FeRG-LLM : Feature Engineering by Reason Generation Large Language Models
作者: Jeonghyun Ko, Gyeongyun Park, Donghoon Lee, Kyunam Lee
分类: cs.CL, cs.AI
发布日期: 2025-03-30
备注: Accepted to NAACL 2025 Findings
💡 一句话要点
提出FeRG-LLM,利用Reason Generation LLM自动进行表格数据特征工程。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 特征工程 大型语言模型 表格数据 Reason Generation Llama 3 直接偏好优化 自动化机器学习
📋 核心要点
- 表格数据特征工程至关重要,但依赖领域知识和人工经验,成本高昂。
- FeRG-LLM通过Reason Generation和两阶段对话,使LLM具备自动特征工程能力。
- 实验表明,FeRG-LLM性能优于或媲美更大规模模型,且资源消耗更少。
📝 摘要(中文)
本文提出了一种名为FeRG-LLM(Feature engineering by Reason Generation Large Language Models)的新框架,该框架是一个参数规模为80亿的大型语言模型,旨在自动执行特征工程。通过构建两阶段对话,使语言模型能够分析机器学习任务并发现新特征,展现其思维链(CoT)能力。该模型基于Llama 3.1 8B进行微调,并结合直接偏好优化(DPO)以接收反馈,从而提高新特征的质量和模型性能。实验结果表明,FeRG-LLM在大多数数据集上表现与Llama 3.1 70B相当或更好,同时使用更少的资源并减少了推理时间。在分类任务中优于其他研究,并在回归任务中表现良好。此外,由于它不依赖于云托管的LLM(如GPT-4)来生成特征,因此可以本地部署,从而解决了安全问题。
🔬 方法详解
问题定义:论文旨在解决表格数据机器学习中特征工程高度依赖人工和领域知识的问题。现有方法需要大量的人力投入和专业知识,限制了模型性能的提升和应用范围的扩展。
核心思路:论文的核心思路是利用大型语言模型(LLM)的推理和生成能力,通过Reason Generation的方式,模拟人类专家进行特征工程的过程。通过让LLM分析任务、发现潜在特征并生成新的特征,从而实现自动化的特征工程。
