Discovering Knowledge Deficiencies of Language Models on Massive Knowledge Base
作者: Linxin Song, Xuwei Ding, Jieyu Zhang, Taiwei Shi, Ryotaro Shimizu, Rahul Gupta, Yang Liu, Jian Kang, Jieyu Zhao
分类: cs.CL
发布日期: 2025-03-30
💡 一句话要点
提出随机误差上升(SEA)框架,高效发现大规模知识库中语言模型的知识缺陷。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 知识缺陷 错误发现 随机优化 知识库
📋 核心要点
- 现有方法难以在计算资源有限的情况下,全面评估闭源语言模型在大规模知识库上的知识缺陷。
- SEA框架通过随机优化过程,迭代检索与先前失败案例语义相似的高错误候选,高效发现知识缺陷。
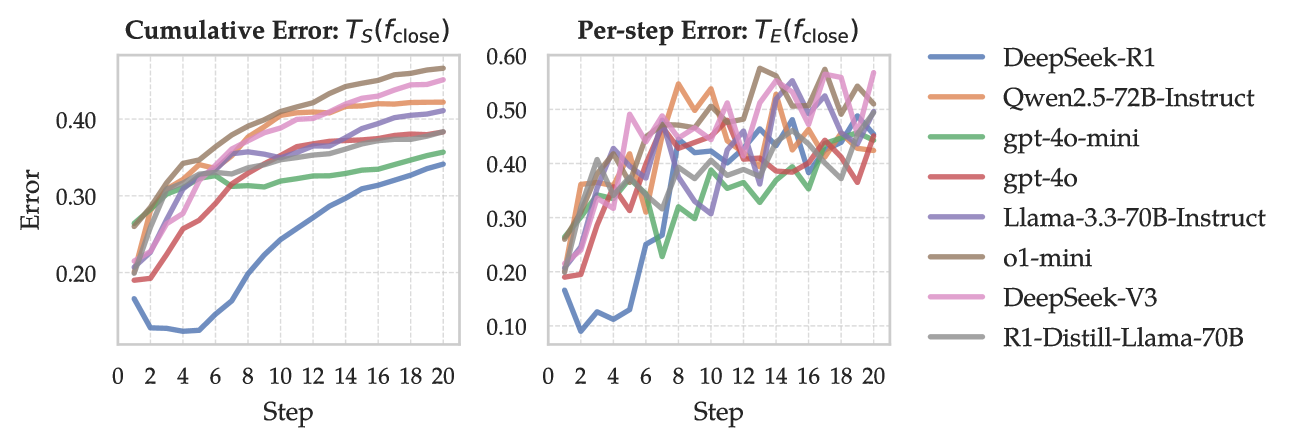
- 实验表明,SEA在发现知识错误数量和降低成本方面显著优于现有方法,并揭示了LLM的共性缺陷。
📝 摘要(中文)
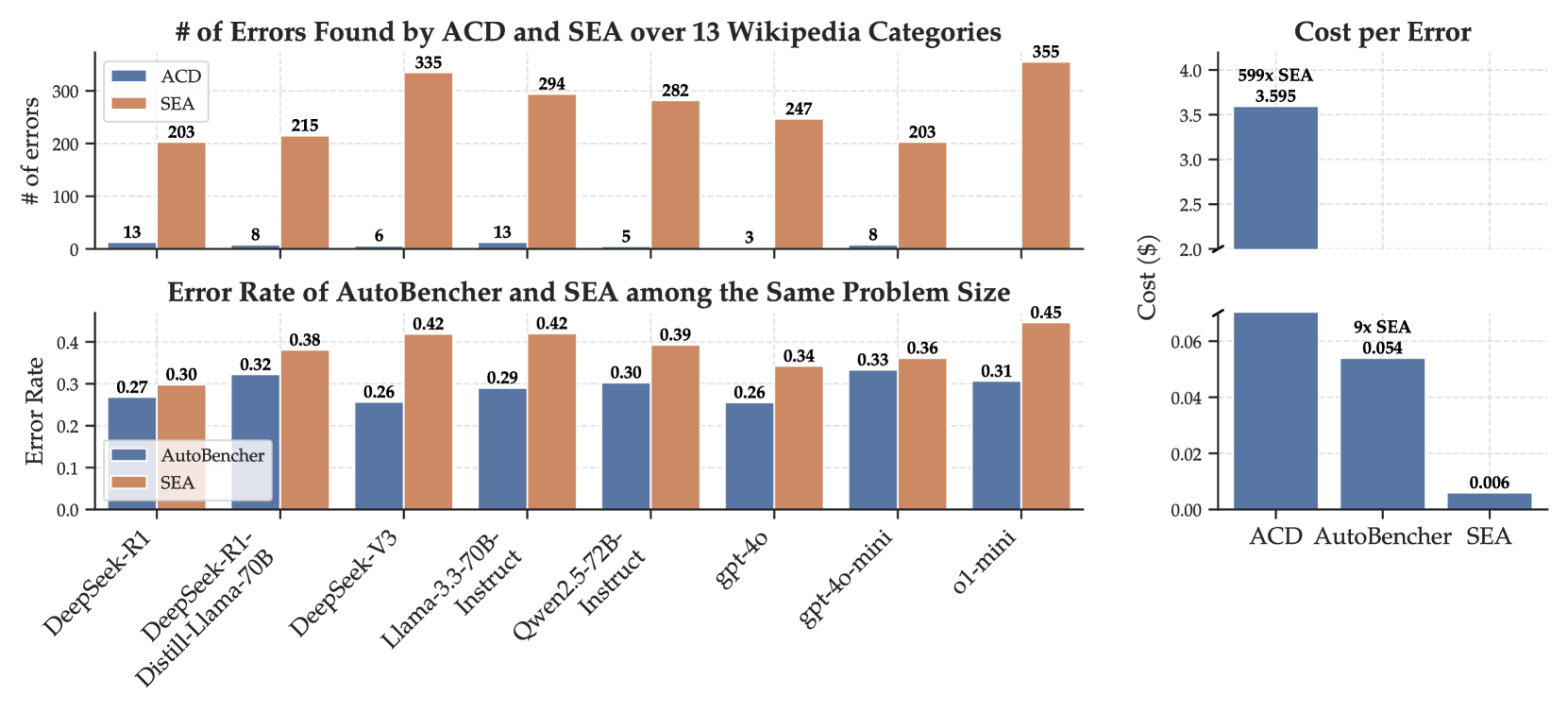
大型语言模型(LLM)虽然具备出色的语言能力,但常常无法忠实地保留事实知识,导致幻觉和不可靠的输出。要通过针对完整知识库进行详尽评估来理解LLM的知识缺陷,计算成本非常高昂,特别是对于闭源模型。我们提出了一种可扩展且高效的框架——随机误差上升(SEA),用于在严格的查询预算下发现闭源LLM中的知识缺陷(错误)。SEA并非简单地探测所有知识候选,而是将错误发现建模为一个随机优化过程:它通过利用与先前观察到的失败的语义相似性,迭代地检索新的高错误候选。为了进一步提高搜索效率和覆盖率,SEA采用跨文档和段落级别的分层检索,并构建关系有向无环图来建模错误传播并识别系统性失败模式。实验表明,SEA发现的知识错误比自动化能力发现方法多40.7倍,比AutoBencher多26.7%,同时将每个错误的成本分别降低了599倍和9倍。人工评估证实了生成问题的高质量,而消融和收敛分析验证了SEA中每个组件的贡献。对发现的错误的进一步分析揭示了LLM系列之间的相关失败模式和反复出现的缺陷,突出了未来LLM开发中需要更好的数据覆盖和有针对性的微调。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在面对大规模知识库时,由于知识保留不足而产生的幻觉和不可靠输出问题。现有方法,如简单地探测所有知识候选,计算成本高昂,尤其对于闭源模型,难以进行全面的知识缺陷评估。因此,如何高效且经济地发现LLM的知识缺陷是本研究要解决的核心问题。
