TeleAntiFraud-28k: An Audio-Text Slow-Thinking Dataset for Telecom Fraud Detection
作者: Zhiming Ma, Peidong Wang, Minhua Huang, Jingpeng Wang, Kai Wu, Xiangzhao Lv, Yachun Pang, Yin Yang, Wenjie Tang, Yuchen Kang
分类: cs.CL, cs.MM
发布日期: 2025-03-31 (更新: 2025-08-18)
🔗 代码/项目: GITHUB
💡 一句话要点
提出TeleAntiFraud-28k:一个用于电信诈骗检测的音频-文本慢思考数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电信诈骗检测 多模态数据 音频文本 数据合成 大型语言模型
📋 核心要点
- 电信诈骗检测面临缺乏高质量多模态训练数据的挑战,现有方法难以有效整合音频信号和推理文本分析。
- TeleAntiFraud-28k数据集通过隐私保护的样本生成、语义增强和多智能体对抗合成,构建了包含丰富诈骗场景和推理标注的音频-文本数据集。
- 该数据集包含28k+样本,并构建了评估基准TeleAntiFraud-Bench,同时提供了一个SFT模型和数据处理框架,促进社区研究。
📝 摘要(中文)
本文提出TeleAntiFraud-28k,首个开源的音频-文本慢思考数据集,专为自动电信诈骗分析设计,旨在解决高质量多模态训练数据匮乏的问题。该数据集通过三种策略构建:(1) 使用自动语音识别(ASR)转录的通话录音生成保护隐私的文本真值样本,并通过文本到语音(TTS)模型再生确保真实世界一致性(原始音频已匿名化);(2) 通过基于大型语言模型(LLM)的自指令采样增强语义,扩展场景覆盖;(3) 通过预定义的通信场景和诈骗类型,进行多智能体对抗合成,模拟新兴诈骗策略。生成的数据集包含28511个经过严格处理的语音-文本对,并带有详细的诈骗推理注释。数据集分为三个任务:场景分类、诈骗检测、诈骗类型分类。此外,构建了TeleAntiFraud-Bench,一个包含按比例采样的实例的标准评估基准,以促进模型在电信诈骗检测任务上的系统测试。同时贡献了一个在混合真实/合成数据上训练的生产优化监督微调(SFT)模型,并开源了数据处理框架,以支持社区驱动的数据集扩展。这项工作为多模态反诈骗研究建立了一个基础框架,同时解决了数据隐私和场景多样性方面的关键挑战。
🔬 方法详解
问题定义:论文旨在解决电信诈骗检测领域缺乏高质量、多样化的多模态(音频-文本)训练数据的问题。现有方法要么依赖于真实数据,存在隐私泄露风险,要么数据量不足,难以覆盖各种诈骗场景,导致模型泛化能力差。此外,现有数据集通常缺乏对诈骗推理过程的详细标注,不利于模型学习深层次的诈骗模式。
核心思路:论文的核心思路是通过结合自动语音识别(ASR)、文本到语音(TTS)、大型语言模型(LLM)和多智能体对抗合成等技术,生成高质量的合成数据,并与少量真实数据混合,从而构建一个既保护隐私、又具有丰富场景和详细标注的电信诈骗检测数据集。这种方法旨在解决数据稀缺和隐私敏感问题,同时提升模型的泛化能力和推理能力。
技术框架:TeleAntiFraud-28k数据集的构建流程主要包含以下三个阶段: 1. 隐私保护的文本真值样本生成:利用ASR将真实的通话录音转录为文本,并进行匿名化处理。然后,使用TTS模型将文本重新生成语音,确保数据的一致性。 2. 基于LLM的语义增强:利用LLM对ASR输出的文本进行自指令采样,生成更多样化的诈骗场景,从而扩展数据集的覆盖范围。 3. 多智能体对抗合成:通过预定义的通信场景和诈骗类型,模拟新兴的诈骗策略,生成更具挑战性的样本。多个智能体扮演不同的角色,进行对话,模拟诈骗过程。 最终,数据集包含28511个语音-文本对,并带有详细的诈骗推理注释。
关键创新:该论文的关键创新在于: 1. 多模态数据生成方法:结合ASR、TTS、LLM和多智能体对抗合成,生成高质量、多样化的合成数据,有效解决了数据稀缺和隐私敏感问题。 2. 慢思考数据集:数据集包含详细的诈骗推理注释,有助于模型学习深层次的诈骗模式,提升模型的推理能力。 3. 开源数据集和基准:开源数据集TeleAntiFraud-28k和评估基准TeleAntiFraud-Bench,促进了社区对电信诈骗检测问题的研究。
关键设计: 1. 隐私保护:使用ASR转录和TTS合成,避免直接使用原始语音数据,保护用户隐私。 2. 场景多样性:通过LLM自指令采样和多智能体对抗合成,覆盖各种诈骗场景,提升模型的泛化能力。 3. 详细标注:对每个样本进行详细的诈骗推理标注,包括诈骗类型、诈骗目标、诈骗手段等,有助于模型学习深层次的诈骗模式。 4. 数据混合:将合成数据与少量真实数据混合,提升模型的鲁棒性。
🖼️ 关键图片
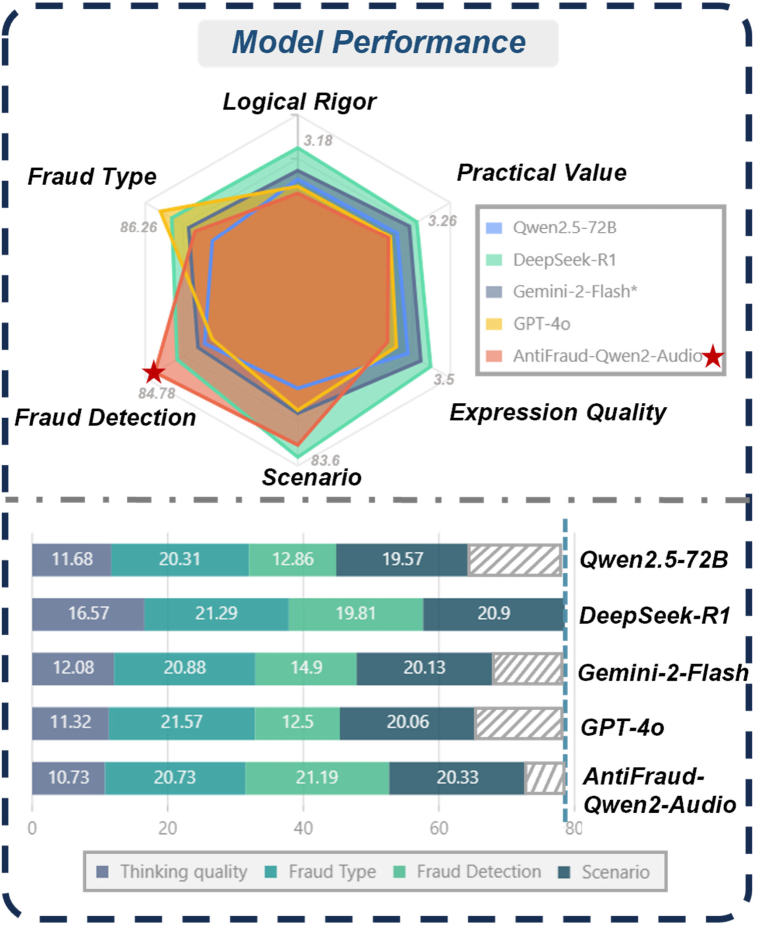


