Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning
作者: Jiacheng Lin, Tian Wang, Kun Qian
分类: cs.IR, cs.CL
发布日期: 2025-03-31 (更新: 2025-10-15)
备注: Published in the TMLR journal
💡 一句话要点
提出Rec-R1,通过强化学习桥接生成式大语言模型与用户中心推荐系统。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 推荐系统 闭环优化 产品搜索 序列推荐 用户中心 策略梯度
📋 核心要点
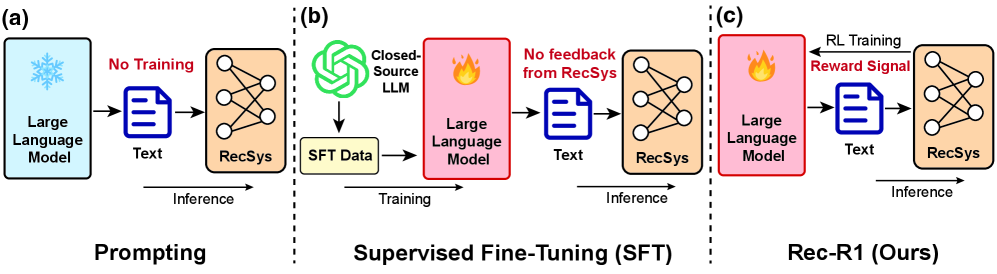
- 现有方法依赖提示工程或监督微调,需要大量成本进行数据提炼,且微调可能损害LLM的通用能力。
- Rec-R1利用强化学习,通过黑盒推荐模型的反馈直接优化LLM生成,无需合成数据,降低成本并保留LLM能力。
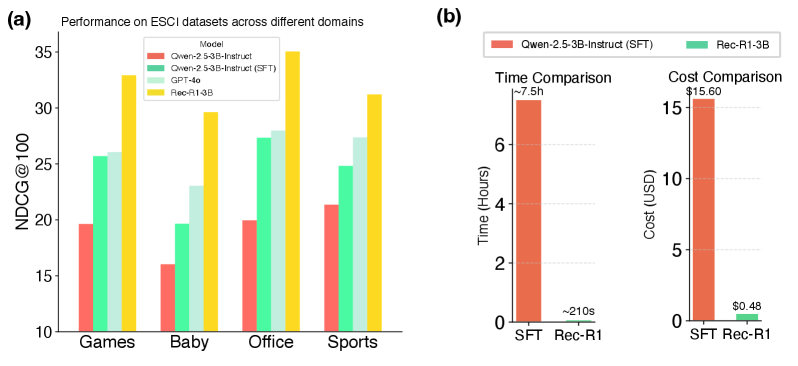
- 实验表明,Rec-R1在产品搜索和序列推荐任务上优于提示工程和监督微调,且超越了判别式基线模型。
📝 摘要(中文)
本文提出Rec-R1,一个通用的强化学习框架,通过闭环优化将大语言模型(LLM)与推荐系统连接起来。与提示工程和监督微调(SFT)不同,Rec-R1直接利用来自固定黑盒推荐模型的反馈来优化LLM的生成,而无需依赖来自GPT-4o等专有模型的合成SFT数据。这避免了数据提炼所需的大量成本和精力。为了验证Rec-R1的有效性,我们在两个代表性任务上对其进行评估:产品搜索和序列推荐。实验结果表明,Rec-R1不仅始终优于基于提示和SFT的方法,而且即使与BM25等简单检索器一起使用,也能获得优于强判别基线的显著收益。此外,Rec-R1保留了LLM的通用能力,而SFT通常会损害指令跟随和推理能力。这些发现表明,Rec-R1是持续的、特定于任务的自适应而不会发生灾难性遗忘的有希望的基础。
🔬 方法详解
问题定义:现有方法,如提示工程和监督微调(SFT),在将大语言模型应用于推荐系统时存在局限性。提示工程依赖于人工设计的提示,难以充分利用LLM的生成能力。SFT需要大量标注数据,特别是高质量的合成数据,而获取这些数据通常需要依赖专有模型,成本高昂,且SFT可能导致LLM的通用能力下降,出现灾难性遗忘。因此,如何以更高效、更通用的方式将LLM应用于推荐系统是一个挑战。
核心思路:Rec-R1的核心思路是通过强化学习,直接利用推荐系统的反馈信号来优化LLM的生成过程。将LLM视为一个策略网络,其输出(例如,搜索查询或推荐理由)作为动作,而推荐系统的性能(例如,点击率、转化率)作为奖励。通过强化学习,LLM可以学习生成更符合用户需求的输出,从而提高推荐系统的性能。这种方法避免了对大量标注数据的依赖,并且能够保留LLM的通用能力。
技术框架:Rec-R1的整体框架包含以下几个主要模块:1) LLM:作为策略网络,负责生成动作(例如,搜索查询或推荐理由)。2) 推荐系统:作为一个黑盒环境,接收LLM生成的动作,并返回相应的奖励(例如,点击率、转化率)。3) 强化学习算法:负责根据推荐系统的反馈信号,更新LLM的参数,使其能够生成更符合用户需求的动作。Rec-R1可以使用各种强化学习算法,例如,策略梯度算法或Q-learning算法。
关键创新:Rec-R1的关键创新在于它将LLM和推荐系统通过强化学习连接起来,形成一个闭环优化系统。与传统的提示工程和SFT方法相比,Rec-R1能够更有效地利用推荐系统的反馈信号,从而提高推荐系统的性能。此外,Rec-R1避免了对大量标注数据的依赖,并且能够保留LLM的通用能力。
