Dynamic Parametric Retrieval Augmented Generation for Test-time Knowledge Enhancement
作者: Yuqiao Tan, Shizhu He, Huanxuan Liao, Jun Zhao, Kang Liu
分类: cs.CL, cs.AI
发布日期: 2025-03-31 (更新: 2025-05-06)
备注: preprint. Code is available at https://github.com/Trae1ounG/DyPRAG
🔗 代码/项目: GITHUB
💡 一句话要点
提出动态参数检索增强生成(DyPRAG)框架,解决测试时知识增强的效率与泛化问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 参数化知识 动态学习 知识融合 大型语言模型 测试时知识增强 参数翻译
📋 核心要点
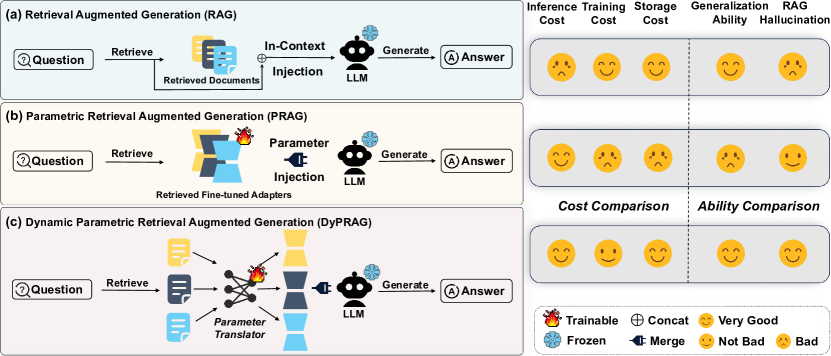
- 现有参数化RAG方法训练和存储成本高昂,泛化能力有限,难以实际应用。
- DyPRAG利用轻量级参数翻译模型,动态地将文档转换为参数化知识,实现高效的测试时知识增强。
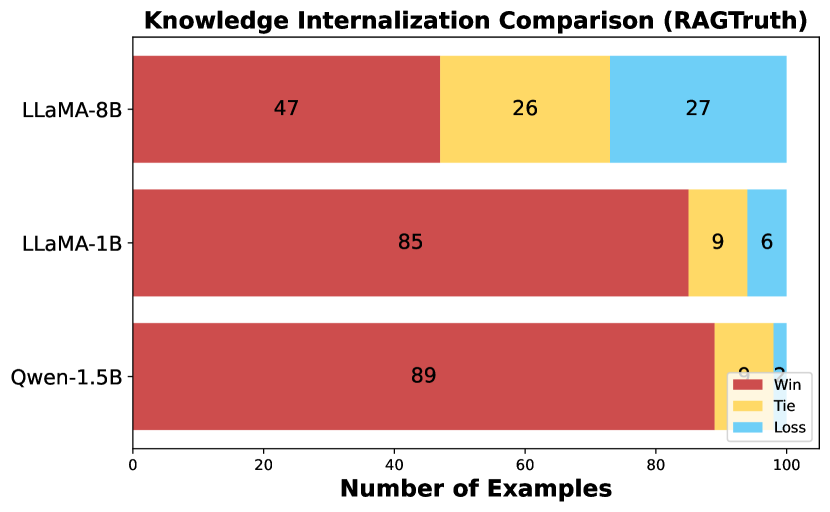
- 实验证明DyPRAG在多个数据集上有效,能够提升知识融合效果并缓解RAG幻觉问题。
📝 摘要(中文)
检索增强生成(RAG)通过从外部源检索相关文档并将其融入上下文来增强大型语言模型(LLMs)。虽然它通过提供事实文本提高了可靠性,但随着上下文长度的增加,它显著增加了推理成本,并引入了RAG幻觉这一难题,这主要是由于LLMs中缺乏相应的参数化知识。一个有效的解决方案是在测试时增强LLMs的知识。参数化RAG(PRAG)通过将文档嵌入LLMs参数来执行测试时知识增强来解决这个问题,通过离线训练有效地降低了推理成本。然而,其高昂的训练和存储成本,以及有限的泛化能力,极大地限制了其在实践中的应用。为了应对这些挑战,我们提出了一种新颖的框架——动态参数化RAG(DyPRAG),该框架利用轻量级的参数翻译模型来有效地将文档转换为参数化知识。DyPRAG不仅降低了推理、训练和存储成本,而且动态地生成参数化知识,在测试时以即插即用的方式无缝地增强LLMs的知识并解决知识冲突。在多个数据集上进行的大量实验证明了DyPRAG的有效性和泛化能力,提供了一种强大而实用的RAG范例,能够在实际应用中实现卓越的知识融合并减轻RAG幻觉。
🔬 方法详解
问题定义:现有的参数化RAG(PRAG)方法虽然能将文档嵌入LLM参数中,以降低推理成本,但面临训练成本高、存储空间需求大以及泛化能力不足的问题。这些问题限制了PRAG的实际应用,尤其是在需要处理大量文档和快速适应新知识的场景下。
