Supposedly Equivalent Facts That Aren't? Entity Frequency in Pre-training Induces Asymmetry in LLMs
作者: Yuan He, Bailan He, Zifeng Ding, Alisia Lupidi, Yuqicheng Zhu, Shuo Chen, Caiqi Zhang, Jiaoyan Chen, Yunpu Ma, Volker Tresp, Ian Horrocks
分类: cs.CL
发布日期: 2025-03-28 (更新: 2025-07-12)
备注: Accepted at COLM 2025
💡 一句话要点
揭示LLM中实体频率偏差导致逻辑等价事实识别的非对称性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉 预训练数据 实体频率 知识表示
📋 核心要点
- 大型语言模型容易产生幻觉,现有研究主要关注何时发生,但缺乏对深层原因的解释。
- 该研究揭示了预训练数据中实体频率的偏差,导致LLM在识别逻辑等价事实时出现不对称性。
- 实验表明,实体频率影响LLM对事实的识别,高频主语/低频宾语的事实更容易被识别。
📝 摘要(中文)
理解和缓解大型语言模型(LLM)中的幻觉对于确保可靠的内容生成至关重要。以往的研究主要集中在LLM何时产生幻觉,而本文解释了“为什么”,并将模型行为直接与构成其先验知识的预训练数据联系起来。具体而言,我们证明了逻辑上等价的事实识别中存在不对称性,这可归因于实体作为主语与宾语出现的频率差异。由于大多数预训练数据集不可访问,我们利用完全开源的OLMo系列,通过索引其Dolma数据集来估计实体频率。使用来自Wikidata5M的关系事实(表示为三元组),我们构建了探测数据集来分离这种效应。我们的实验表明,具有高频主语和低频宾语的事实比其逆事实更容易被识别,尽管它们在逻辑上是等价的。在低频到高频设置中,这种模式会反转,并且当两个实体都是高频时,不会出现统计上显著的不对称性。这些发现突出了预训练数据在塑造模型预测中的重要作用,并为推断封闭或部分封闭LLM中预训练数据的特征提供了见解。
🔬 方法详解
问题定义:大型语言模型在生成内容时会产生幻觉,即生成不真实或与事实相悖的信息。现有方法主要关注于何时以及如何减少幻觉,但缺乏对幻觉产生的根本原因的深入理解,特别是预训练数据对模型认知的影响。该论文关注的问题是:预训练数据中实体频率的差异是否会导致LLM在识别逻辑等价的事实时产生偏差?
核心思路:该论文的核心思路是,预训练数据中实体作为主语和宾语出现的频率差异会影响LLM对事实的认知。具体来说,如果一个实体在预训练数据中经常作为主语出现,而另一个实体很少作为宾语出现,那么LLM可能更容易识别以高频实体为主语,低频实体为宾语的事实,即使其逻辑等价的逆事实也是正确的。这种不对称性源于LLM在预训练过程中学习到的先验知识。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 利用开源的OLMo系列及其Dolma数据集,通过索引来估计实体频率。2) 从Wikidata5M中提取关系事实,构建探测数据集,其中包含逻辑等价的事实三元组。3) 使用这些探测数据集来评估LLM对不同频率组合的事实的识别能力。4) 分析实验结果,验证实体频率与事实识别不对称性之间的关系。
关键创新:该论文的关键创新在于:1) 首次揭示了预训练数据中实体频率的偏差会导致LLM在识别逻辑等价的事实时产生不对称性。2) 提供了一种利用开源数据集来推断封闭或部分封闭LLM中预训练数据特征的方法。3) 通过实验验证了实体频率对LLM事实认知的显著影响。
关键设计:该研究的关键设计包括:1) 使用Wikidata5M中的关系事实构建探测数据集,确保事实的逻辑等价性。2) 通过OLMo的Dolma数据集估计实体频率,为分析提供数据基础。3) 通过控制实体频率的组合(高频-低频、低频-高频、高频-高频),系统地研究了实体频率对事实识别的影响。4) 使用统计显著性检验来验证实验结果的可靠性。
