Texture or Semantics? Vision-Language Models Get Lost in Font Recognition
作者: Zhecheng Li, Guoxian Song, Yujun Cai, Zhen Xiong, Junsong Yuan, Yiwei Wang
分类: cs.CL, cs.CV
发布日期: 2025-03-31 (更新: 2025-09-25)
备注: Accepted to COLM 2025
💡 一句话要点
揭示视觉-语言模型在字体识别中易受纹理干扰,语义理解能力不足
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 字体识别 细粒度识别 Stroop效应 基准数据集
📋 核心要点
- 现有视觉-语言模型在细粒度字体识别任务中表现不佳,容易受到文本内容干扰,无法有效利用语义信息。
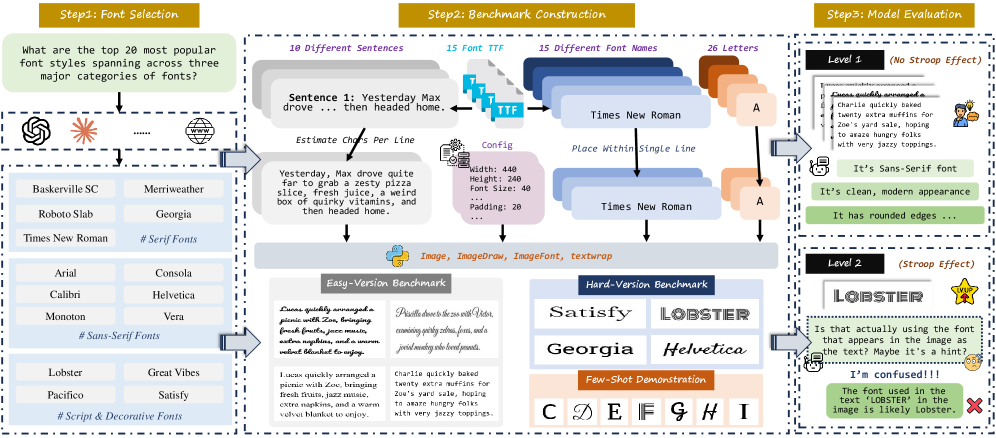
- 论文构建字体识别基准FRB,包含简单和困难两种版本,旨在评估视觉-语言模型在字体识别方面的能力。
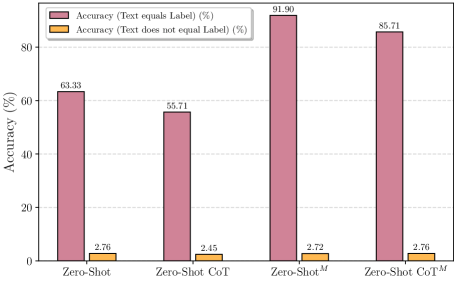
- 实验结果表明,现有模型在FRB上表现欠佳,且少量样本学习和思维链提示无法显著提升性能,暴露了模型局限性。
📝 摘要(中文)
现代视觉-语言模型(VLMs)在图像识别和目标定位等任务中表现出卓越的视觉和语言能力。然而,它们在细粒度任务中的有效性仍是一个开放性问题。在日常生活中,人们可能希望识别设计材料(如杂志、排版教程、研究论文或品牌内容)中使用的美观字体。鉴于其多模态能力和免费可访问性,许多VLMs通常被认为是字体识别的潜在工具。本文旨在探究VLMs是否真正具备字体识别能力。为此,我们引入了字体识别基准(FRB),这是一个包含15种常用字体的紧凑且结构良好的数据集。FRB包括两个版本:(i)简单版本,其中10个句子以不同的字体呈现;(ii)困难版本,其中每个文本样本包含15种字体本身的名称,引入了Stroop效应,挑战模型的感知能力。通过对各种VLMs在字体识别任务上的广泛评估,我们发现:(i)当前的VLMs字体识别能力有限,许多最先进的模型未能取得令人满意的性能,并且容易受到文本信息引入的Stroop效应的影响。(ii)少量样本学习和思维链(CoT)提示在提高不同VLMs的字体识别准确率方面提供的益处甚微。(iii)注意力分析揭示了VLMs在捕获语义特征方面的固有局限性。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型在细粒度字体识别任务中的不足。现有方法在处理字体识别时,容易受到文本内容(特别是字体名称本身)的干扰,无法有效提取字体本身的视觉特征,导致识别准确率低。现有方法缺乏对字体语义信息的有效利用,更多依赖于纹理等低级特征。
核心思路:论文的核心思路是通过构建一个专门的字体识别基准FRB,来系统地评估和分析现有视觉-语言模型在字体识别方面的能力。FRB包含简单和困难两种版本,困难版本引入了Stroop效应,旨在考察模型在干扰信息下的鲁棒性。通过分析模型在FRB上的表现,揭示模型在字体识别方面的局限性,并为未来的研究提供方向。
技术框架:论文主要通过构建数据集和实验评估来研究问题。FRB数据集包含15种常用字体,分为简单版本(随机句子)和困难版本(字体名称)。实验部分,选取了多种视觉-语言模型进行评估,并尝试了少量样本学习和思维链提示等方法来提升性能。最后,通过注意力分析来理解模型关注的特征。
关键创新:论文的关键创新在于构建了一个专门用于评估视觉-语言模型字体识别能力的基准数据集FRB。该数据集的困难版本引入了Stroop效应,能够更有效地考察模型在干扰信息下的鲁棒性。此外,论文还通过注意力分析,深入探讨了模型在字体识别过程中关注的特征,揭示了模型在语义理解方面的局限性。
关键设计:FRB数据集包含15种常用字体,每种字体包含多个文本样本。困难版本通过使用字体名称作为文本内容,引入Stroop效应。实验中,使用了多种视觉-语言模型,并尝试了不同的训练策略(如少量样本学习)和推理策略(如思维链提示)。注意力分析通过可视化模型在不同层级的注意力权重,来理解模型关注的特征。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有视觉-语言模型在FRB数据集上表现不佳,即使是最先进的模型也难以达到令人满意的准确率。在困难版本上,模型的性能显著下降,表明其容易受到Stroop效应的影响。少量样本学习和思维链提示对性能提升有限。注意力分析显示,模型更多关注纹理等低级特征,而忽略了字体本身的语义信息。
