Token-Driven GammaTune: Adaptive Calibration for Enhanced Speculative Decoding
作者: Aayush Gautam, Susav Shrestha, Narasimha Reddy
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-28 (更新: 2025-06-04)
备注: 6 pages, 2 figures, 1 table
💡 一句话要点
提出GammaTune以解决大语言模型推理效率问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 大语言模型 自适应算法 效率优化 性能提升
📋 核心要点
- 现有的推测解码方法在选择最佳推测长度时存在效率低下和计算资源浪费的问题。
- 论文提出的GammaTune和GammaTune+算法通过动态调整推测长度,基于令牌接受率进行自适应优化。
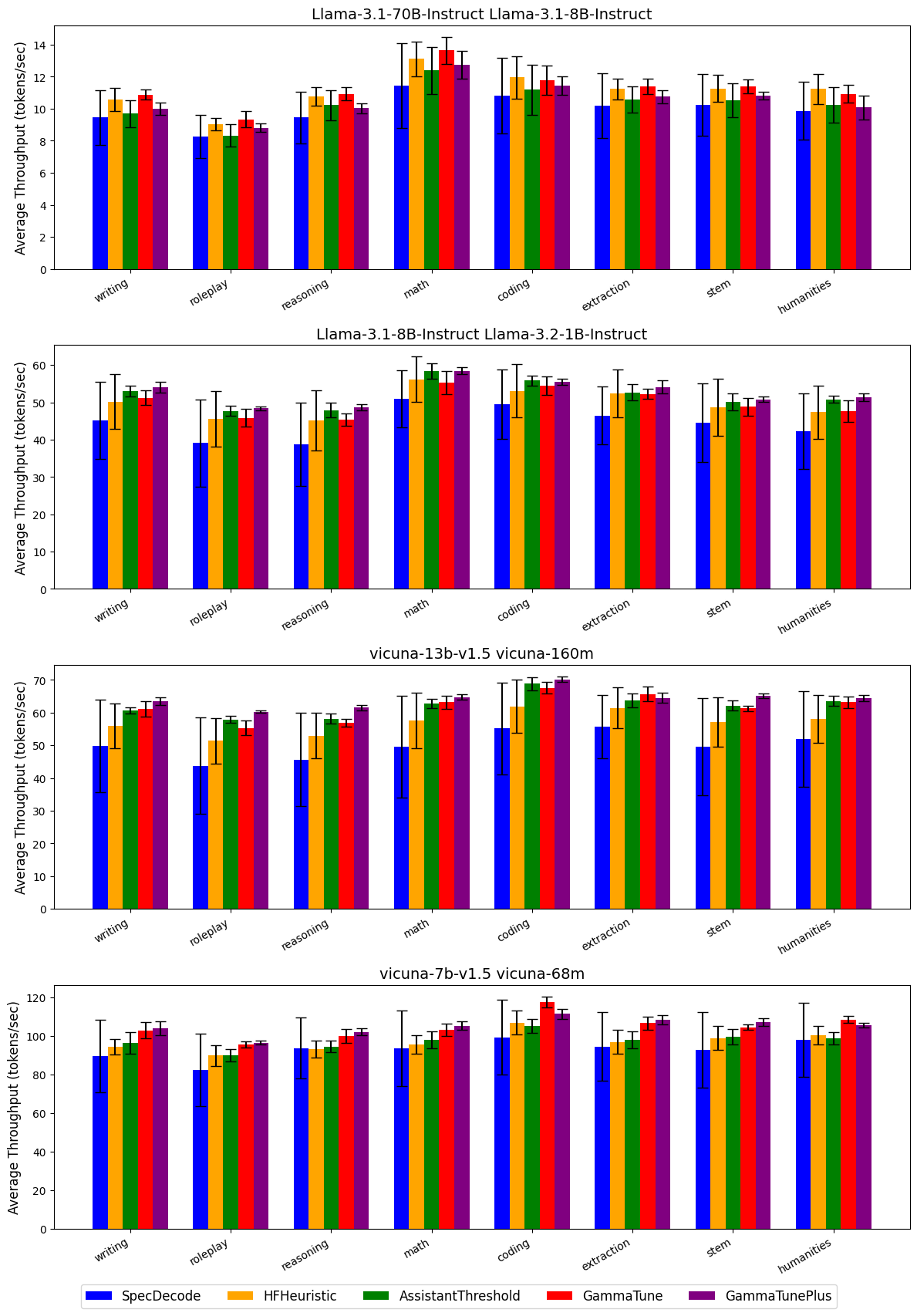
- 实验结果显示,GammaTune和GammaTune+在推理速度上分别实现了15%和16%的加速,且性能波动更小。
📝 摘要(中文)
论文提出了GammaTune和GammaTune+,这两种无训练的自适应算法通过基于启发式的切换机制动态调整推测长度,以提高大语言模型的推理效率。现有的推测解码方法在选择最佳推测长度时面临挑战,可能导致计算资源的浪费。通过在SpecBench上对多个任务和模型对进行评估,GammaTune和GammaTune+在推理速度上分别实现了15%(±5%)和16%(±3%)的平均加速,同时减少了性能方差,展现出其在实际应用中的稳健性和高效性。
🔬 方法详解
问题定义:论文旨在解决大语言模型推理中的推测解码效率问题。现有方法在选择推测长度时,往往无法平衡速度和计算资源的使用,导致性能不稳定和资源浪费。
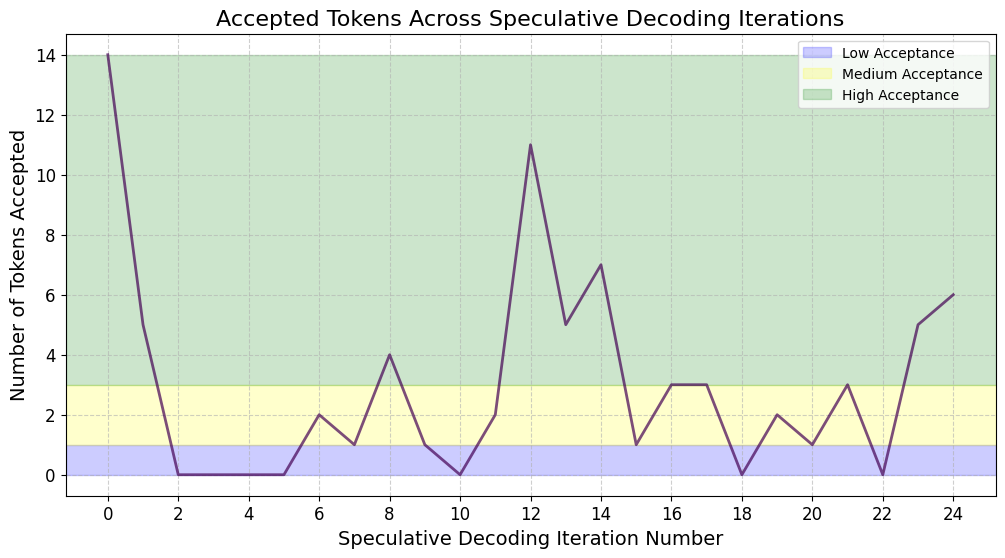
核心思路:论文提出的GammaTune和GammaTune+算法通过动态调整推测长度,利用令牌接受率来优化推测过程,避免了固定长度推测带来的低效问题。
技术框架:整体架构包括两个主要模块:小型草稿模型用于生成初步令牌,随后由大型目标模型进行验证。算法通过启发式切换机制实时调整推测长度,以适应不同任务和模型对的需求。
关键创新:最重要的创新在于无训练的自适应算法设计,使得推测长度能够根据实时反馈进行调整,从而显著提高推理效率。这一方法与传统的固定长度推测解码方法本质上不同,后者无法灵活应对不同的输入情况。
