Learning to Reason for Long-Form Story Generation
作者: Alexander Gurung, Mirella Lapata
分类: cs.CL
发布日期: 2025-03-28 (更新: 2025-09-08)
💡 一句话要点
提出基于可验证奖励的强化学习方法,用于提升长文本故事生成的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本生成 故事生成 强化学习 推理 可验证奖励
📋 核心要点
- 现有长文本故事生成方法依赖手工设计的提示,缺乏自动学习和优化推理能力。
- 提出基于可验证奖励的强化学习框架,通过下一章节预测任务学习故事推理。
- 实验表明,该方法生成的章节在人工评估中优于未训练和监督微调的基线方法,尤其在科幻和奇幻类型中。
📝 摘要(中文)
生成高质量的长篇故事需要多种技能,包括跟踪情节和角色发展,以及保持一致且引人入胜的风格。由于难以获取带标签的数据集和精确的质量评估,大多数使用大型语言模型(LLMs)进行长篇故事生成的工作都依赖于手工设计的提示技术来诱导类似作者的行为。这是一个手动过程,高度依赖于特定的故事生成任务。受RL与可验证奖励在数学和编码等领域取得成功的启发,我们提出了一个通用的故事生成任务(下一章节预测)和一个奖励公式(通过完成可能性改进进行验证的奖励),这使我们能够使用未标记的书籍数据集作为推理的学习信号。我们学习推理故事的浓缩信息,并为下一章生成详细的计划。我们的推理通过它帮助故事生成器创建的章节进行评估,并与未训练和监督微调(SFT)基线进行比较。成对的人工判断表明,我们学习到的推理产生的章节在几乎所有指标上都更受欢迎,并且在科幻和奇幻类型中效果更明显。
🔬 方法详解
问题定义:论文旨在解决长文本故事生成中,大型语言模型难以有效推理和规划故事发展的问题。现有方法主要依赖人工设计的提示工程,缺乏自动学习和优化推理能力,导致生成的故事质量不稳定,难以保持长期一致性和吸引力。
核心思路:论文的核心思路是利用强化学习,通过可验证的奖励信号,引导模型学习故事的推理过程。具体来说,模型学习根据故事的上下文信息,生成下一章节的详细计划,并根据该计划生成实际的章节内容。通过奖励函数鼓励模型生成更符合故事发展逻辑,更受读者欢迎的章节。
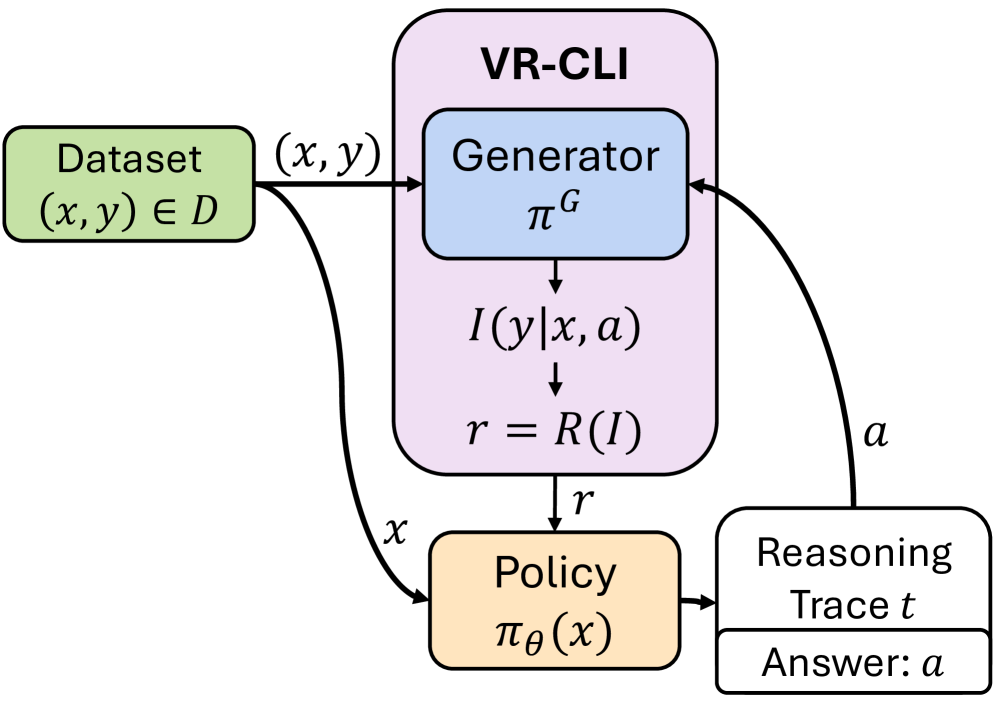
技术框架:整体框架包含以下几个主要模块:1) 故事编码器:用于将已有的故事内容编码成向量表示。2) 推理模块:根据故事编码,生成下一章节的计划。3) 故事生成器:根据推理模块生成的计划,生成下一章节的文本内容。4) 奖励函数:基于完成可能性改进(Completion Likelihood Improvement)来评估生成章节的质量,并作为强化学习的奖励信号。整个框架通过强化学习算法进行训练,目标是最大化累积奖励。
关键创新:最重要的创新点在于提出了基于完成可能性改进的可验证奖励函数。该奖励函数不需要人工标注数据,而是利用大型语言模型自身的生成能力,评估生成章节与已有故事的连贯性和一致性。这种自监督的奖励方式,使得模型可以从大量的未标注书籍数据中学习,从而提升故事推理能力。
关键设计:关键设计包括:1) 推理模块的网络结构:可以使用Transformer等序列模型,学习故事上下文的表示,并生成下一章节的计划。2) 奖励函数的具体形式:可以使用语言模型的困惑度(Perplexity)来衡量完成可能性,并计算生成章节前后困惑度的变化作为奖励。3) 强化学习算法的选择:可以使用PPO等策略梯度算法,优化推理模块的策略,使其生成更有利于故事发展的计划。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在下一章节预测任务中取得了显著的提升。通过人工评估,该方法生成的章节在连贯性、趣味性和整体质量上均优于未训练和监督微调的基线方法。尤其在科幻和奇幻类型的故事生成中,提升效果更为明显,表明该方法能够更好地捕捉不同类型故事的特点。