🎯 应用场景
该研究成果可应用于设计辅助工具、文档处理软件、以及信息检索系统等领域。例如,用户可以通过拍照或上传图片,快速识别图片中的字体,从而方便地进行设计、排版或信息搜索。未来的研究可以进一步探索如何提升视觉-语言模型在细粒度字体识别方面的能力,使其能够更好地服务于实际应用。
📄 摘要(原文)
Modern Vision-Language Models (VLMs) exhibit remarkable visual and linguistic capabilities, achieving impressive performance in various tasks such as image recognition and object localization. However, their effectiveness in fine-grained tasks remains an open question. In everyday scenarios, individuals encountering design materials, such as magazines, typography tutorials, research papers, or branding content, may wish to identify aesthetically pleasing fonts used in the text. Given their multimodal capabilities and free accessibility, many VLMs are often considered potential tools for font recognition. This raises a fundamental question: Do VLMs truly possess the capability to recognize fonts? To investigate this, we introduce the Font Recognition Benchmark (FRB), a compact and well-structured dataset comprising 15 commonly used fonts. FRB includes two versions: (i) an easy version, where 10 sentences are rendered in different fonts, and (ii) a hard version, where each text sample consists of the names of the 15 fonts themselves, introducing a stroop effect that challenges model perception. Through extensive evaluation of various VLMs on font recognition tasks, we arrive at the following key findings: (i) Current VLMs exhibit limited font recognition capabilities, with many state-of-the-art models failing to achieve satisfactory performance and being easily affected by the stroop effect introduced by textual information. (ii) Few-shot learning and Chain-of-Thought (CoT) prompting provide minimal benefits in improving font recognition accuracy across different VLMs. (iii) Attention analysis sheds light on the inherent limitations of VLMs in capturing semantic features.