关键设计:在参数设置上,GammaTune和GammaTune+采用了基于令牌接受率的启发式策略,确保在推测过程中能够快速响应并调整推测长度。此外,算法设计中未依赖于额外的训练过程,增强了其在实际应用中的适用性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GammaTune和GammaTune+在SpecBench上分别实现了15%(±5%)和16%(±3%)的推理速度提升,相较于其他启发式方法和固定长度推测解码,表现出更低的性能方差,显示出其在实际应用中的优势。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和机器翻译等需要高效推理的大语言模型场景。通过提高推理速度和降低计算资源消耗,GammaTune和GammaTune+能够在实际部署中提供更好的用户体验,推动相关技术的广泛应用。
📄 摘要(原文)
Speculative decoding accelerates large language model (LLM) inference by using a smaller draft model to propose tokens, which are then verified by a larger target model. However, selecting an optimal speculation length is critical for maximizing speedup while minimizing wasted computation. We introduce \textit{GammaTune} and \textit{GammaTune+}, training-free adaptive algorithms that dynamically adjust speculation length based on token acceptance rates using a heuristic-based switching mechanism. Evaluated on SpecBench across multiple tasks and model pairs, our method outperforms other heuristic-based approaches and fixed-length speculative decoding, achieving an average speedup of 15\% ($\pm$5\%) with \textit{GammaTune} and 16\% ($\pm$3\%) with \textit{GammaTune+}, while reducing performance variance. This makes \textit{GammaTune} a robust and efficient solution for real-world deployment.