📊 实验亮点
论文构建了包含28511个样本的TeleAntiFraud-28k数据集,并进行了详细的诈骗推理标注。同时,论文提供了一个在混合真实/合成数据上训练的SFT模型,并在TeleAntiFraud-Bench上进行了评估。具体性能数据未知,但论文强调该模型是生产优化的,表明其具有一定的实用价值。
🎯 应用场景
该研究成果可应用于智能反诈骗系统,自动识别和预警电信诈骗行为。通过分析通话录音和文本内容,系统能够检测潜在的诈骗风险,并及时提醒用户,从而减少诈骗案件的发生。此外,该数据集和基准可以促进反诈骗技术的研究和发展,为构建更有效的反诈骗模型提供支持。
📄 摘要(原文)
The detection of telecom fraud faces significant challenges due to the lack of high-quality multimodal training data that integrates audio signals with reasoning-oriented textual analysis. To address this gap, we present TeleAntiFraud-28k, the first open-source audio-text slow-thinking dataset specifically designed for automated telecom fraud analysis. Our dataset is constructed through three strategies: (1) Privacy-preserved text-truth sample generation using automatically speech recognition (ASR)-transcribed call recordings (with anonymized original audio), ensuring real-world consistency through text-to-speech (TTS) model regeneration; (2) Semantic enhancement via large language model (LLM)-based self-instruction sampling on authentic ASR outputs to expand scenario coverage; (3) Multi-agent adversarial synthesis that simulates emerging fraud tactics through predefined communication scenarios and fraud typologies. The generated dataset contains 28,511 rigorously processed speech-text pairs, complete with detailed annotations for fraud reasoning. The dataset is divided into three tasks: scenario classification, fraud detection, fraud type classification. Furthermore, we construct TeleAntiFraud-Bench, a standardized evaluation benchmark comprising proportionally sampled instances from the dataset, to facilitate systematic testing of model performance on telecom fraud detection tasks. We also contribute a production-optimized supervised fine-tuning (SFT) model trained on hybrid real/synthetic data, while open-sourcing the data processing framework to enable community-driven dataset expansion. This work establishes a foundational framework for multimodal anti-fraud research while addressing critical challenges in data privacy and scenario diversity. The project will be released at https://github.com/JimmyMa99/TeleAntiFraud.