LangVAE and LangSpace: Building and Probing for Language Model VAEs
作者: Danilo S. Carvalho, Yingji Zhang, Harriet Unsworth, André Freitas
分类: cs.CL, cs.AI
发布日期: 2025-03-29
💡 一句话要点
LangVAE:构建并探究基于预训练语言模型的变分自编码器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 变分自编码器 预训练语言模型 文本表示 解耦表示 潜在空间 文本生成 LangSpace
📋 核心要点
- 现有方法难以将大型语言模型的知识有效压缩并解耦为可解释的表示。
- LangVAE框架通过模块化构建VAE,利用预训练LLM的知识,实现更紧凑和解耦的文本表示。
- 实验表明,不同编码器-解码器组合在泛化和解耦方面存在差异,为文本表示的理解提供新视角。
📝 摘要(中文)
本文提出LangVAE,一个新颖的框架,用于在预训练大型语言模型(LLM)之上模块化地构建变分自编码器(VAE)。这种语言模型VAE可以将预训练组件的知识编码成更紧凑和语义解耦的表示。通过这种方式获得的表示可以使用LangVAE的配套框架LangSpace进行分析:LangSpace实现了一系列探测方法,例如向量遍历和插值、解耦度量和聚类可视化。LangVAE和LangSpace提供了一种灵活、高效和可扩展的方式来构建和分析文本表示,并可以简单地集成HuggingFace Hub上可用的模型。此外,我们进行了一系列实验,使用不同的编码器和解码器组合,以及带注释的输入,揭示了关于泛化和解耦的架构系列和大小之间的广泛交互。我们的发现展示了一个有希望的框架,用于系统化文本表示的实验和理解。
🔬 方法详解
问题定义:论文旨在解决如何有效利用预训练语言模型(LLM)的知识,构建具有良好解耦性的文本表示的问题。现有方法通常难以将LLM的知识压缩成紧凑的向量表示,并且缺乏对表示中不同语义维度的有效控制和理解。此外,缺乏系统性的工具来分析和探究这些表示的性质。
核心思路:论文的核心思路是构建一个基于LLM的变分自编码器(VAE),称为LangVAE。通过VAE的编码器将文本输入映射到潜在空间,然后使用解码器从潜在空间重建文本。VAE的训练目标是最小化重建误差,同时鼓励潜在空间的分布接近先验分布(通常是高斯分布)。这种设计使得潜在空间能够捕获输入文本的语义信息,并且具有良好的结构。
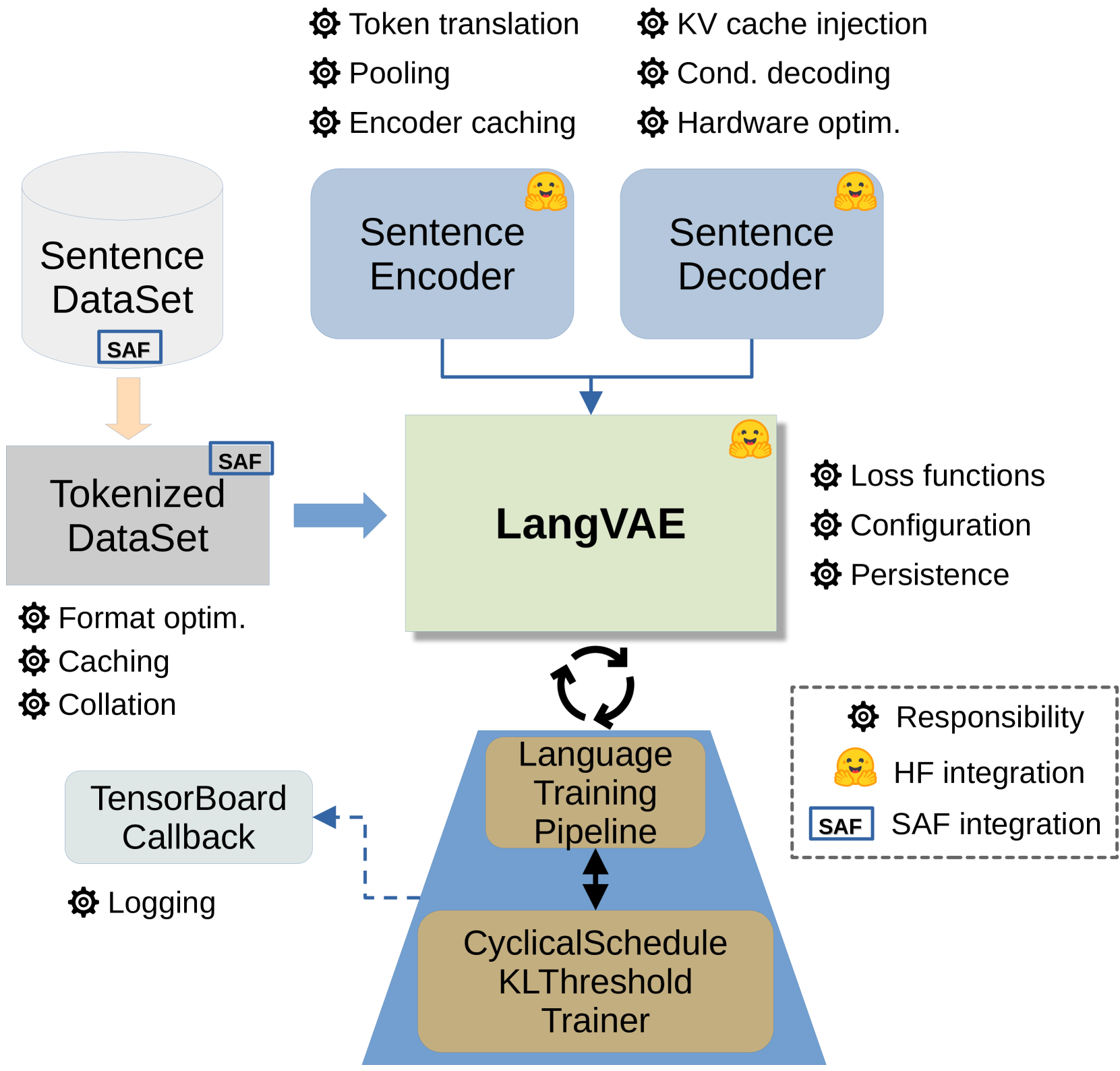
技术框架:LangVAE框架包含以下主要模块:1) 编码器:将文本输入编码为潜在向量,可以使用不同的预训练LLM作为编码器。2) 解码器:从潜在向量重建文本,同样可以使用不同的预训练LLM作为解码器。3) 变分推断:使用变分推断方法学习潜在空间的分布。4) LangSpace:一个配套的分析框架,用于探测和可视化潜在空间,包括向量遍历、插值、解耦度量和聚类可视化。
关键创新:LangVAE的关键创新在于其模块化的设计,允许灵活地组合不同的预训练LLM作为编码器和解码器。此外,LangSpace框架提供了一套完整的工具,用于分析和理解潜在空间的性质,例如解耦性和可解释性。这种系统化的方法使得研究人员能够更好地理解文本表示的内在结构。
