A Systematic Evaluation of LLM Strategies for Mental Health Text Analysis: Fine-tuning vs. Prompt Engineering vs. RAG
作者: Arshia Kermani, Veronica Perez-Rosas, Vangelis Metsis
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2025-03-31
💡 一句话要点
系统评估LLM在心理健康文本分析中的策略:微调、提示工程与RAG
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 心理健康 文本分析 微调 提示工程 检索增强生成 情感分类
📋 核心要点
- 现有心理健康文本分析方法在准确性和资源消耗上存在挑战,难以兼顾高性能与低成本。
- 论文对比微调、提示工程和RAG三种策略,探索LLM在心理健康文本分析中的最佳实践。
- 实验表明,微调精度最高但资源需求大,提示工程和RAG更灵活但精度稍逊,为实际应用提供参考。
📝 摘要(中文)
本研究系统地比较了三种使用大型语言模型(LLM)分析心理健康文本的方法:提示工程、检索增强生成(RAG)和微调。我们使用LLaMA 3,在两个数据集上评估了这些方法在情感分类和心理健康状况检测任务中的表现。微调实现了最高的准确率(情感分类为91%,心理健康状况检测为80%),但需要大量的计算资源和大型训练集,而提示工程和RAG提供了更灵活的部署,但性能适中(准确率在40-68%之间)。我们的研究结果为在心理健康应用中实施基于LLM的解决方案提供了实用的见解,突出了准确性、计算需求和部署灵活性之间的权衡。
🔬 方法详解
问题定义:论文旨在解决心理健康文本分析中的情感分类和心理健康状况检测问题。现有方法可能面临准确率不足、计算资源需求高或部署灵活性差等痛点,难以满足实际应用的需求。
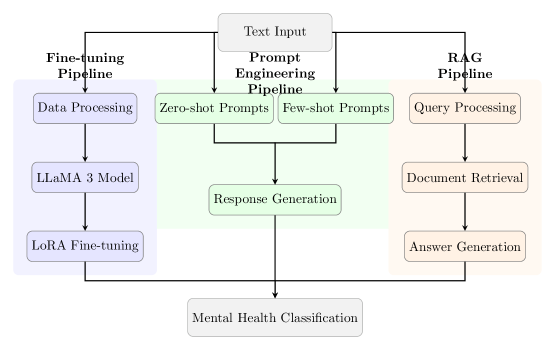
核心思路:论文的核心思路是系统性地比较三种不同的LLM应用策略:微调、提示工程和检索增强生成(RAG),以确定在心理健康文本分析任务中,哪种策略能够在准确率、计算资源和部署灵活性之间取得最佳平衡。
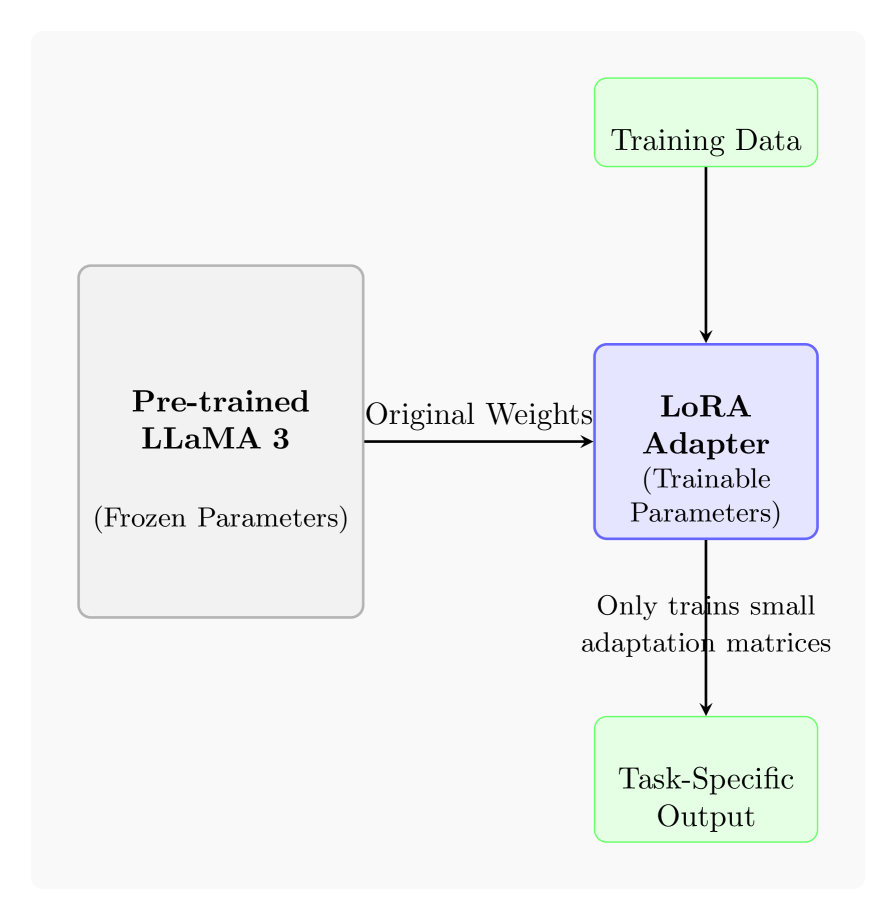
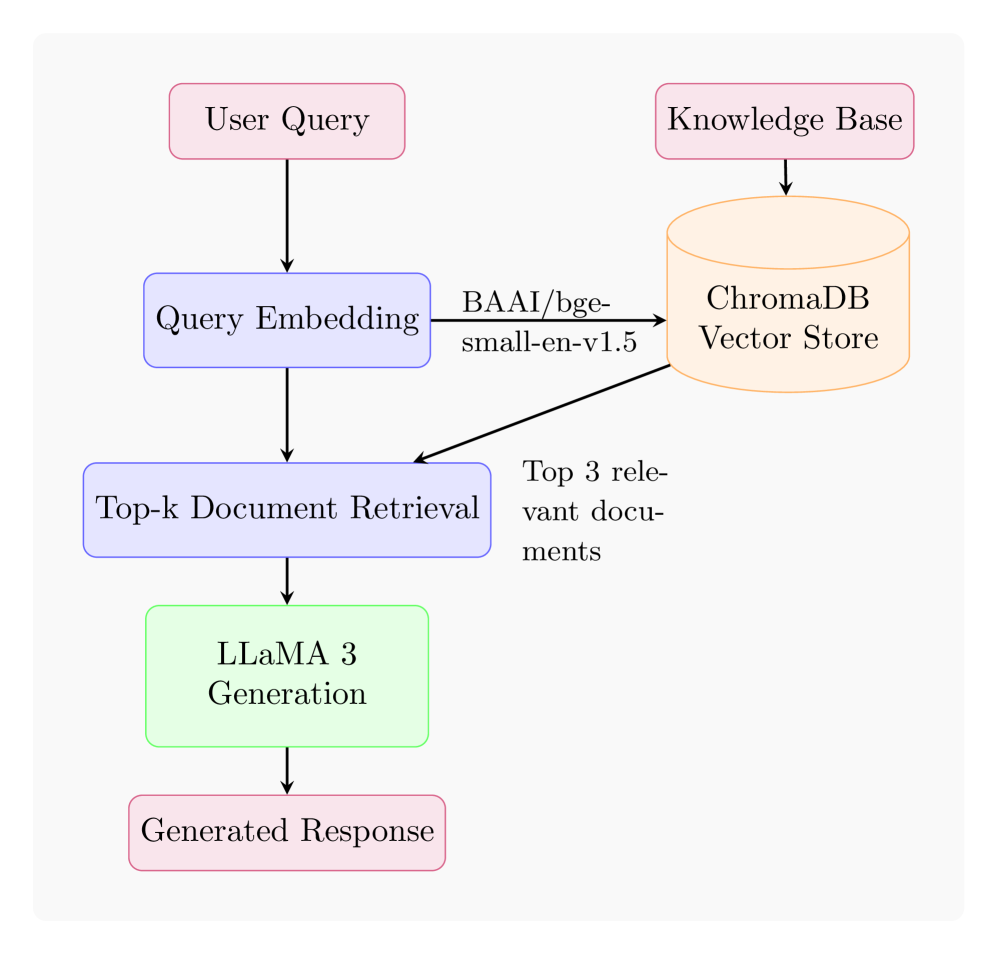
技术框架:整体框架包括数据准备、模型选择(LLaMA 3)、三种策略的实现和评估。数据准备涉及两个心理健康相关的文本数据集。三种策略分别实现:微调通过在特定数据集上训练LLM来优化性能;提示工程通过设计合适的提示词来引导LLM完成任务;RAG则结合外部知识库检索相关信息,并将其融入LLM的生成过程中。最后,使用标准指标(如准确率)评估三种策略的性能。
关键创新:论文的关键创新在于对三种主流LLM应用策略进行了系统性的对比评估,并针对心理健康文本分析这一特定领域,提供了实用的指导。以往的研究可能侧重于单一策略的优化,而本研究则关注不同策略之间的权衡,为实际应用提供了更全面的视角。
