Beyond Contrastive Learning: Synthetic Data Enables List-wise Training with Multiple Levels of Relevance
作者: Reza Esfandiarpoor, George Zerveas, Ruochen Zhang, Macton Mgonzo, Carsten Eickhoff, Stephen H. Bach
分类: cs.IR, cs.CL, cs.LG
发布日期: 2025-03-29 (更新: 2025-11-04)
备注: Findings of the EMNLP 2025
💡 一句话要点
利用合成数据进行列表式训练,实现多层次相关性建模,超越对比学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 信息检索 合成数据 对比学习 多层次相关性 Wasserstein距离
📋 核心要点
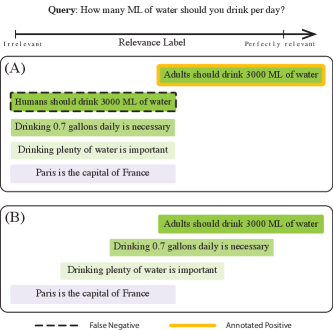
- 传统对比学习在信息检索中忽略了文档相关性的细微差别,将所有非相关文档视为同等负例。
- 该论文提出利用大型语言模型生成具有多层次相关性的合成数据,并使用Wasserstein距离作为损失函数。
- 实验表明,该方法在MS MARCO和BEIR基准上显著优于传统对比学习,并提高了模型的鲁棒性。
📝 摘要(中文)
尽管合成数据已经改变了信息检索(IR)流程的多个方面,但主要的训练范式仍然是:使用二元相关标签的对比学习,其中使用InfoNCE损失将一个正文档与几个负文档进行比较。这种目标函数将所有未明确注释为相关的文档都视为同等负面,而忽略了它们实际的相关程度,从而错失了对排序有用的细微差别。为了克服这个限制,本文放弃了真实文档和标注,而是使用大型语言模型直接生成合成文档,这些文档根据几个不同的相关级别回答MS MARCO查询。我们还提出使用Wasserstein距离作为一种更有效的损失函数,用于训练具有分级相关标签的基于Transformer的检索器。在MS MARCO和BEIR基准上的实验表明,我们提出的方法大大优于使用InfoNCE的传统训练。在不使用任何真实文档的情况下,我们的方法显著改进了自监督检索器,并且与使用真实数据的对比学习相比,对分布偏移更具鲁棒性。我们的方法还成功地将现有的真实数据集成到合成排序上下文中,进一步提高了性能。总的来说,我们表明,生成多层次排序上下文是比仅生成标准正负文档更好的IR合成数据生成方法。
🔬 方法详解
问题定义:现有信息检索模型的训练主要依赖对比学习,使用二元相关标签。这种方法将所有未标注为相关的文档视为同等负例,忽略了文档之间细微的相关性差异,导致排序性能受限。此外,真实数据的标注成本高昂,且容易受到标注偏差的影响。
核心思路:本文的核心思路是利用大型语言模型(LLM)生成合成数据,这些数据包含多个层次的相关性标签。通过在这些合成数据上训练检索模型,可以更好地学习文档之间的相关性排序,从而提高检索性能。同时,使用合成数据可以避免对真实数据的依赖,降低标注成本,并提高模型的泛化能力。
技术框架:该方法主要包含两个阶段:1) 合成数据生成阶段:使用大型语言模型(如GPT-3)根据给定的查询生成多个文档,并为每个文档分配一个相关性等级(例如,完美相关、高度相关、中等相关、不相关)。2) 模型训练阶段:使用生成的合成数据训练一个基于Transformer的检索模型。为了更好地利用多层次的相关性信息,本文提出使用Wasserstein距离作为损失函数。
关键创新:该方法最重要的创新点在于利用合成数据进行多层次相关性建模。与传统的对比学习方法相比,该方法可以更好地学习文档之间的相关性排序,从而提高检索性能。此外,使用Wasserstein距离作为损失函数可以更好地处理多层次的相关性标签,并提高模型的训练效率。
关键设计:在合成数据生成阶段,需要仔细设计提示词(prompt)来引导LLM生成具有不同相关性等级的文档。在模型训练阶段,需要选择合适的Transformer架构和超参数,并调整Wasserstein距离的权重。此外,还可以将真实数据与合成数据结合起来进行训练,以进一步提高模型的性能。
🖼️ 关键图片


📊 实验亮点
该方法在MS MARCO和BEIR基准测试中取得了显著的性能提升。例如,在MS MARCO数据集上,该方法在不使用任何真实文档的情况下,仍然能够显著超越传统的对比学习方法。此外,该方法还表现出更强的鲁棒性,能够更好地应对分布偏移问题。通过将合成数据与真实数据结合,可以进一步提高模型的性能。
🎯 应用场景
该研究成果可应用于各种信息检索场景,例如网页搜索、问答系统、推荐系统等。通过利用合成数据进行多层次相关性建模,可以提高检索系统的准确性和用户体验。此外,该方法还可以用于冷启动场景,即在缺乏真实数据的情况下,快速构建一个可用的检索系统。该研究对未来信息检索技术的发展具有重要的指导意义。
📄 摘要(原文)
Although synthetic data has changed various aspects of information retrieval (IR) pipelines, the main training paradigm remains: contrastive learning with binary relevance labels, where one positive document is compared against several negatives using the InfoNCE loss. This objective treats all documents that are not explicitly annotated as relevant on an equally negative footing, regardless of their actual degree of relevance, thus missing subtle nuances useful for ranking. To overcome this limitation, in this work, we forgo real documents and annotations and use large language models to directly generate synthetic documents that answer the MS MARCO queries according to several different levels of relevance. We also propose using Wasserstein distance as a more effective loss function for training transformer-based retrievers with graduated relevance labels. Our experiments on MS MARCO and BEIR benchmark show that our proposed approach outperforms conventional training with InfoNCE by a large margin. Without using any real documents, our method significantly improves self-supervised retrievers and is more robust to distribution shift compared to contrastive learning using real data. Our method also successfully integrates existing real data into the synthetic ranking context, further boosting the performance. Overall, we show that generating multi-level ranking contexts is a better approach to synthetic data generation for IR than just generating the standard positive and negative documents.