Beyond the Reported Cutoff: Where Large Language Models Fall Short on Financial Knowledge
作者: Agam Shah, Liqin Ye, Sebastian Jaskowski, Wei Xu, Sudheer Chava
分类: cs.CL
发布日期: 2025-03-30 (更新: 2025-07-28)
备注: Paper accepted at CoLM 2025
💡 一句话要点
评估大语言模型在金融知识上的局限性:超越报告截止日期后的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 金融知识 知识评估 幻觉问题 财务数据
📋 核心要点
- 现有大语言模型在问答中作为知识来源,但其历史金融知识的覆盖范围和准确性尚不明确,存在知识盲区。
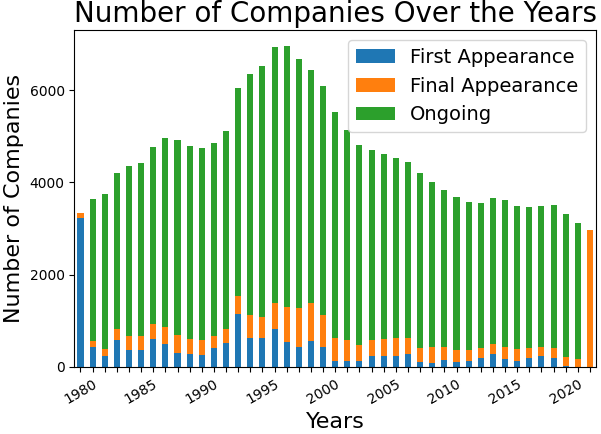
- 该研究通过构建包含19.7万个问题的金融数据集,对比LLM回答与真实财务数据,评估模型对历史金融信息的掌握程度。
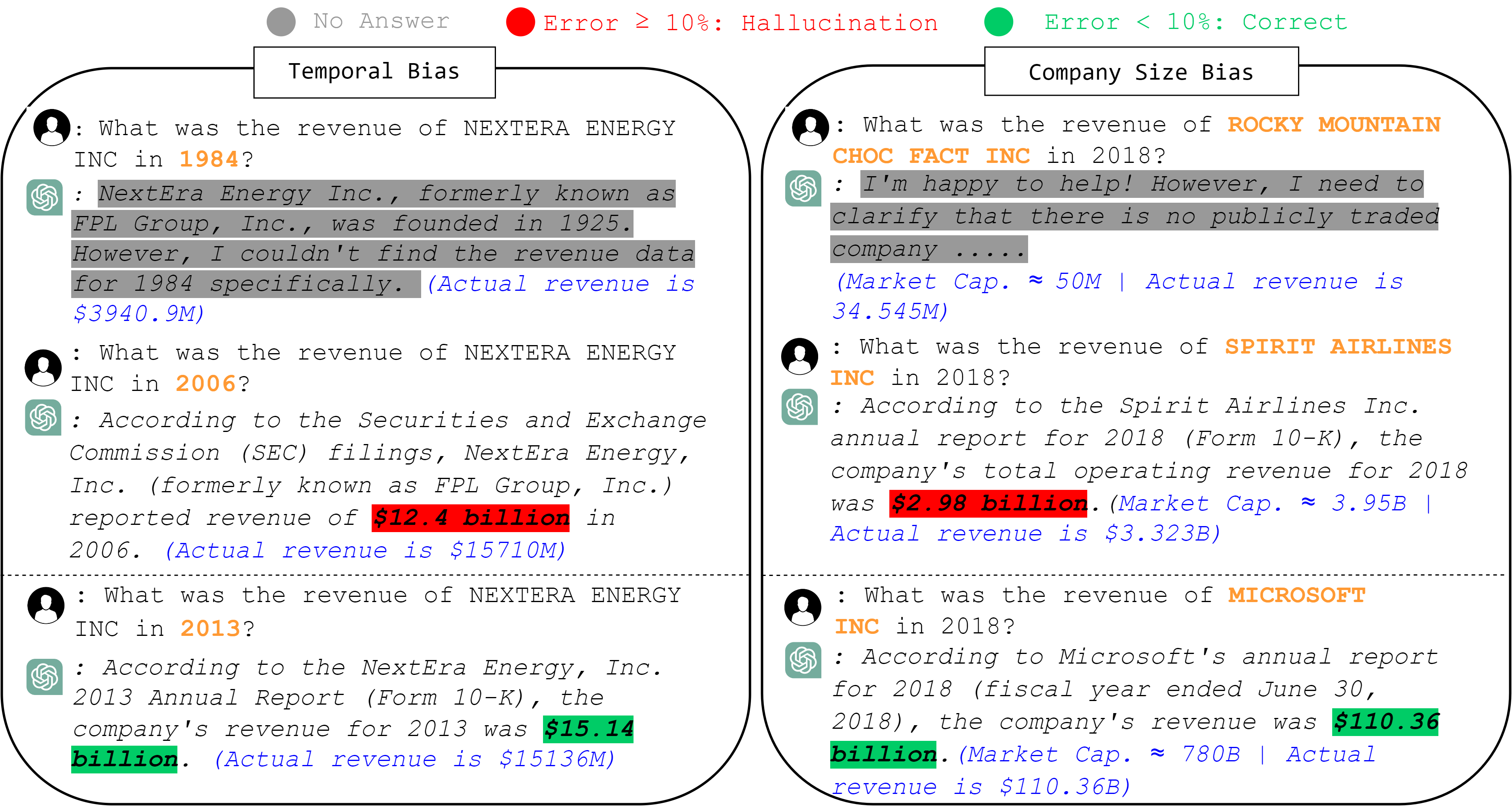
- 实验发现LLM对大型公司和近期信息掌握较好,但对历史财务数据了解不足,且更易对大型公司近期数据产生幻觉。
📝 摘要(中文)
大型语言模型(LLMs)经常被用作问答的知识来源。虽然已知LLMs可能缺乏对实时数据或模型截止日期之后产生的新数据的访问,但它们对历史信息的知识跨度如何尚不清楚。在本研究中,我们使用美国上市公司财务数据,通过评估超过19.7万个问题并将模型响应与实际数据进行比较,来评估LLMs的知识广度。我们进一步探讨了公司规模、零售投资、机构关注度和财务文件可读性等公司特征对LLMs中知识准确性的影响。结果表明,LLMs对过去的财务业绩了解较少,但对规模较大的公司和较新的信息表现出更强的认知。有趣的是,我们的分析还表明,LLMs更有可能为较大的公司产生幻觉,特别是对于较近年份的数据。代码、提示和模型输出可在GitHub上找到。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在金融知识方面的局限性,特别是它们对历史财务信息的掌握程度。现有方法主要关注LLMs对实时或近期数据的访问能力,而忽略了它们对历史数据的知识覆盖范围和准确性。现有LLMs在金融领域的应用可能因为缺乏对历史数据的准确理解而产生误导性或不准确的答案。
核心思路:论文的核心思路是通过构建一个大规模的金融问答数据集,并将其与LLMs的输出进行比较,从而量化LLMs在不同时间段和不同公司规模下的金融知识水平。通过分析LLMs的回答准确性,可以识别出LLMs在金融知识方面的薄弱环节,并为未来的模型改进提供指导。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建金融问答数据集:基于美国上市公司的财务数据,生成超过19.7万个问题。2) 使用LLMs回答问题:将问题输入到不同的LLMs中,并记录它们的回答。3) 评估回答准确性:将LLMs的回答与真实的财务数据进行比较,计算准确率。4) 分析影响因素:分析公司规模、零售投资、机构关注度和财务文件可读性等因素对LLMs回答准确性的影响。
关键创新:该研究的关键创新在于它首次系统性地评估了LLMs在历史金融知识方面的局限性。通过构建大规模的金融问答数据集,并分析不同因素对LLMs回答准确性的影响,该研究为理解LLMs的知识边界提供了新的视角。此外,该研究还揭示了LLMs在处理大型公司和近期数据时更容易产生幻觉的现象,这对于LLMs在金融领域的应用具有重要的指导意义。
