RECALL-MM: A Multimodal Dataset of Consumer Product Recalls for Risk Analysis using Computational Methods and Large Language Models
作者: Diana Bolanos, Mohammadmehdi Ataei, Daniele Grandi, Kosa Goucher-Lambert
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-29
💡 一句话要点
构建RECALL-MM多模态数据集,利用计算方法和LLM进行消费品召回风险分析。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 产品召回 风险分析 多模态数据 大型语言模型 工程设计 消费者安全 数据驱动 聚类分析
📋 核心要点
- 现有产品召回数据潜力未被充分挖掘,缺乏有效的数据驱动方法来指导更安全的产品设计。
- 构建多模态数据集RECALL-MM,结合历史召回数据和LLM,实现数据驱动的风险评估和预测。
- 通过案例研究验证了数据集在识别产品风险和指导安全设计方面的有效性,并探索了LLM在风险预测中的潜力。
📝 摘要(中文)
本研究旨在利用产品召回数据提升工程设计过程中的风险评估。我们从美国消费品安全委员会(CPSC)的召回数据库中整理数据,构建了一个多模态数据集RECALL-MM,用于数据驱动的风险评估,并使用生成方法进行扩充。数据集中的模式突显了改进安全措施的关键领域。我们通过交互式聚类图展示了分析结果,该聚类图基于召回描述和产品名称将所有召回嵌入到一个共享的潜在空间中。通过三个案例研究,我们展示了该数据集在识别产品风险和指导更安全设计决策方面的效用。其中一个案例研究利用大型语言模型(LLM)仅根据产品图像预测潜在危害,结果表明该模型能够利用视觉上下文识别风险因素,并与历史召回数据高度一致。该研究旨在弥合历史召回数据与未来产品安全之间的差距,为更安全的工程设计提供可扩展的、数据驱动的方法。
🔬 方法详解
问题定义:论文旨在解决产品设计过程中风险评估不足的问题,现有方法难以充分利用历史召回数据,缺乏有效的数据驱动工具来指导更安全的设计决策。尤其是在产品设计的早期阶段,设计师往往难以预见潜在的风险和危害。
核心思路:论文的核心思路是构建一个包含多模态信息(文本描述和图像)的产品召回数据集,并结合计算方法和大型语言模型,实现对产品风险的预测和分析。通过将历史召回数据与新的产品设计理念相结合,帮助设计师主动规避潜在的风险。
技术框架:整体框架包括数据收集与整理、数据集构建、交互式聚类分析和基于LLM的风险预测。首先,从CPSC召回数据库中收集产品召回数据,并整理成结构化的数据集RECALL-MM。然后,利用召回描述和产品名称构建交互式聚类图,将所有召回嵌入到一个共享的潜在空间中。最后,使用LLM根据产品图像预测潜在危害。
关键创新:该研究的关键创新在于构建了一个多模态的产品召回数据集RECALL-MM,并将其与大型语言模型相结合,实现了对产品风险的预测。与传统的风险评估方法相比,该方法更加数据驱动,能够充分利用历史召回数据,并能够根据产品图像进行风险预测。
关键设计:数据集RECALL-MM包含产品召回的文本描述、产品名称和产品图像等多模态信息。在构建交互式聚类图时,使用了词嵌入技术将文本信息转换为向量表示。在使用LLM进行风险预测时,使用了预训练的图像分类模型,并针对产品召回风险预测任务进行了微调。具体的损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


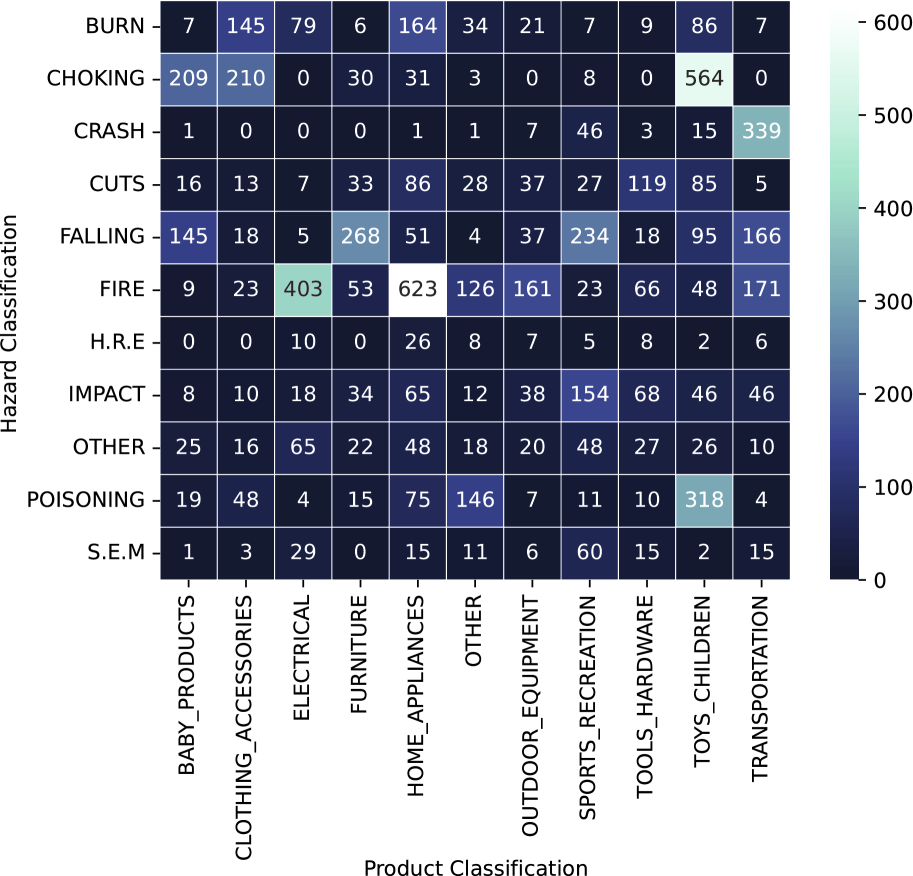
📊 实验亮点
研究通过案例分析展示了RECALL-MM数据集在识别产品风险和指导安全设计方面的有效性。例如,通过LLM对产品图像进行风险预测,结果与历史召回数据高度一致,表明该模型能够有效识别潜在的风险因素。虽然论文中没有给出具体的性能数据和提升幅度,但案例研究的结果表明该方法具有很高的应用价值。
🎯 应用场景