核心思路:论文的核心思路是将知识缺陷的发现过程建模为一个随机优化问题。通过迭代地检索与先前观察到的错误案例在语义上相似的候选知识点,从而集中精力探索最有可能出错的区域,避免了对整个知识库的盲目搜索。这种基于错误反馈的迭代优化策略能够显著提高错误发现的效率。
技术框架:SEA框架包含以下几个主要模块:1) 分层检索模块:首先在文档级别进行粗略检索,然后细化到段落级别,以提高检索效率和覆盖率。2) 错误候选生成模块:基于检索到的文档和段落,生成针对LLM的知识问答对。3) 错误评估模块:利用LLM回答问题,并判断回答是否正确,从而识别知识缺陷。4) 关系图构建模块:构建关系有向无环图,用于建模错误传播,识别系统性失败模式。5) 随机优化模块:利用先前观察到的错误信息,指导下一轮的候选知识点检索,实现迭代优化。
关键创新:SEA的关键创新在于其将知识缺陷发现问题转化为一个随机优化问题,并利用先前发现的错误信息来指导后续的搜索过程。与传统的盲目搜索方法相比,SEA能够更有效地定位LLM的知识盲区。此外,分层检索和关系图构建进一步提高了搜索效率和覆盖率,并有助于识别系统性错误。
关键设计:SEA采用语义相似性度量来判断候选知识点与先前错误案例的相似程度,具体使用的相似度计算方法未知。关系有向无环图的构建方式以及错误传播的建模方法未知。随机优化算法的具体实现细节,例如采用的优化器、学习率等参数设置未知。论文中使用的损失函数也未知。
🖼️ 关键图片

📊 实验亮点
SEA框架在知识错误发现方面显著优于现有方法。实验结果表明,SEA发现的知识错误数量比Automated Capability Discovery方法多40.7倍,比AutoBencher多26.7%,同时将每个错误的成本分别降低了599倍和9倍。这些数据表明SEA在效率和效果上都具有显著优势。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的知识储备,提高其在知识密集型任务中的可靠性和准确性。例如,可以用于构建更可靠的问答系统、知识图谱补全和信息检索系统。此外,该方法还可以帮助开发者更好地理解LLM的局限性,从而有针对性地进行数据增强和模型微调。
📄 摘要(原文)
Large language models (LLMs) possess impressive linguistic capabilities but often fail to faithfully retain factual knowledge, leading to hallucinations and unreliable outputs. Understanding LLMs' knowledge deficiencies by exhaustively evaluating against full-scale knowledge bases is computationally prohibitive, especially for closed-weight models. We propose stochastic error ascent (SEA), a scalable and efficient framework for discovering knowledge deficiencies (errors) in closed-weight LLMs under a strict query budget. Rather than naively probing all knowledge candidates, SEA formulates error discovery as a stochastic optimization process: it iteratively retrieves new high-error candidates by leveraging the semantic similarity to previously observed failures. To further enhance search efficiency and coverage, SEA employs hierarchical retrieval across document and paragraph levels, and constructs a relation directed acyclic graph to model error propagation and identify systematic failure modes. Empirically, SEA uncovers 40.7x more knowledge errors than Automated Capability Discovery and 26.7% more than AutoBencher, while reducing the cost-per-error by 599x and 9x, respectively. Human evaluation confirms the high quality of generated questions, while ablation and convergence analyses validate the contribution of each component in SEA. Further analysis on the discovered errors reveals correlated failure patterns across LLM families and recurring deficits, highlighting the need for better data coverage and targeted fine-tuning in future LLM development.