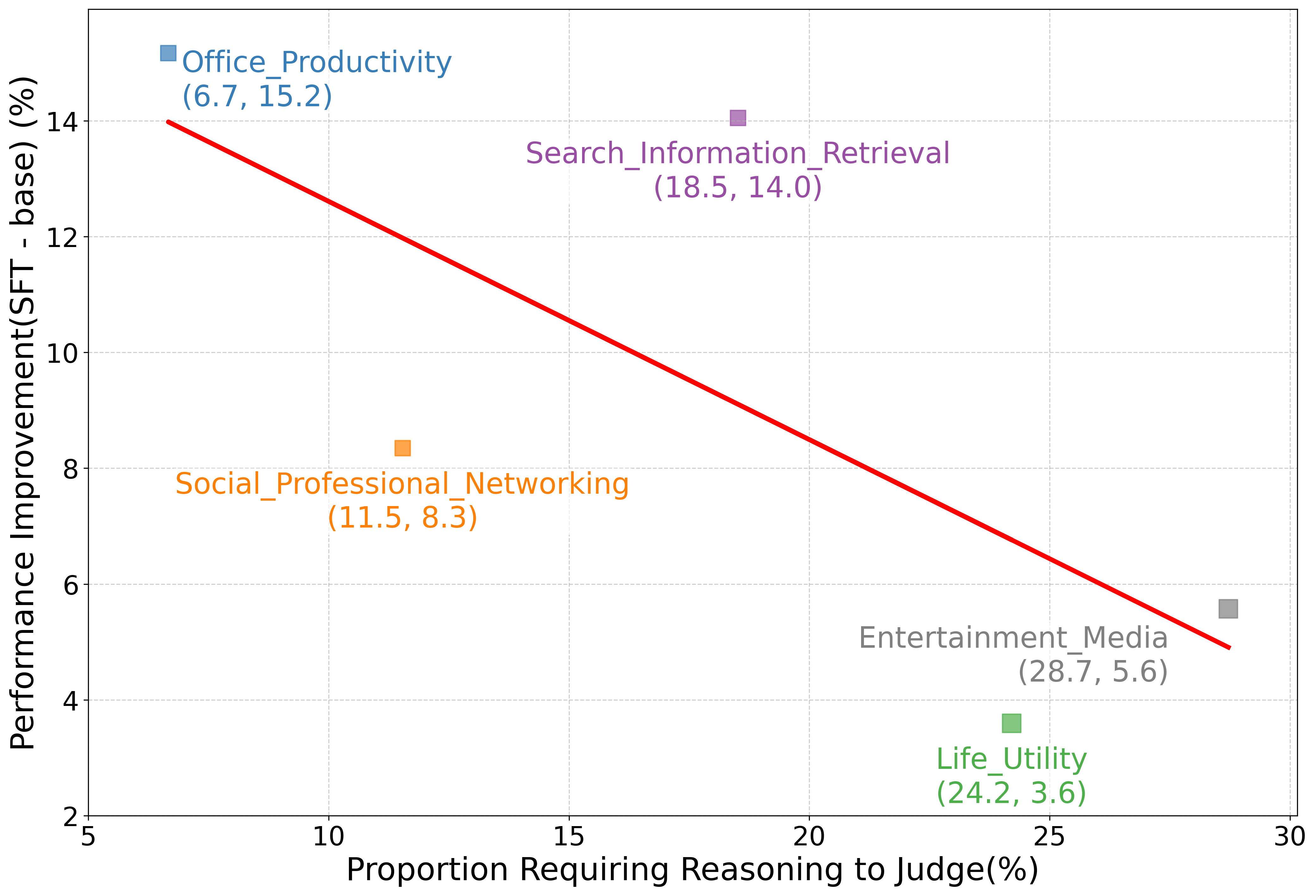
- 现有监督微调(SFT)方法在复杂推理的判断任务中存在局限性,无法充分利用LLM的推理能力。
- 提出JudgeLRM,利用强化学习和judge-wise、结果驱动的奖励机制,激活LLM的推理能力。
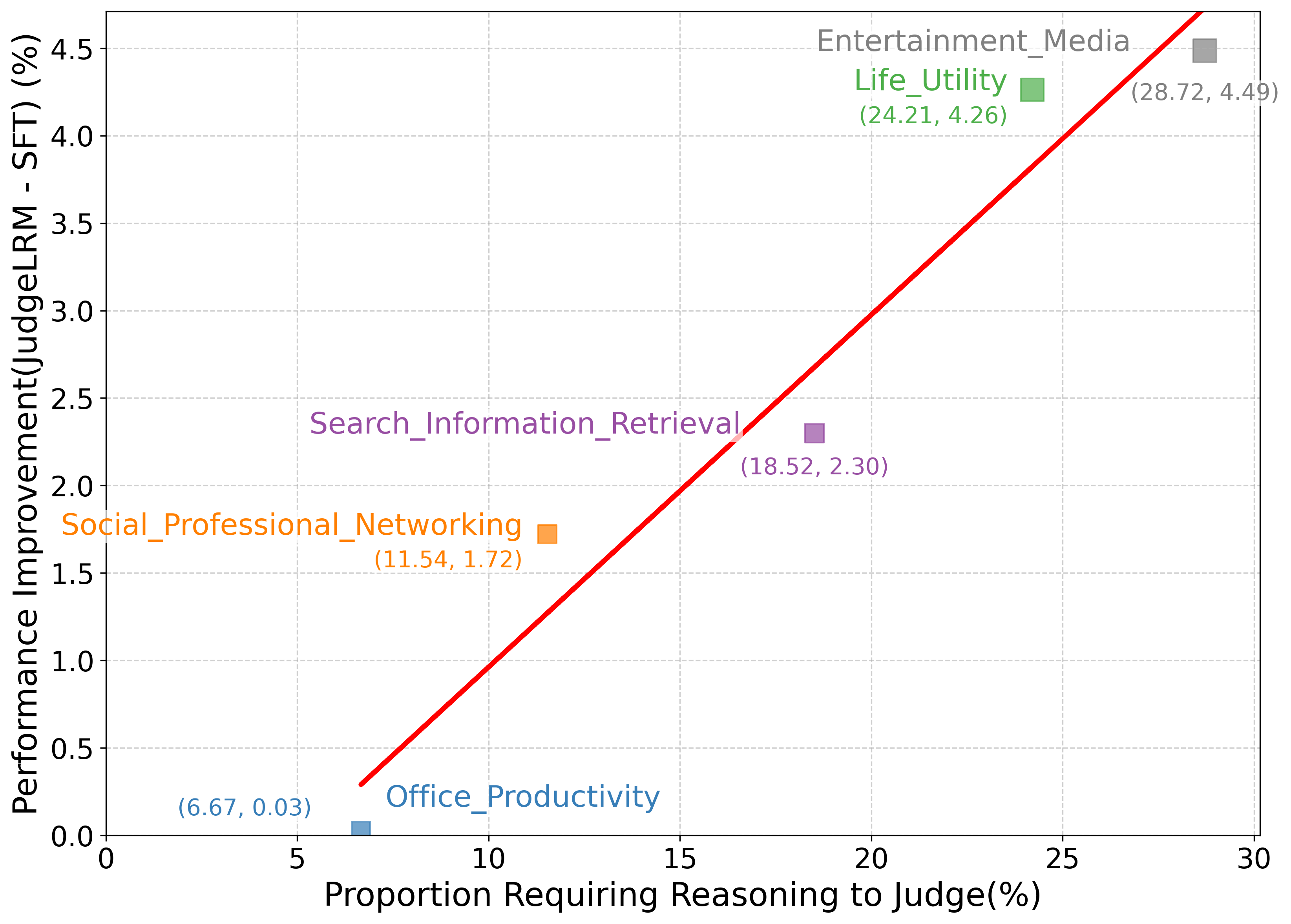
- 实验表明,JudgeLRM在多个规模上均优于SFT基线和其他RL变体,甚至超越了GPT-4和DeepSeek-R1等先进模型。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用作评估器,为人工标注提供了一种可扩展的替代方案。然而,现有的监督微调(SFT)方法在需要复杂推理的领域常常表现不佳。判断本质上是推理密集型的:除了表面上的评分之外,它还需要验证证据、识别错误和证明决策的合理性。通过对评估任务的分析,我们发现SFT性能提升与推理需求样本比例之间存在负相关,揭示了SFT在此类场景中的局限性。为了解决这个问题,我们引入了JudgeLRM,一系列面向判断的LLM,使用强化学习(RL)进行训练,并采用judge-wise、结果驱动的奖励来激活推理能力。JudgeLRM始终优于相同规模的SFT微调基线以及其他RL和SFT变体,甚至超过了最先进的推理模型:值得注意的是,JudgeLRM-3B/4B超过了GPT-4,而JudgeLRM-7B/8B/14B在F1得分上超过DeepSeek-R1超过2%,在推理繁重的任务上尤其表现出色。我们的研究结果强调了RL在解锁与推理对齐的LLM judge方面的价值。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在作为评估器时,尤其是在需要复杂推理的判断任务中,监督微调方法表现不佳的问题。现有SFT方法难以有效利用LLM的推理能力,导致在推理密集型任务中性能提升有限。
核心思路:论文的核心思路是利用强化学习(RL)来训练LLM,使其更好地执行判断任务。通过设计judge-wise、结果驱动的奖励函数,引导模型学习如何进行有效的推理,从而做出更准确的判断。这种方法旨在克服SFT的局限性,充分挖掘LLM的推理潜力。
