Firm or Fickle? Evaluating Large Language Models Consistency in Sequential Interactions
作者: Yubo Li, Yidi Miao, Xueying Ding, Ramayya Krishnan, Rema Padman
分类: cs.CL, cs.AI
发布日期: 2025-03-28 (更新: 2025-06-05)
备注: 8 pages, 5 figures
期刊: Published at ACL 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出PWC指标、MT-Consistency基准和CARG框架,提升LLM在多轮交互中的一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 一致性评估 多轮对话 置信度感知 基准数据集
📋 核心要点
- 现有LLM在多轮交互中缺乏一致性,限制了其在高风险领域的应用。
- 提出PWC指标评估一致性,构建MT-Consistency基准测试模型,并设计CARG框架提升模型稳定性。
- 实验表明CARG框架在不牺牲准确性的前提下,显著提升了LLM响应的稳定性。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中表现出卓越的能力,但它们在高风险领域的部署需要在多轮用户交互中保持一致性和连贯性。本文提出了一个全面的框架,用于评估和提高LLM响应的一致性,做出了三个关键贡献。首先,我们引入了位置加权一致性(PWC)指标,旨在捕捉早期阶段稳定性的重要性和多轮交互中的恢复模式。其次,我们提出了MT-Consistency,这是一个精心策划的基准数据集,涵盖不同的领域和难度级别,专门用于评估LLM在各种具有挑战性的后续场景下的一致性。第三,我们引入了置信度感知响应生成(CARG)框架,该框架通过在生成过程中显式地整合内部模型置信度分数,显著提高了响应的稳定性。实验结果表明,CARG在不牺牲准确性的前提下显著提高了响应的稳定性,为在关键的现实世界部署中实现更可靠的LLM行为提供了一条切实可行的途径。
🔬 方法详解
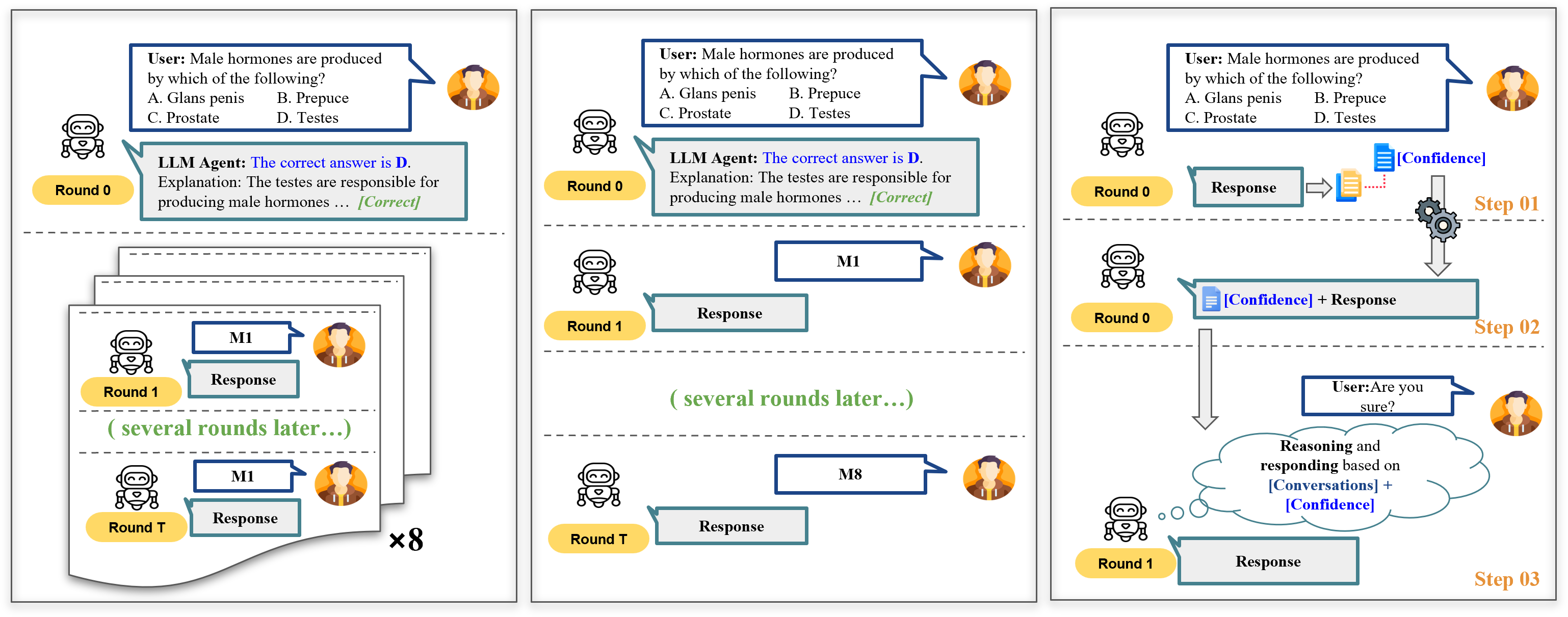
问题定义:论文旨在解决大型语言模型(LLM)在多轮对话中响应不一致的问题。现有的LLM在连续交互中可能会产生矛盾或不连贯的回答,这限制了它们在需要高度可靠性的应用场景中的部署,例如医疗诊断、法律咨询等。现有的评估方法难以全面捕捉LLM在多轮交互中的一致性表现,缺乏专门针对此问题的基准数据集。
核心思路:论文的核心思路是通过引入位置加权一致性(PWC)指标来更准确地评估LLM的一致性,并利用置信度感知响应生成(CARG)框架来提高LLM的响应稳定性。PWC指标考虑了对话历史中不同位置的重要性,CARG框架则利用模型自身的置信度信息来指导响应生成,避免产生不确定的或矛盾的回答。
技术框架:整体框架包含三个主要部分:1) 位置加权一致性(PWC)指标的定义;2) MT-Consistency基准数据集的构建;3) 置信度感知响应生成(CARG)框架的设计。PWC指标用于评估LLM在MT-Consistency数据集上的表现,CARG框架则用于提高LLM的响应一致性。该框架通过在生成过程中引入模型置信度,调整生成概率分布,从而产生更稳定的响应。
关键创新:论文的关键创新在于:1) 提出了位置加权一致性(PWC)指标,该指标能够更准确地评估LLM在多轮交互中的一致性,考虑了对话历史中不同位置的重要性;2) 构建了MT-Consistency基准数据集,该数据集专门用于评估LLM的一致性,包含了各种具有挑战性的后续场景;3) 提出了置信度感知响应生成(CARG)框架,该框架通过在生成过程中显式地整合内部模型置信度分数,显著提高了响应的稳定性。
