TwT: Thinking without Tokens by Habitual Reasoning Distillation with Multi-Teachers' Guidance
作者: Jingxian Xu, Mengyu Zhou, Weichang Liu, Hanbing Liu, Shi Han, Dongmei Zhang
分类: cs.CL
发布日期: 2025-03-31 (更新: 2025-11-04)
💡 一句话要点
TwT:通过习惯性推理蒸馏和多教师指导,实现无Token的LLM推理加速
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识蒸馏 推理加速 习惯性推理 无Token推理
📋 核心要点
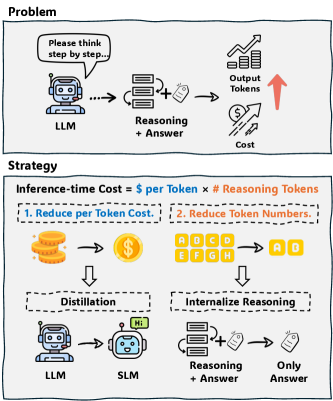
- 现有LLM推理计算成本高昂,原因是增强的推理能力导致输出token数量增加,需要寻找降低token数量的方法。
- TwT通过习惯性推理蒸馏,将显式推理过程内化到模型的习惯行为中,从而减少推理时所需的token数量。
- 实验表明,TwT在减少推理成本的同时,保持了卓越的性能,准确率提升高达13.6%,为高效LLM部署提供实用方案。
📝 摘要(中文)
大型语言模型(LLMs)通过结合推理过程在解决问题方面取得了显著进展。然而,这种增强的推理能力导致推理过程中输出token数量增加,从而导致更高的计算成本。为了解决这个挑战,我们提出了TwT(Thinking without Tokens),这是一种通过习惯性推理蒸馏和多教师指导来减少推理时成本的方法,同时保持高性能。我们的方法引入了一种习惯性推理蒸馏方法,通过受人类认知启发的教师指导压缩策略,将显式推理内化到模型的习惯行为中。此外,我们提出了一种双重标准拒绝采样(DCRS)技术,该技术使用多个教师模型生成高质量和多样化的蒸馏数据集,使我们的方法适用于无监督场景。实验结果表明,TwT有效地降低了推理成本,同时保持了卓越的性能,与其他蒸馏方法相比,在更少的输出token的情况下,准确率提高了高达13.6%,为高效的LLM部署提供了一个非常实用的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)推理过程中计算成本高的问题。现有方法,如直接使用LLM进行推理,会产生大量的输出token,导致计算资源消耗大、延迟高。因此,如何降低LLM推理过程中的token数量,同时保持甚至提升性能,是本文要解决的核心问题。
核心思路:论文的核心思路是通过“习惯性推理蒸馏”将LLM的显式推理过程压缩并内化到模型的参数中,使其在推理时无需生成大量的中间token就能直接给出答案。这种方法借鉴了人类的认知方式,即通过长期训练,将复杂的推理过程转化为一种习惯性的、快速的反应。
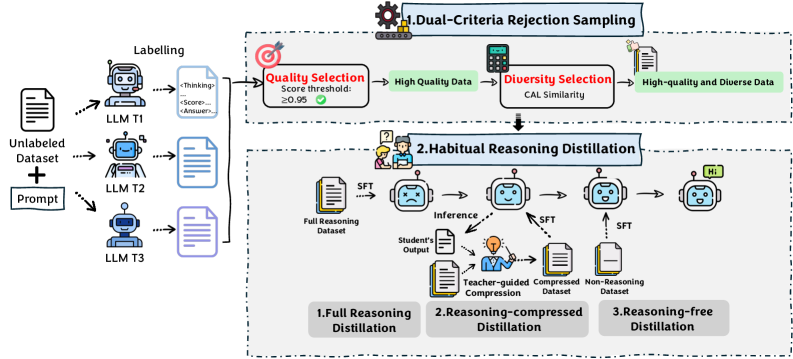
技术框架:TwT方法主要包含两个关键模块:习惯性推理蒸馏(Habitual Reasoning Distillation)和双重标准拒绝采样(Dual-Criteria Rejection Sampling, DCRS)。首先,利用多个教师模型(Teacher LLMs)生成推理轨迹数据。然后,使用DCRS方法对这些数据进行筛选,生成高质量、多样化的蒸馏数据集。最后,通过教师指导的压缩策略,将这些推理知识蒸馏到学生模型(Student LLM)中,使其具备“习惯性推理”能力。
关键创新:TwT的关键创新在于提出了“习惯性推理蒸馏”的概念,并设计了相应的训练方法。与传统的知识蒸馏方法不同,TwT更加注重将推理过程本身进行压缩和内化,而不是简单地模仿教师模型的输出。此外,DCRS方法能够有效地利用多个教师模型的优势,生成更具代表性的蒸馏数据集。
关键设计:DCRS方法是关键设计之一,它使用两个标准来筛选数据:一是基于教师模型输出的置信度,选择置信度高的样本;二是基于学生模型和教师模型输出的一致性,选择一致性高的样本。这种双重标准能够保证蒸馏数据集的质量和多样性。此外,损失函数的设计也至关重要,需要平衡学生模型对教师模型输出的模仿和对推理过程的内化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TwT在减少推理成本的同时,显著提升了模型性能。具体来说,与其他蒸馏方法相比,TwT在更少的输出token的情况下,准确率提高了高达13.6%。这一结果表明,TwT能够有效地将推理知识蒸馏到学生模型中,使其在推理时更加高效和准确。此外,实验还验证了DCRS方法在生成高质量蒸馏数据集方面的有效性。
🎯 应用场景
TwT方法可广泛应用于需要高效LLM推理的场景,例如移动设备上的智能助手、边缘计算环境下的自然语言处理应用等。通过降低推理成本,TwT能够使LLM在资源受限的环境中部署成为可能,从而加速LLM技术的普及和应用。此外,该方法还可以用于训练更小、更快的LLM,降低模型训练和部署的总体成本。
📄 摘要(原文)
Large Language Models (LLMs) have made significant strides in problem-solving by incorporating reasoning processes. However, this enhanced reasoning capability results in an increased number of output tokens during inference, leading to higher computational costs. To address this challenge, we propose TwT (Thinking without Tokens), a method that reduces inference-time costs through habitual reasoning distillation with multi-teachers' guidance, while maintaining high performance. Our approach introduces a Habitual Reasoning Distillation method, which internalizes explicit reasoning into the model's habitual behavior through a Teacher-Guided compression strategy inspired by human cognition. Additionally, we propose Dual-Criteria Rejection Sampling (DCRS), a technique that generates a high-quality and diverse distillation dataset using multiple teacher models, making our method suitable for unsupervised scenarios. Experimental results demonstrate that TwT effectively reduces inference costs while preserving superior performance, achieving up to a 13.6% improvement in accuracy with fewer output tokens compared to other distillation methods, offering a highly practical solution for efficient LLM deployment.