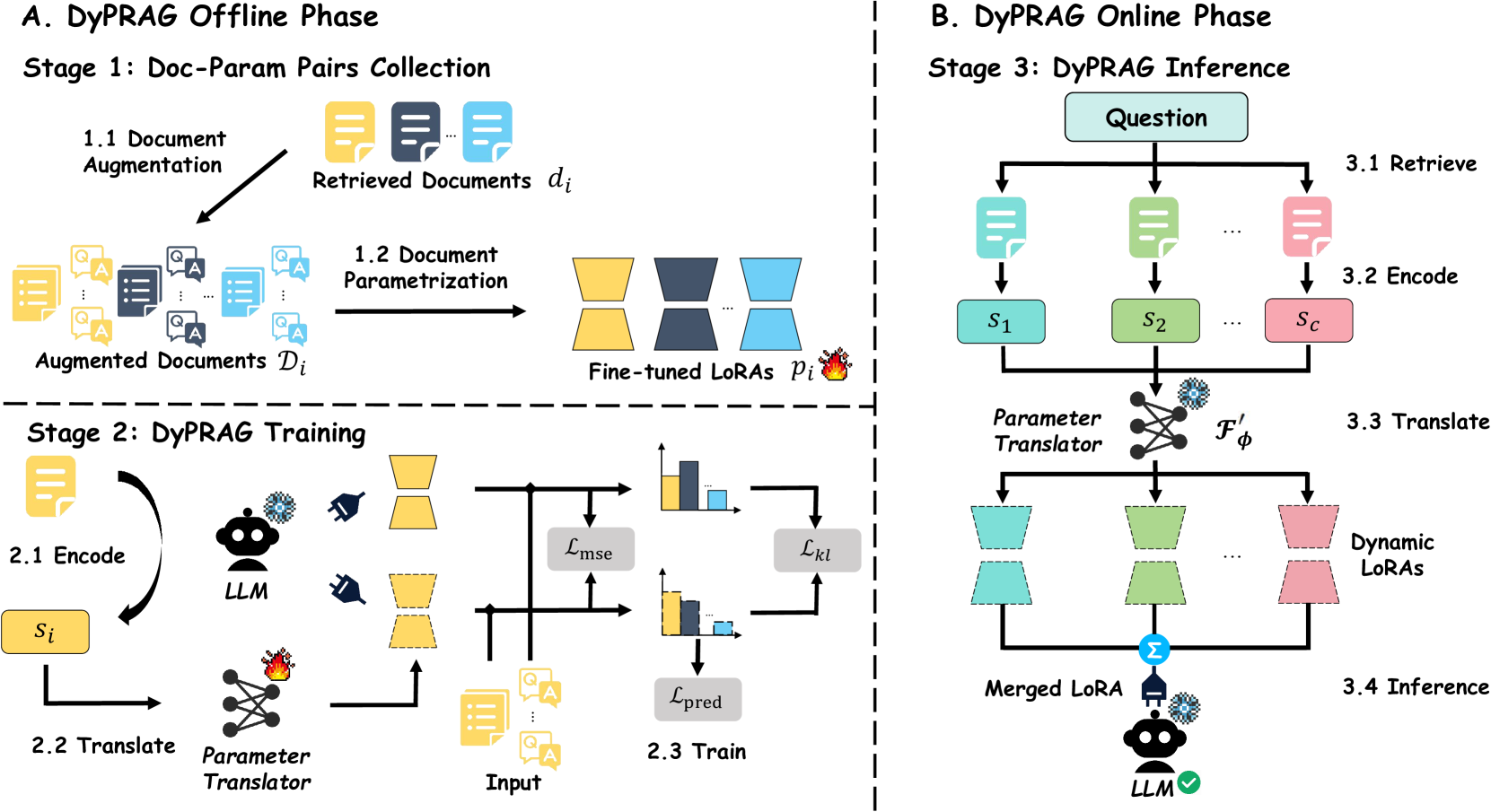
核心思路:DyPRAG的核心思路是引入一个轻量级的参数翻译模型,该模型可以将文档动态地转换为参数化知识。通过这种方式,避免了对整个LLM进行大规模的重新训练,从而显著降低了训练和存储成本。同时,动态生成参数化知识使得模型能够灵活地适应新的信息,提高了泛化能力。
技术框架:DyPRAG框架主要包含三个模块:文档编码器、参数翻译器和LLM。文档编码器负责将输入的文档转换为向量表示。参数翻译器则将文档向量转换为LLM可以理解的参数更新。最后,LLM利用这些参数更新来增强自身的知识。整个流程在测试时进行,实现了即插即用的知识增强。
关键创新:DyPRAG最重要的创新点在于其动态参数翻译机制。与传统的PRAG方法需要离线训练整个LLM不同,DyPRAG只需要训练一个轻量级的参数翻译器。这种方法不仅降低了训练成本,还使得模型能够动态地适应新的知识,从而提高了泛化能力。
关键设计:参数翻译器的具体结构未知,但可以推测其目标是学习一个映射函数,将文档编码向量映射到LLM参数空间的更新向量。损失函数的设计可能包括重构损失(确保翻译后的参数能够有效表达文档信息)和知识融合损失(确保新知识与LLM原有知识的平滑融合)。具体的网络结构和参数设置需要参考论文的详细描述。
🖼️ 关键图片
📊 实验亮点
论文在多个数据集上进行了实验,证明了DyPRAG的有效性和泛化能力。具体的性能数据未知,但摘要中提到DyPRAG能够显著降低推理、训练和存储成本,并有效缓解RAG幻觉问题。实验结果表明,DyPRAG是一种强大而实用的RAG范例,能够在实际应用中实现卓越的知识融合。
🎯 应用场景
DyPRAG可应用于需要快速适应新知识的问答系统、对话生成、信息检索等领域。例如,在金融领域,可以快速将最新的政策法规融入LLM,提高其回答的准确性和时效性。在医疗领域,可以动态更新医学知识库,辅助医生进行诊断和治疗。该方法具有广泛的应用前景,能够提升LLM在各种实际场景中的表现。
📄 摘要(原文)
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by retrieving relevant documents from external sources and incorporating them into the context. While it improves reliability by providing factual texts, it significantly increases inference costs as context length grows and introduces challenging issue of RAG hallucination, primarily caused by the lack of corresponding parametric knowledge in LLMs. An efficient solution is to enhance the knowledge of LLMs at test-time. Parametric RAG (PRAG) addresses this by embedding document into LLMs parameters to perform test-time knowledge enhancement, effectively reducing inference costs through offline training. However, its high training and storage costs, along with limited generalization ability, significantly restrict its practical adoption. To address these challenges, we propose Dynamic Parametric RAG (DyPRAG), a novel framework that leverages a lightweight parameter translator model to efficiently convert documents into parametric knowledge. DyPRAG not only reduces inference, training, and storage costs but also dynamically generates parametric knowledge, seamlessly enhancing the knowledge of LLMs and resolving knowledge conflicts in a plug-and-play manner at test-time. Extensive experiments on multiple datasets demonstrate the effectiveness and generalization capabilities of DyPRAG, offering a powerful and practical RAG paradigm which enables superior knowledge fusion and mitigates RAG hallucination in real-world applications. Our code is available at https://github.com/Trae1ounG/DyPRAG.