关键设计:LangVAE的关键设计包括:1) 使用预训练LLM作为编码器和解码器,以利用LLM的强大语言建模能力。2) 使用变分推断方法,学习具有良好结构的潜在空间。3) 设计LangSpace框架,提供多种探测和可视化工具,用于分析潜在空间的性质。具体的参数设置和损失函数取决于所使用的LLM和变分推断方法,但通常包括重建损失和KL散度损失。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LangVAE能够学习到具有良好解耦性的文本表示。通过改变编码器和解码器的组合,可以观察到不同的泛化和解耦性能。LangSpace框架提供的工具能够有效地分析潜在空间的结构,例如通过向量遍历可以改变文本的风格或主题。这些结果验证了LangVAE框架的有效性和灵活性。
🎯 应用场景
LangVAE可应用于文本生成、文本风格迁移、语义搜索、文本聚类等领域。通过控制潜在空间的向量,可以生成具有特定属性的文本。该研究有助于更好地理解和利用大型语言模型的知识,并为自然语言处理任务提供更有效的文本表示方法。未来可应用于对话系统、内容创作和智能客服等场景。
📄 摘要(原文)
We present LangVAE, a novel framework for modular construction of variational autoencoders (VAEs) on top of pre-trained large language models (LLMs). Such language model VAEs can encode the knowledge of their pre-trained components into more compact and semantically disentangled representations. The representations obtained in this way can be analysed with the LangVAE companion framework: LangSpace, which implements a collection of probing methods, such as vector traversal and interpolation, disentanglement measures, and cluster visualisations. LangVAE and LangSpace offer a flexible, efficient and scalable way of building and analysing textual representations, with simple integration for models available on the HuggingFace Hub. Additionally, we conducted a set of experiments with different encoder and decoder combinations, as well as annotated inputs, revealing a wide range of interactions across architectural families and sizes w.r.t. generalisation and disentanglement. Our findings demonstrate a promising framework for systematising the experimentation and understanding of textual representations.