该研究成果可应用于产品设计、风险管理和消费者安全等领域。设计师可以利用RECALL-MM数据集和相关工具,在产品设计的早期阶段识别潜在的风险,并采取相应的措施来提高产品的安全性。监管机构可以利用该数据集来监测产品的安全状况,并及时发布召回信息。消费者可以通过该数据集了解产品的潜在风险,并做出更明智的购买决策。
📄 摘要(原文)
Product recalls provide valuable insights into potential risks and hazards within the engineering design process, yet their full potential remains underutilized. In this study, we curate data from the United States Consumer Product Safety Commission (CPSC) recalls database to develop a multimodal dataset, RECALL-MM, that informs data-driven risk assessment using historical information, and augment it using generative methods. Patterns in the dataset highlight specific areas where improved safety measures could have significant impact. We extend our analysis by demonstrating interactive clustering maps that embed all recalls into a shared latent space based on recall descriptions and product names. Leveraging these data-driven tools, we explore three case studies to demonstrate the dataset's utility in identifying product risks and guiding safer design decisions. The first two case studies illustrate how designers can visualize patterns across recalled products and situate new product ideas within the broader recall landscape to proactively anticipate hazards. In the third case study, we extend our approach by employing a large language model (LLM) to predict potential hazards based solely on product images. This demonstrates the model's ability to leverage visual context to identify risk factors, revealing strong alignment with historical recall data across many hazard categories. However, the analysis also highlights areas where hazard prediction remains challenging, underscoring the importance of risk awareness throughout the design process. Collectively, this work aims to bridge the gap between historical recall data and future product safety, presenting a scalable, data-driven approach to safer engineering design.