🎯 应用场景
该研究成果可应用于自动化故事创作、游戏剧情生成、虚拟角色对话生成等领域。通过提升长文本生成模型的推理能力,可以创作出更具吸引力、更符合逻辑的故事内容,为用户提供更丰富的娱乐体验。此外,该方法还可以应用于教育领域,辅助学生进行写作练习,提高写作水平。
📄 摘要(原文)
Generating high-quality stories spanning thousands of tokens requires competency across a variety of skills, from tracking plot and character arcs to keeping a consistent and engaging style. Due to the difficulty of sourcing labeled datasets and precise quality measurements, most work using large language models (LLMs) for long-form story generation uses combinations of hand-designed prompting techniques to elicit author-like behavior. This is a manual process that is highly dependent on the specific story-generation task. Motivated by the recent success of applying RL with Verifiable Rewards to domains like math and coding, we propose a general story-generation task (Next-Chapter Prediction) and a reward formulation (Verified Rewards via Completion Likelihood Improvement) that allows us to use an unlabeled book dataset as a learning signal for reasoning. We learn to reason over a story's condensed information and generate a detailed plan for the next chapter. Our reasoning is evaluated via the chapters it helps a story-generator create, and compared against non-trained and supervised finetuning (SFT) baselines. Pairwise human judgments reveal the chapters our learned reasoning produces are preferred across almost all metrics, and the effect is more pronounced in Scifi and Fantasy genres.