关键设计:Rec-R1的关键设计包括:1) 奖励函数的设计:奖励函数需要能够准确地反映推荐系统的性能。例如,可以使用点击率、转化率或用户满意度等指标作为奖励。2) 强化学习算法的选择:需要选择合适的强化学习算法,以便能够有效地更新LLM的参数。3) LLM的架构:可以使用各种LLM架构,例如,Transformer或RNN。4) 探索与利用的平衡:在强化学习过程中,需要在探索新的动作和利用已知的有效动作之间进行平衡。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Rec-R1在产品搜索和序列推荐任务上均优于基于提示和SFT的方法。即使与简单的BM25检索器结合使用,Rec-R1也能显著超越强大的判别式基线模型。此外,Rec-R1能够保留LLM的通用能力,避免了SFT可能导致的指令跟随和推理能力下降。具体性能提升数据未知。
🎯 应用场景
Rec-R1具有广泛的应用前景,可应用于电商产品搜索、个性化推荐、智能客服等领域。通过优化LLM的生成能力,可以提高搜索结果的相关性、推荐的准确性和用户交互的自然性。该研究有助于构建更智能、更用户友好的推荐系统,提升用户体验和商业价值。未来,Rec-R1有望应用于更复杂的推荐场景,例如多模态推荐、社交推荐等。
📄 摘要(原文)
We propose Rec-R1, a general reinforcement learning framework that bridges large language models (LLMs) with recommendation systems through closed-loop optimization. Unlike prompting and supervised fine-tuning (SFT), Rec-R1 directly optimizes LLM generation using feedback from a fixed black-box recommendation model, without relying on synthetic SFT data from proprietary models such as GPT-4o. This avoids the substantial cost and effort required for data distillation. To verify the effectiveness of Rec-R1, we evaluate it on two representative tasks: product search and sequential recommendation. Experimental results demonstrate that Rec-R1 not only consistently outperforms prompting- and SFT-based methods, but also achieves significant gains over strong discriminative baselines, even when used with simple retrievers such as BM25. Moreover, Rec-R1 preserves the general-purpose capabilities of the LLM, unlike SFT, which often impairs instruction-following and reasoning. These findings suggest Rec-R1 as a promising foundation for continual task-specific adaptation without catastrophic forgetting.