技术框架:JudgeLRM的训练框架主要包括以下几个阶段:1) 使用预训练的LLM作为基础模型;2) 构建包含判断任务的数据集,并定义相应的奖励函数;3) 使用强化学习算法(具体算法未知)对LLM进行微调,目标是最大化累积奖励;4) 对训练后的模型进行评估,验证其在判断任务上的性能。
关键创新:论文的关键创新在于使用强化学习来训练LLM作为judge,并设计了judge-wise、结果驱动的奖励函数。这种方法与传统的SFT方法不同,它更加注重引导模型学习推理过程,而不仅仅是拟合训练数据。通过强化学习,模型可以更好地理解判断任务的本质,并做出更合理的决策。
关键设计:关于关键设计,论文提到judge-wise、结果驱动的奖励。具体如何设计奖励函数,如何根据不同的判断任务调整奖励策略,以及强化学习算法的具体选择(例如,PPO、DQN等)等细节未知。这些细节对于复现和进一步研究至关重要。
🖼️ 关键图片
📊 实验亮点
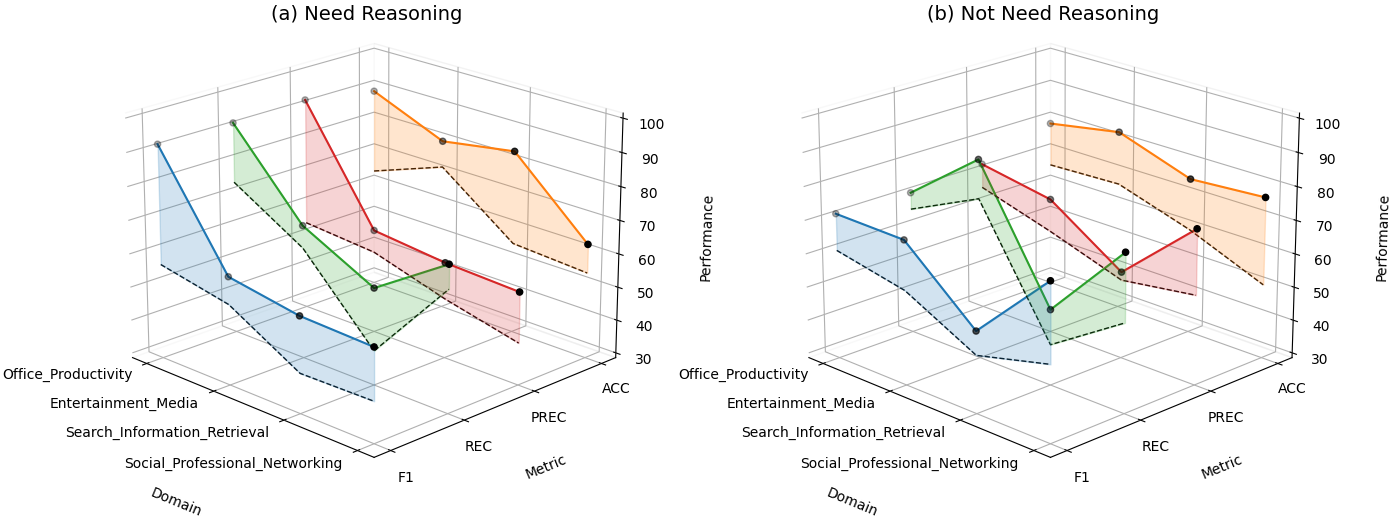
JudgeLRM在多个规模上均取得了显著的性能提升。JudgeLRM-3B/4B超过了GPT-4,而JudgeLRM-7B/8B/14B在F1得分上超过DeepSeek-R1超过2%,尤其在推理繁重的任务上表现出色。这些结果表明,基于强化学习的JudgeLRM能够有效提升LLM在判断任务中的推理能力。
🎯 应用场景
JudgeLRM可应用于各种需要自动化评估和判断的场景,例如自动代码评审、论文评审、对话系统评估、机器翻译质量评估等。该研究有助于提高自动化评估的准确性和效率,降低人工成本,并推动人工智能在更多领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly adopted as evaluators, offering a scalable alternative to human annotation. However, existing supervised fine-tuning (SFT) approaches often fall short in domains that demand complex reasoning. Judgment is inherently reasoning-intensive: beyond surface-level scoring, it requires verifying evidence, identifying errors, and justifying decisions. Through the analysis of evaluation tasks, we find a negative correlation between SFT performance gains and the proportion of reasoning-demanding samples, revealing the limits of SFT in such scenarios. To address this, we introduce JudgeLRM, a family of judgment-oriented LLMs, trained using reinforcement learning (RL) with judge-wise, outcome-driven rewards to activate reasoning capabilities. JudgeLRM consistently outperform SFT-tuned baselines in the same size, as well as other RL and SFT variants, and even surpass state-of-the-art reasoning models: notably, JudgeLRM-3B/4B exceeds GPT-4, while JudgeLRM-7B/8B/14B outperforms DeepSeek-R1 by over 2% in F1 score, with particularly strong gains on reasoning-heavy tasks. Our findings underscore the value of RL in unlocking reasoning-aligned LLM judges.