关键设计:在数据集构建方面,论文使用了美国上市公司的财务数据,并生成了多种类型的问题,包括关于公司规模、财务业绩和市场表现的问题。在模型评估方面,论文使用了准确率作为评估指标,并分析了不同因素对准确率的影响。在实验设置方面,论文使用了多个不同的LLMs,并比较了它们在不同问题上的表现。论文还考虑了财务报告的可读性对模型表现的影响,并进行了相应的分析。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLMs对过去的财务业绩了解较少,但对规模较大的公司和较新的信息表现出更强的认知。同时,LLMs更有可能为较大的公司产生幻觉,特别是对于较近年份的数据。这些发现揭示了LLMs在金融知识方面的局限性,并为未来的研究提供了方向。
🎯 应用场景
该研究成果可应用于金融领域的智能问答系统、投资决策支持系统和风险管理系统。通过了解LLMs在金融知识方面的局限性,可以更好地利用LLMs的优势,并避免其潜在的风险。此外,该研究还可以为LLMs的改进提供指导,使其在金融领域能够提供更准确、更可靠的信息。
📄 摘要(原文)
Large Language Models (LLMs) are frequently utilized as sources of knowledge for question-answering. While it is known that LLMs may lack access to real-time data or newer data produced after the model's cutoff date, it is less clear how their knowledge spans across historical information. In this study, we assess the breadth of LLMs' knowledge using financial data of U.S. publicly traded companies by evaluating more than 197k questions and comparing model responses to factual data. We further explore the impact of company characteristics, such as size, retail investment, institutional attention, and readability of financial filings, on the accuracy of knowledge represented in LLMs. Our results reveal that LLMs are less informed about past financial performance, but they display a stronger awareness of larger companies and more recent information. Interestingly, at the same time, our analysis also reveals that LLMs are more likely to hallucinate for larger companies, especially for data from more recent years. The code, prompts, and model outputs are available on GitHub.