关键设计:CARG框架的关键设计在于如何将模型置信度融入到响应生成过程中。具体来说,该框架利用模型在生成每个token时的概率分布来估计置信度。然后,根据置信度调整生成概率分布,使得模型更倾向于生成置信度高的token,从而避免产生不确定的或矛盾的回答。具体的调整方法未知,论文可能使用了温度系数或其他概率分布平滑技术。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CARG框架在MT-Consistency数据集上显著提高了LLM的响应稳定性,同时没有牺牲准确性。具体的性能提升数据未知,但论文强调CARG为在关键的现实世界部署中实现更可靠的LLM行为提供了一条切实可行的途径。与没有使用CARG框架的基线模型相比,使用了CARG框架的LLM在一致性指标上取得了显著提升。
🎯 应用场景
该研究成果可应用于需要高度可靠性和一致性的领域,如医疗诊断、法律咨询、金融服务等。通过提高LLM在多轮交互中的一致性,可以增强用户对LLM的信任,并减少因模型错误回答而造成的潜在风险。未来,该研究可以进一步扩展到其他类型的任务和模型,并探索更有效的置信度估计和利用方法。
📄 摘要(原文)
Large Language Models (LLMs) have shown remarkable capabilities across various tasks, but their deployment in high-stake domains requires consistent and coherent behavior across multiple rounds of user interaction. This paper introduces a comprehensive framework for evaluating and improving LLM response consistency, making three key contributions. Code and data are available at: https://github.com/yubol-bobo/MT-Consistency. First, we introduce Position-Weighted Consistency (PWC), a metric designed to capture both the importance of early-stage stability and recovery patterns in multi-turn interactions. Second, we present MT-Consistency, a carefully curated benchmark dataset spanning diverse domains and difficulty levels, specifically designed to evaluate LLM consistency under various challenging follow-up scenarios. Third, we introduce Confidence-Aware Response Generation (CARG), a framework that significantly improves response stability by explicitly integrating internal model confidence scores during the generation process. Experimental results demonstrate that CARG significantly improves response stability without sacrificing accuracy, offering a practical path toward more dependable LLM behavior in critical, real-world deployments.