Adaptive Layer-skipping in Pre-trained LLMs
作者: Xuan Luo, Weizhi Wang, Xifeng Yan
分类: cs.CL, cs.AI
发布日期: 2025-03-31 (更新: 2025-10-08)
期刊: Second Conference on Language Modeling, 2025
💡 一句话要点
FlexiDepth:一种预训练LLM的自适应层跳跃方法,在Llama-3-8B上实现显著加速。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 层跳跃 自适应计算 模型加速 Transformer 推理优化 Llama-3 动态层选择
📋 核心要点
- 现有层跳跃方法忽略了不同token生成过程中计算需求差异这一关键问题。
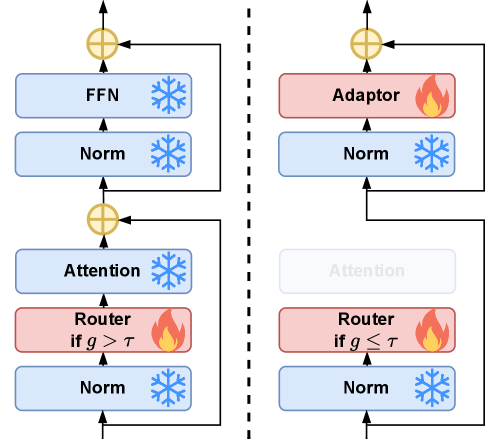
- FlexiDepth通过引入可插拔的路由模块和适配器,动态调整Transformer层数,实现自适应计算。
- 在Llama-3-8B上,FlexiDepth在保持性能的同时,成功跳过了32层中的8层,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为FlexiDepth的方法,用于加速大型语言模型(LLM)中的token生成,该方法通过动态调整文本生成中使用的Transformer层数来实现。FlexiDepth包含一个可插入的路由模块和适配器,从而在不修改原始模型参数的情况下,实现LLM的自适应计算。在Llama-3-8B上的实验表明,该方法可以在保持基准性能的同时,跳过32层中的8层。实验还揭示了LLM中计算需求随token类型的显著变化:生成重复token或固定短语所需的层数较少,而生成涉及计算或高不确定性的token则需要更多层。尽管节省了计算量,但由于跳跃模式的多样性和I/O开销,FlexiDepth尚未实现实际的加速。为了促进未来研究,作者开源了FlexiDepth及其层分配模式数据集。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在生成文本时,通常对所有token都使用相同数量的Transformer层,忽略了不同token生成所需的计算量可能存在差异。这种静态的计算方式效率较低,尤其是在生成重复性或低复杂度的token时,造成了不必要的计算浪费。因此,如何根据token的复杂度和不确定性动态调整所需的计算量,是本文要解决的核心问题。
核心思路:FlexiDepth的核心思路是根据每个token的实际需求,动态地选择需要使用的Transformer层数。对于简单的token,跳过部分层以减少计算量;对于复杂的token,则使用更多的层以保证生成质量。这种自适应的层跳跃策略可以在保证模型性能的同时,显著降低计算成本。
技术框架:FlexiDepth的技术框架主要包括两个关键组件:路由模块(Router)和适配器(Adapter)。路由模块负责根据当前token的特征,预测需要使用的Transformer层数。适配器则负责将路由模块的输出转换为对Transformer层的控制信号,从而实现动态的层跳跃。整个框架可以作为一个插件集成到现有的LLM中,无需修改原始模型的参数。
关键创新:FlexiDepth的关键创新在于其动态层跳跃机制,它能够根据token的特性自适应地调整计算量。与传统的静态层跳跃方法相比,FlexiDepth更加灵活和高效,能够在保证模型性能的同时,显著降低计算成本。此外,FlexiDepth的插件式设计使其易于集成到现有的LLM中,具有很强的实用性。
关键设计:路由模块的设计至关重要,它需要能够准确地预测每个token所需的层数。论文中可能使用了某种神经网络结构来实现路由模块,例如一个小型的前馈网络或循环神经网络。适配器的设计也需要考虑如何将路由模块的输出有效地转换为对Transformer层的控制信号,例如通过调整Transformer层的输入或输出的权重。具体的损失函数可能包括一个性能损失项和一个计算成本项,用于平衡模型性能和计算效率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FlexiDepth在Llama-3-8B上实现了显著的计算节省,能够在保持基准性能的同时,跳过32层中的8层。这表明FlexiDepth能够有效地降低LLM的计算复杂度,提高推理效率。虽然由于I/O开销等原因,FlexiDepth尚未实现实际的wall-clock speedup,但其在计算节省方面的潜力是巨大的,为未来的研究提供了重要的方向。
🎯 应用场景
FlexiDepth具有广泛的应用前景,可以应用于各种需要加速LLM推理的场景,例如移动设备上的文本生成、实时对话系统和低功耗服务器。通过降低计算成本,FlexiDepth可以使LLM在资源受限的环境中更加高效地运行,从而扩展LLM的应用范围,并降低使用成本。此外,该方法还可以用于研究LLM内部的计算过程,帮助我们更好地理解LLM的工作原理。
📄 摘要(原文)
Various layer-skipping methods have been proposed to accelerate token generation in large language models (LLMs). However, limited attention has been paid to a fundamental question: How do computational demands vary across the generation of different tokens? In this work, we introduce FlexiDepth, a method that dynamically adjusts the number of Transformer layers used in text generation. By incorporating a plug-in router and adapter, FlexiDepth enables adaptive computation in LLMs without modifying their original parameters. Applied to Llama-3-8B, it skips 8 out of 32 layers while maintaining full benchmark performance. Our experiments reveal that computational demands in LLMs significantly vary based on token type. Specifically, generating repetitive tokens or fixed phrases requires fewer layers, whereas producing tokens involving computation or high uncertainty requires more layers. Despite the computational savings, FlexiDepth does not yet achieve wall-clock speedup due to varied skipping patterns and I/O overhead. To inspire future work and advance research on practical speedup, we open-sourced FlexiDepth and a dataset documenting its layer allocation patterns.