🖼️ 关键图片

📊 实验亮点
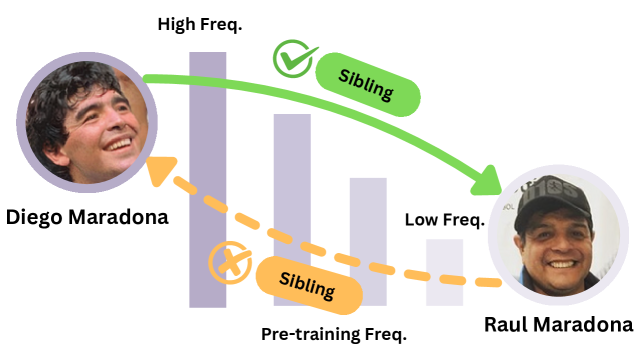
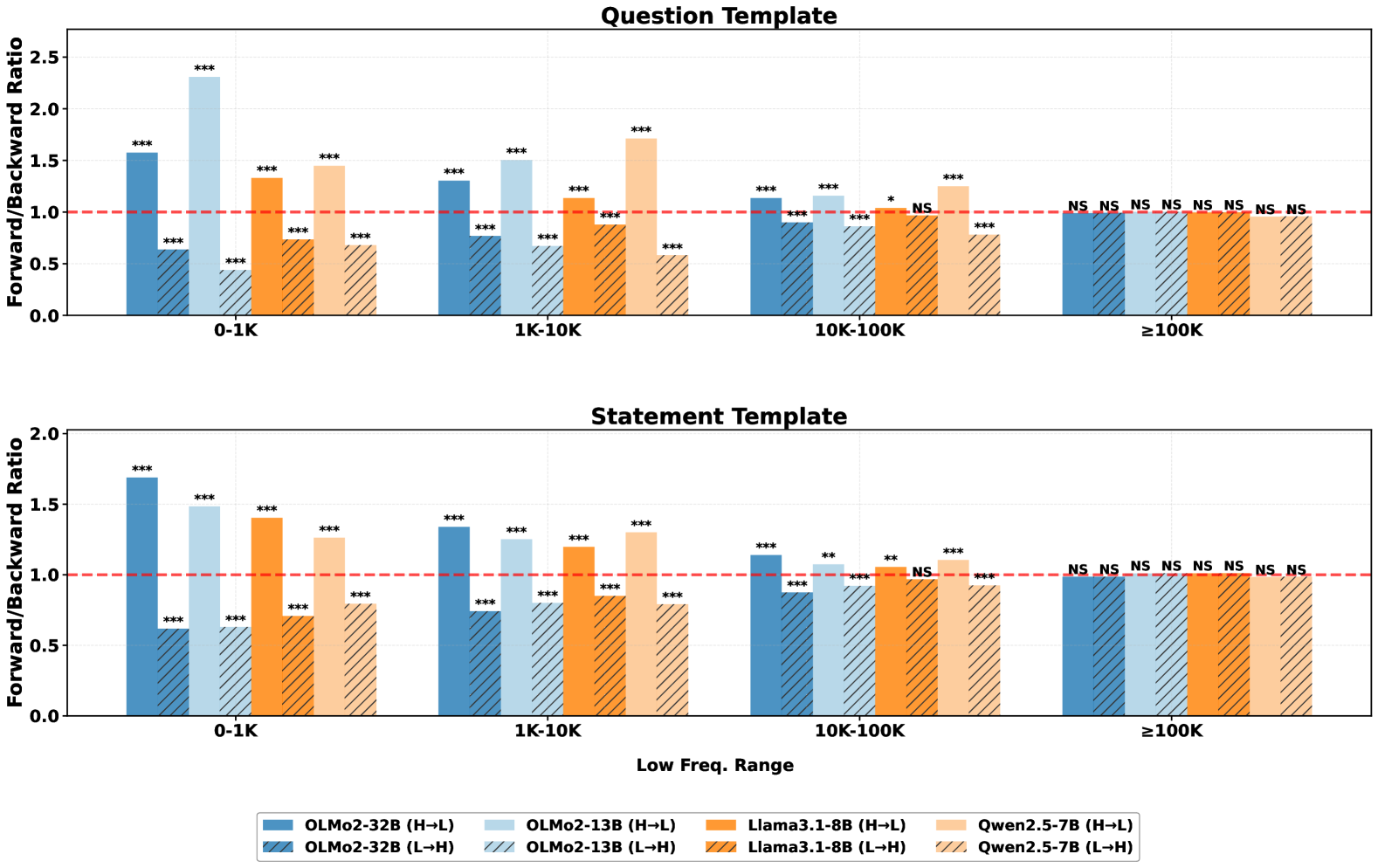
实验结果表明,当主语是高频实体而宾语是低频实体时,LLM更容易识别该事实,反之则不然。当主语和宾语都是高频实体时,这种不对称性消失。这些发现证实了预训练数据中实体频率的偏差对LLM事实认知的影响。
🎯 应用场景
该研究的成果可以应用于提升大型语言模型的可靠性和可信度。通过了解预训练数据中的偏差,可以设计更有效的训练策略,减少模型产生幻觉的可能性。此外,该方法可以用于分析和评估现有LLM的知识结构,并为开发更公平、更准确的AI系统提供指导。
📄 摘要(原文)
Understanding and mitigating hallucinations in Large Language Models (LLMs) is crucial for ensuring reliable content generation. While previous research has primarily focused on "when" LLMs hallucinate, our work explains "why" and directly links model behaviour to the pre-training data that forms their prior knowledge. Specifically, we demonstrate that an asymmetry exists in the recognition of logically equivalent facts, which can be attributed to frequency discrepancies of entities appearing as subjects versus objects. Given that most pre-training datasets are inaccessible, we leverage the fully open-source OLMo series by indexing its Dolma dataset to estimate entity frequencies. Using relational facts (represented as triples) from Wikidata5M, we construct probing datasets to isolate this effect. Our experiments reveal that facts with a high-frequency subject and a low-frequency object are better recognised than their inverse, despite their logical equivalence. The pattern reverses in low-to-high frequency settings, and no statistically significant asymmetry emerges when both entities are high-frequency. These findings highlight the influential role of pre-training data in shaping model predictions and provide insights for inferring the characteristics of pre-training data in closed or partially closed LLMs.