技术框架:FeRG-LLM的技术框架主要包含以下几个阶段:1) 构建两阶段对话,包括任务分析和特征发现;2) 基于Llama 3.1 8B模型进行微调;3) 采用直接偏好优化(DPO)方法,根据反馈改进特征质量和模型性能。整体流程是,首先通过对话引导LLM理解机器学习任务,然后生成候选特征,最后通过DPO进行优化。
关键创新:论文的关键创新在于:1) 提出了基于Reason Generation的特征工程方法,将LLM的推理能力应用于特征工程;2) 构建了两阶段对话,使LLM能够更好地理解任务并发现新特征;3) 结合DPO方法,通过反馈优化特征质量和模型性能。与现有方法相比,FeRG-LLM能够自动进行特征工程,减少了人工干预和领域知识的依赖。
关键设计:论文的关键设计包括:1) 两阶段对话的具体内容和形式,如何引导LLM进行任务分析和特征发现;2) DPO方法的具体实现,如何定义偏好和收集反馈;3) Llama 3.1 8B模型的微调策略,如何选择合适的训练数据和损失函数。这些设计细节直接影响了FeRG-LLM的性能和效果。
🖼️ 关键图片

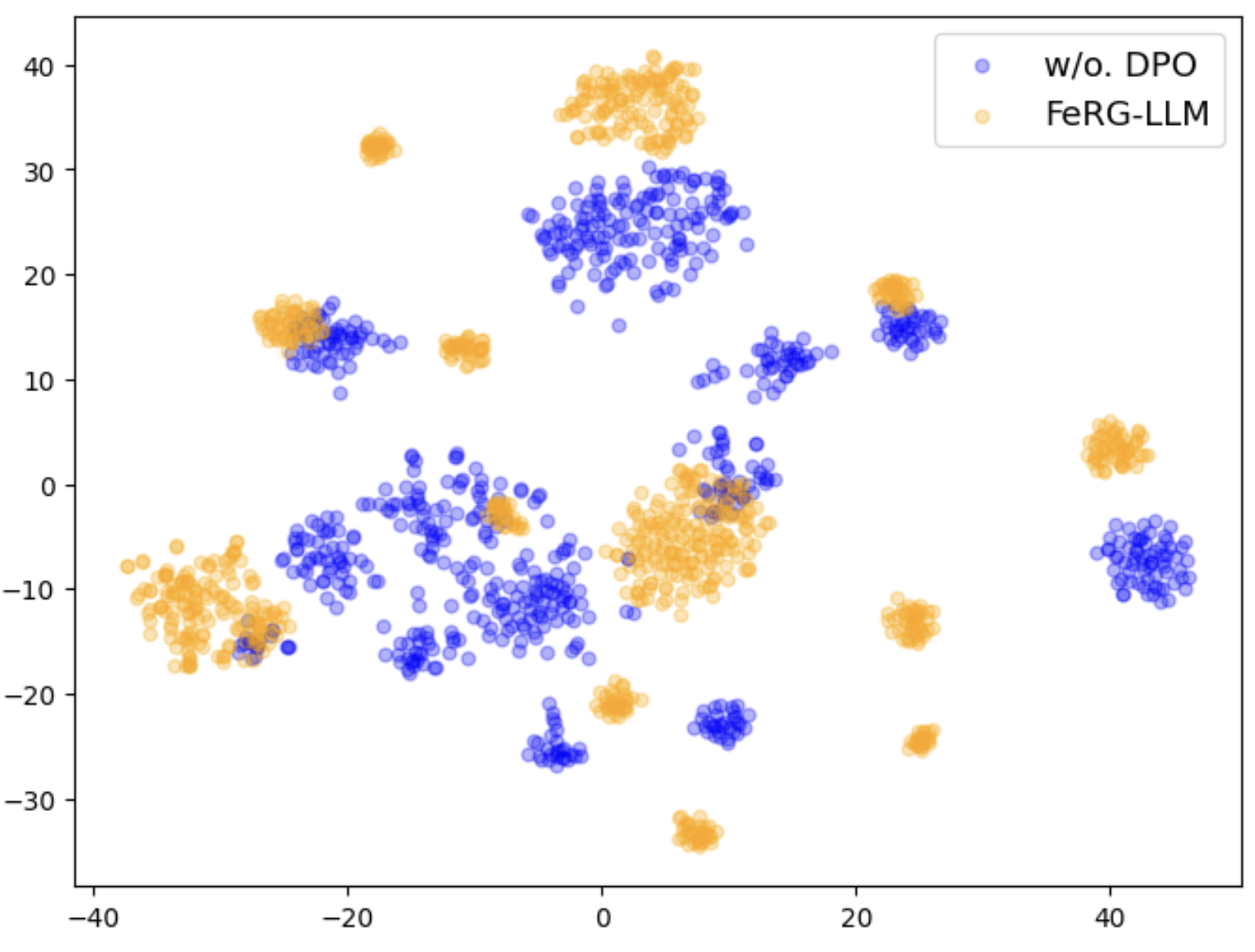
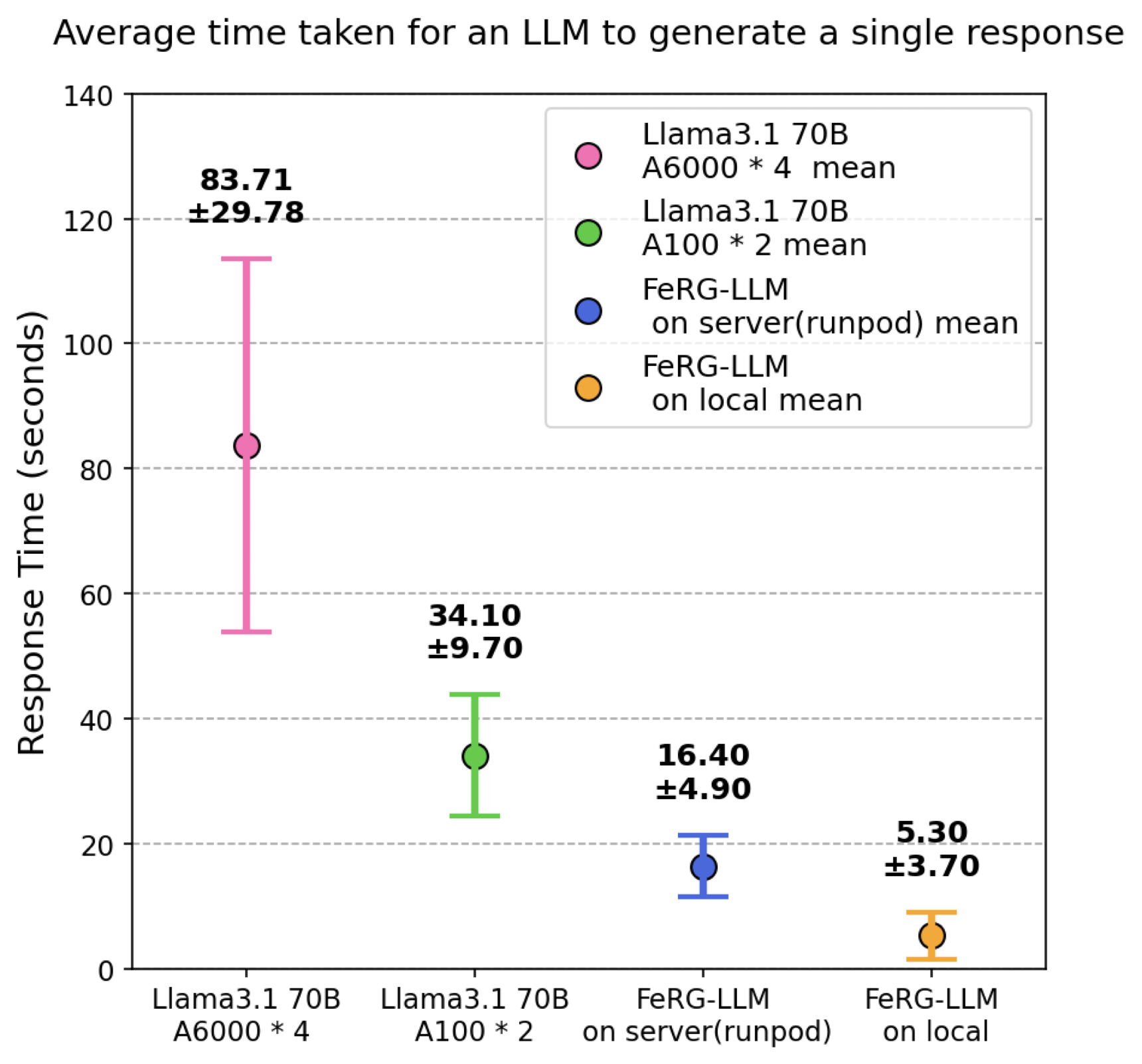
📊 实验亮点
FeRG-LLM在多个数据集上表现出优异的性能,与Llama 3.1 70B模型相比,在大多数数据集上性能相当或更好,同时显著减少了资源消耗和推理时间。在分类任务中,FeRG-LLM优于其他研究,并在回归任务中表现良好。此外,FeRG-LLM无需依赖云端API,可本地部署,保障数据安全。
🎯 应用场景
FeRG-LLM可应用于金融、医疗、电商等领域,自动为表格数据生成高质量特征,提升模型性能,降低人工成本。该研究有助于推动机器学习在各行业的应用,尤其是在缺乏领域专家的情况下,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
One of the key tasks in machine learning for tabular data is feature engineering. Although it is vital for improving the performance of models, it demands considerable human expertise and deep domain knowledge, making it labor-intensive endeavor. To address this issue, we propose a novel framework, \textbf{FeRG-LLM} (\textbf{Fe}ature engineering by \textbf{R}eason \textbf{G}eneration \textbf{L}arge \textbf{L}anguage \textbf{M}odels), a large language model designed to automatically perform feature engineering at an 8-billion-parameter scale. We have constructed two-stage conversational dialogues that enable language models to analyze machine learning tasks and discovering new features, exhibiting their Chain-of-Thought (CoT) capabilities. We use these dialogues to fine-tune Llama 3.1 8B model and integrate Direct Preference Optimization (DPO) to receive feedback improving quality of new features and the model's performance. Our experiments show that FeRG-LLM performs comparably to or better than Llama 3.1 70B on most datasets, while using fewer resources and achieving reduced inference time. It outperforms other studies in classification tasks and performs well in regression tasks. Moreover, since it does not rely on cloud-hosted LLMs like GPT-4 with extra API costs when generating features, it can be deployed locally, addressing security concerns.