关键设计:论文的关键设计包括:1) 选择LLaMA 3作为基础模型;2) 针对情感分类和心理健康状况检测任务,设计合适的提示词;3) 构建或选择合适的外部知识库,用于RAG策略;4) 针对微调策略,选择合适的训练参数和损失函数。具体的参数设置和网络结构等细节可能在论文正文中详细描述,摘要中未提及。
🖼️ 关键图片
📊 实验亮点
实验结果表明,微调LLaMA 3在情感分类任务中达到了91%的准确率,在心理健康状况检测任务中达到了80%的准确率,优于提示工程和RAG方法。然而,提示工程和RAG在资源消耗和部署灵活性方面更具优势,准确率分别在40-68%之间。这些结果为实际应用中选择合适的LLM策略提供了重要参考。
🎯 应用场景
该研究成果可应用于心理健康监测、在线咨询、心理健康教育等领域。通过自动分析用户文本,可以辅助识别潜在的心理健康问题,提供个性化的支持和干预,从而提高心理健康服务的效率和覆盖范围。未来的研究可以进一步探索更复杂的心理健康文本分析任务,例如风险评估和治疗效果预测。
📄 摘要(原文)
This study presents a systematic comparison of three approaches for the analysis of mental health text using large language models (LLMs): prompt engineering, retrieval augmented generation (RAG), and fine-tuning. Using LLaMA 3, we evaluate these approaches on emotion classification and mental health condition detection tasks across two datasets. Fine-tuning achieves the highest accuracy (91% for emotion classification, 80% for mental health conditions) but requires substantial computational resources and large training sets, while prompt engineering and RAG offer more flexible deployment with moderate performance (40-68% accuracy). Our findings provide practical insights for implementing LLM-based solutions in mental health applications, highlighting the trade-offs between accuracy, computational requirements, and deployment flexibility.